Redis - 数据结构
Redis key-value结构组织
首先,Redis使用了一个全局哈希表来保存所有的键值对。这个全局哈希表,也就是一个存放哈希桶(entry)的数组。Redis可以用哈希算法算出某个key的哈希值,直接取到这个数组这个位置的元素,也就是O(1)的读写。每个entry包含了两到三个部分,一个是*key也就是指向键key的指针,一个*value指向值value的指针,一级有可能会有*next,当发生hash冲突时,使用链表存储值的下一个entry的位置指针。
冲突解决
上面提到了如果发生哈希冲突,会用一个链表的结构保存entry,一旦冲突变多势必影响读写性能,所以Redis会进行Rehash。Redis进行rehash的方式,是一开始就准备好两个数组h1, h2, h2为h1大小的两倍,使用h1的过程中,一旦h1元素多了,就将h1的内容拷贝到h2,然后释放h1。
为了保证rehash对读写业务影响尽可能小,Redis采用了渐进式rehash:开始rehash的时候,redis仍然正常处理客户端请求,但每处理一个请求就顺便从h1的第一个元素开始,把h1上的entries都拷贝到h2(这个思想倒是挺多地方有见到)。而且对于读的请求会先读h1没有就去读h2,而对于更新,删除操作也会对两个表进行,新增只会新增到h2,保证h1的数量会只减少不增。
Redis 数据结构
Redis有很多数据类型,这些数据类型都有一些元数据需要记录。Redis会封装这些数据在一个RedisObject里面,我们看看这个RedisObject长啥样:
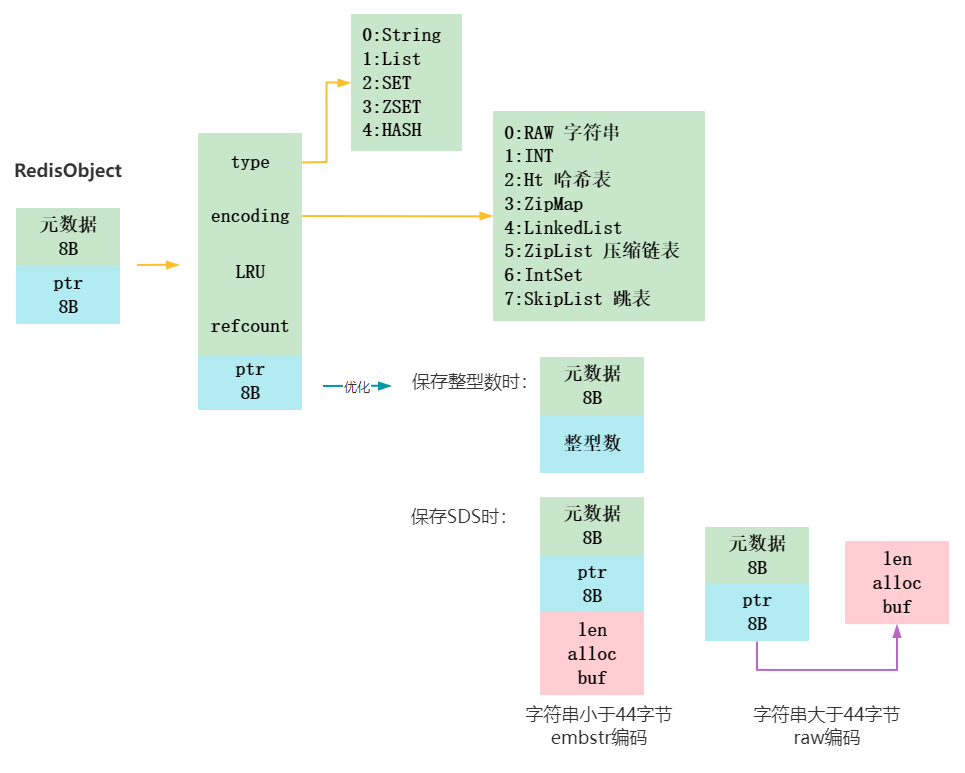
RedisObject主要包括了8字节的元数据和8字节的指针。元数据里有保存的数据类型,编码方式(底层实现),LRU即最后一次访问的时间,refcount引用计数。
RedisObject对整型数和简单字符串也做了优化,如果是整型数,*ptr就直接存整型数;如果是字符串,那么根据字符串大小(是否超过44字节)分为embstr编码方式,即ptr后紧凑地再分配一块内存存字符串,和raw方式,指针指向字符串。
应用数据结构
我们知道key就是一个字符串,而value,Redis提供了多种数据结构可以选择,包括常见的:String, List, Hash, Set, Sorted Set,和特殊的一些例如Bitmap,HyperLogLog和GEO。
GEO : 存储地理位置信细,可以计算坐标距离,获取指定范围内坐标集合。添加命令如:
GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
BitMap: 大量节省内存空间;使用场景:用户签到
HyperLogLog: 用来做基数统计的算法。输入元素数量体积很大时,计算基数所需要的空间是固定且很小的。
底层实现的数据结构
Redis底层实现主要依靠了SDS(Simple Dynamic String),双向链表,压缩列表,哈希表,跳表,整数数组,其和应用数据结构的关系如下表:
| 类型 | 编码方式 |
|---|---|
| string | raw/embstr/int |
| hash | hashtable/ziplist |
| list | linkedlist/ziplist/quicklist |
| set | hashtable/intset |
| zset | ziplist/skiplist |
压缩列表
压缩列表其实就是一个数组,只是比数组在表头多了三个字段zlbytes列表长度即该列表在内存中分配的大小,可以通过此值计算zlend位置;zltail代表列表尾部偏移量,可以通过此值直接获取列表尾部元素;zllenentry的个数,当该属性小于UNIT16_MAX(65535)时,该值就是列表包含的元素数目,大于时需要遍历整个列表才能得知;表尾多了一个字段zlend表示结束;entry代表压缩列表的各个节点,节点长度由节点保存的内容决定。如下图:

在压缩列表中,查找第一个和最后一个元素的时间复杂度是O(1),而其他的则是O(N)
对于每一个entry, 其数据结构包括previous_entry_length, encoding(当前元素的数据类型和长度), content(字节数组或者整数).

