Redis - 内存淘汰策略
策略分类
内存写满了怎么办?Redis提供了以下几种内存淘汰的策略:
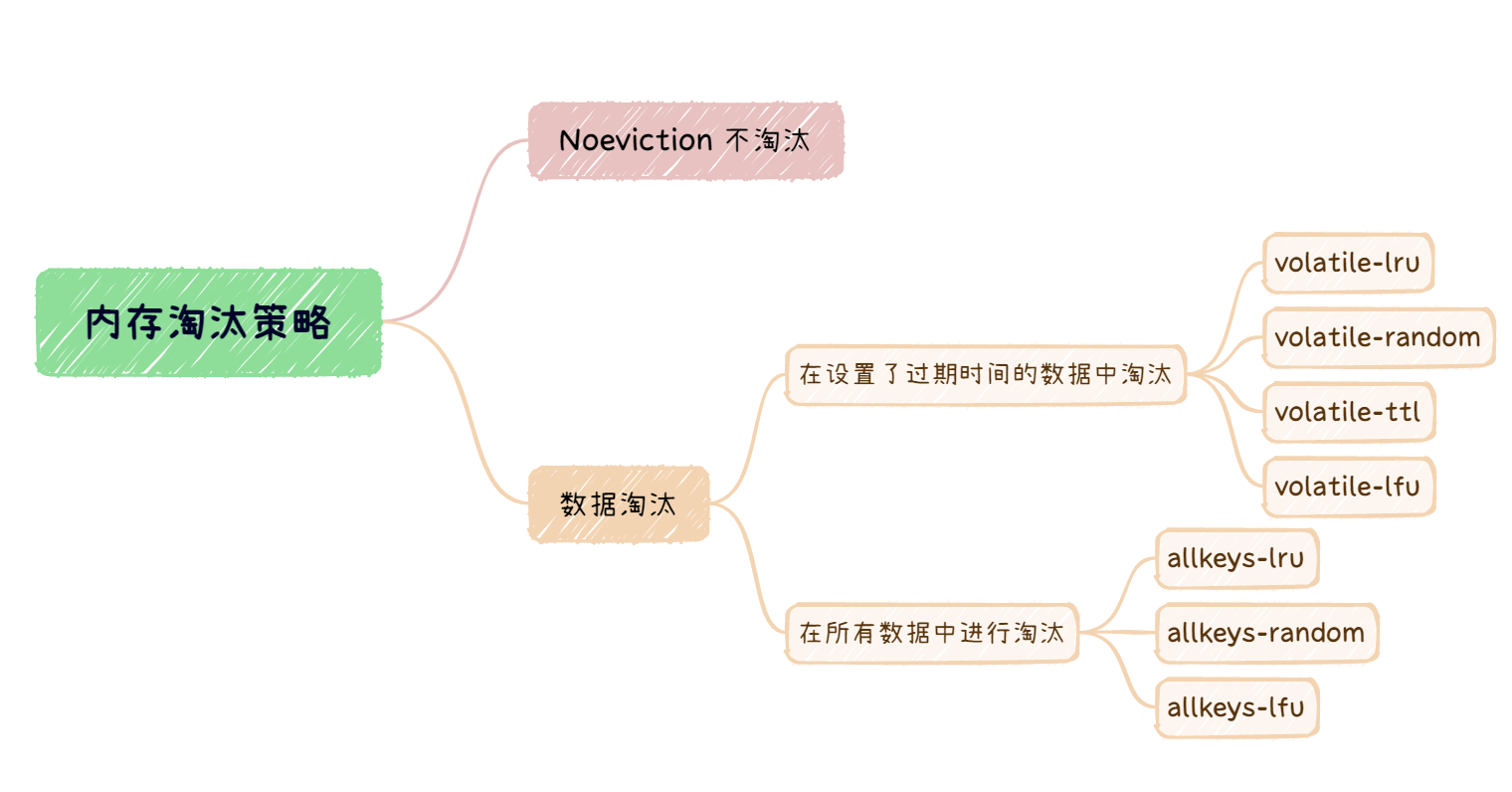
No eviction 不淘汰数据
即,内存写满后,再有写请求时,Redis直接返回错误,不会提供服务。这也是Redis3.0之后的默认淘汰策略。
淘汰数据
设置过期时间的数据中淘汰
💜 volatile-ttl :根据过期时间的先后进行删除,越早过期越早淘汰
💜 volatile-random : 在设置了过期时间的key中,随机删除
💜 volatile-lru : 在设置了过期时间的key中,使用LRU算法淘汰
💜 volatile-lfu : 在设置了过期时间的key中,使用LFU算法淘汰
全键中淘汰
💙 allkeys-random : 在所有key中,随机删除
💙 allkeys-lru : 使用LRU算法淘汰
💙 allkeys-lfu : 使用LFU算法淘汰
大名鼎鼎的LRU
LRU 即 Least Recently Used, 越是最近被访问的越会被保留,越早以前访问的,会被淘汰。其实在MySQL Innodb内存管理部分,就已经讲过LRU了:🚪传送门
算法实现
LRU在算法实际实现时,需要用链表来管理所有缓存数据,会有额外的空间开销以及大量数据被访问时,移动数据在链表位置的性能消耗,会降低Redis的性能。所以Redis做了简化的LRU,键值数据对结构的RedisObject中Lru字段记录了最近一次访问的时间戳,当需要做淘汰数据时,第一次淘汰,Redis会随机选出一个数据集合,集合大小可由参数maxmemory-samples配置,在这个集合中比较他们lru字段的大小,然后把最小的淘汰。后面淘汰,会挑选lru字段小于之前集合最小值的数据进入集合,达到集合配置大小时,进行淘汰最小的lru字段值的数据。
大名鼎鼎的LFU
在MySQL Innodb内存管理章提到,如果有全表扫描等操作,那么LRU机制会使得大部分热点数据失效,所以引入了分区(young,old)的LRU来避免。Redis避免这个问题的做法,在4.0之后增加了LFU的淘汰策略。LRU是访问一次就把该数据提到前面,而LFU是访问一次就用计数器给次数加一,然后根据次数大小比较,淘汰次数小的。自己写一个LFU的leetcode🚪传送门。
算法实现
Redis实现LFU策略时,把原来24bit大小的lru字段拆成了两部分:
- ldt 前16bit表示时间戳
- counter 后8bit表示数据访问次数
由于8bit只能记录最大次数255,所以redis做了一个优化的计数规则,想想是你你会怎么做这个(一个放缩)?Redis缩放的代码实现:
double r = (double)rand()/RAND_MAX;
...
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
baseval即为计数器当前值,配置项lfu_log_factor一般取10就行了。
同时,也会存在一部分数据在某个时间段内访问次数非常多,之后就不再访问的情况。所以Redis设计了一个counter值的衰减机制,通过lfu_decay_time来配置。
参考资料:redis 官网



