Redis - 主从
数据库的发展总是从 单机 -> 主从 -> 分片集群
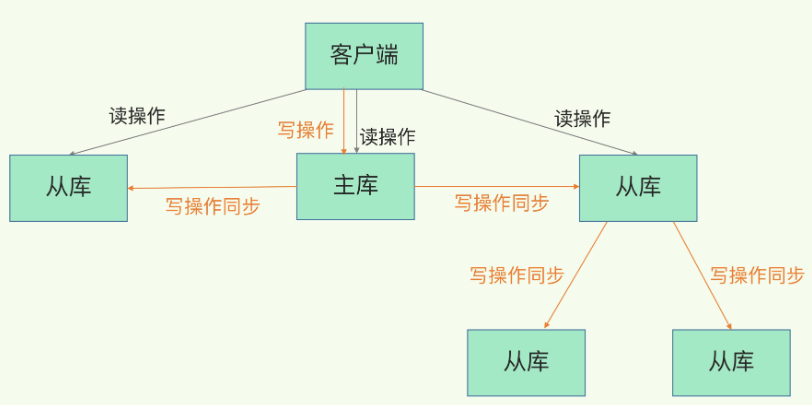
Redis的主从复制
从单机到主从的根本优势在于:
- 可实现读写分离,分摊读压力;某个从库用于做统计等后台功能
- 数据可靠,一份数据,多处拷贝,一台机器坏掉了,也不至于数据没了
- 服务可靠,主节点挂了不能写,可以从从节点选一个上来
主从 - 主从从
主节点需要负责生成RDB,并传输RDB给从节点。如果从库太多且都需要全量复制的话,主库会忙于fork子线程进行复制工作,传输RDB也会占用主库的网络带宽,为了分担这个压力,Redis可以使用主从级联模式,即让从库也去做一些复制工作同步数据到其他从库。
复制机制
第一次全量复制
- 在从节点上执行
replicaof xx.xx.xx.xx 6379命令后,会进行第一次的数据拷贝。首先从节点会发送命令psync slave_repl_offset给主节点,slave_repl_offset = -1 代表偏移量为-1即需要全量的数据。 - 主节点收到后,返回
FULLRESYNC{runID}{offset}给从节点,runID是redis实例启动后生成的该实例进程id(全局唯一),offset是发送的数据的起始偏移量。 - 主节点开始生成RDB。
- 主节点发送RDB文件给从节点,从节点清空现有数据并加载RDB。
- 主节点继续发送后续的写命令后的数据给从库。这个专门给从库同步数据的缓存写操作的buffer叫做replication buffer。
至此,主从就完成了第一次数据同步。

增量复制
为了避免网络断连导致的主从全量同步数据的问题(Redis 2.8之前),Redis也通过增量复制机制来提高效率。主库不仅有replication buffer 这个用于缓存发送给从库写命令的buffer,还有一个repl_backlog_buffer用于记录自己写到哪儿了。而从库,也有一个repl_backlog_buffer用于记录自己读到哪儿了。而主从库repl_backlog_buffer的偏移差也就是主从同步的延迟体现。正常情况下是基本一致的。