跳表
跳表就是在链表的基础上增加了多级索引,它的插入和查询时间复杂度为O(logN),所以我们也称跳表是实现了二分查找的链表。
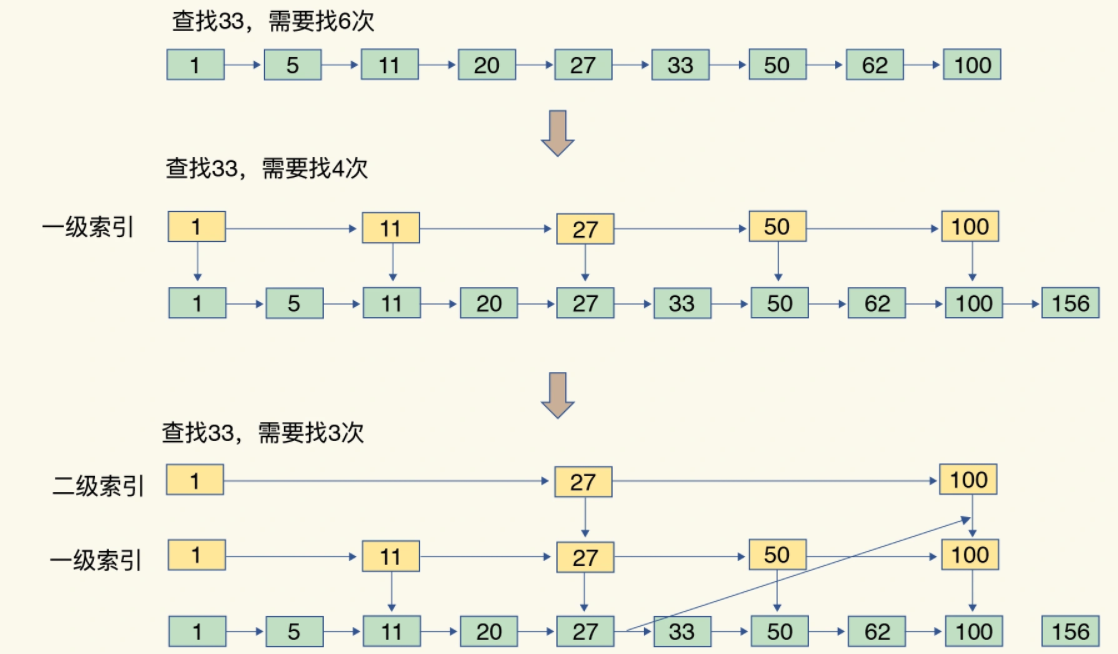
如果一个有序集合包含的元素数量比较多又或者元素是比较长的字符串时,Redis会使用跳表作为有序集合的底层实现。
可参考 https://blog.csdn.net/qq_36389060/article/details/123955761
- 为什么不适用红黑树
- 区间查找数据的操作红黑树没有跳表高,跳表可以O(LogN)定位区间起点,再从原始链表中顺序遍历
- 跳表更容易代码实现
- 为什么不用B+树
B+树的设计充分考虑了磁盘预读的功能,叶子节点存数据,非叶子节点存索引。每次读磁盘页会读一整个节点。Redis是内存读,不涉及IO。
问题
大Key如何解决
非字符串的 bigkey,不要使用 del 删除,使用 hscan、sscan、zscan 方式渐进式删除,同时要注意防止 bigkey 过期时间自动删除问题 (例如一个 200 万的 zset 设置 1 小时过期,会触发 del 操作,造成阻塞,而且该操作不会不出现在慢查询中 (latency 可查)),查找方法和删除方法
-
大Key: 简单key的value很大;
将一个对象拆分成几个key-value,降低单次操作的压力; 整存整取,用multiGet, -
hash,set,zset,list存储元素过多(超万);
-
一个集群存储了上亿的key key很多key本身的占用,还有
合并为hash
先预分桶,例如1000个,就把key的模%1000确定是哪个桶,再把原key + 桶id作为新key
如何进行故障转移
Redis sentinel
Redis cluster