和MySQL的redo log一样, repl_backlog_buffer也是一个环形的缓冲区。当连接断开后,主库的repl buffer还在继续写,而从库的repl buffer就停止在断连前的位置。此时再重新连上后,从库会发送psync slave_repl_offset给主节点,主节点会把自己buffer位置到从库偏移量的之间的数据同步给从库。
环形缓冲区,那么就存在数据被覆盖的可能,一旦比如说断连时间太长,或者从库读取数据速度慢很多,就有可能发生,并最后导致主从数据的不一致。可以使用repl_backlog_size来调整缓冲区大小。经验值是 2 * (主库写入速度 * 操作数大小 - 网络传输速度 * 操作数大小)
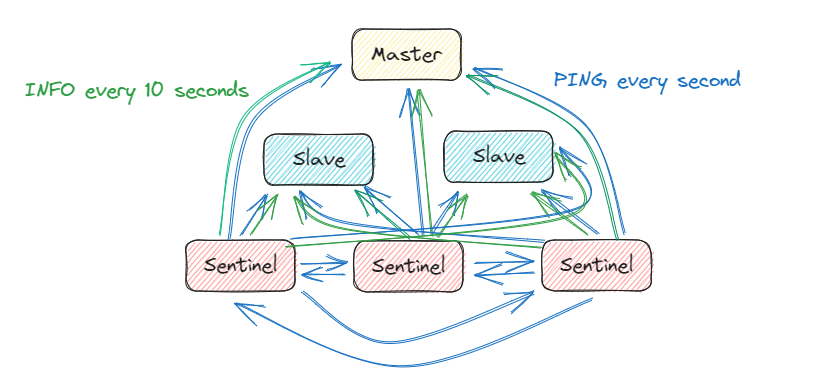
哨兵模式
Redis哨兵模式,即Redis Sentinel,最基础的部署方案是,一主,二从,三哨兵,如下图:
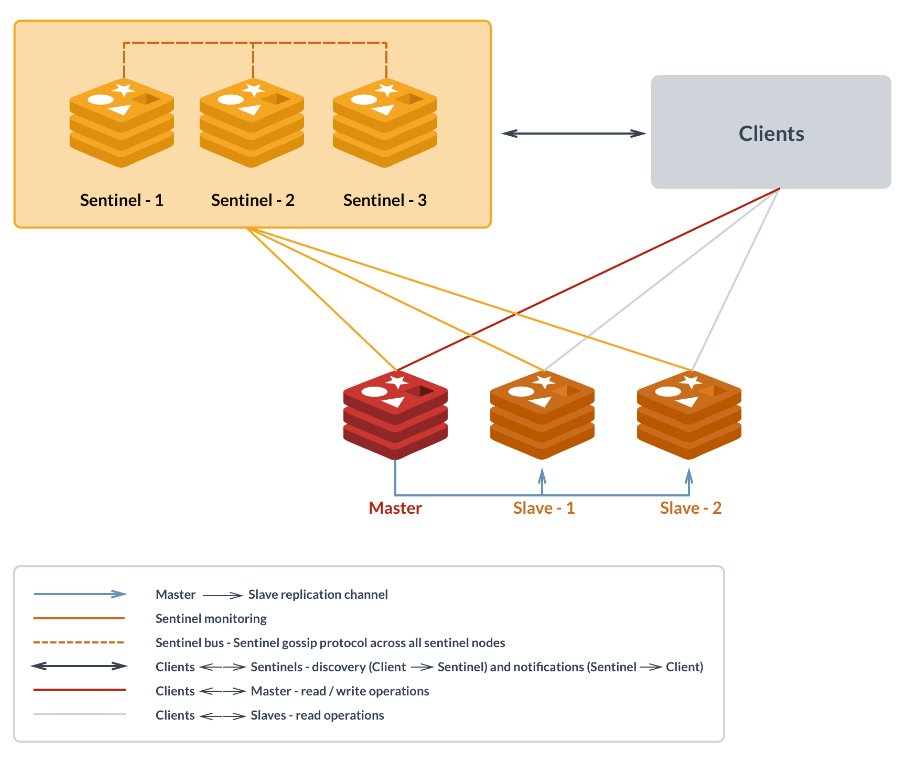
哨兵节点的存在只是为了监控主从节点的正常,所以他们一般有三个作用:
- 监控 : 定期给主从节点发ping,判断他们是健康的,且避免误判(3个哨兵就是为了避免误判)
- 选主 : 主节点不健康,这个时候,要根据共识协议选出Leader哨兵并进行主从切换(在Raft那章描述过,哨兵需要一个Leader来具体执行通知工作)。成为一个新的主节点的依据,依据大概是1.优先级,2.同步进度,3.ID小的
- 通知 : 新的主节点确定后,Leader哨兵还需要1.通知客户端主节点变了 2.通知各位从库主节点变了
通信
哨兵只需要连最开始的主节点,从节点也连主节点(replicaof xx), 利用Redis的Pub/Sub机制,哨兵把自己的ip端口发布到一个__sentinel__:hello频道上,其他哨兵订阅这个频道,那么哨兵们也都能“认识”其他哨兵小伙伴,建立连接进行通信了。
哨兵还通过向主库发送INFO命令来获取其他从库的ip端口等信息,并与从库建立连接。
哨兵和客户端的通信也是通过Pub/Sub机制,客户端可以从哨兵订阅消息,那么一旦换主了,哨兵发布消息,客户端就能感知到了。