操作系统 - 进程与线程
进程和线程
🧩起源
最开始的计算机是由程序员将写好程序的闪存卡插进机器,芯片读取闪存卡的指令,一条一条执行完后就关机——单任务的模型。而后来,人们用计算机进行办公,聊天等,机器执行的程序会随时会被切换,为了支持这种机制,人们设计了进程和线程。
🎂资源分配
操作系统要考虑分配资源,主要是三大资源:CPU计算资源、内存资源和文件资源。早期的OS设计中没有线程,资源都是分配给进程,多个进程通过分时技术交替执行,但是这样做会导致一个应用常常需要开多个进程,才能并发地做事情(并发:concurrent,并不是同一时刻同时执行,而是一段时间内执行多个任务,看起来就是同时执行的,比如响应用户输入和图形渲染)。于是有了线程,仅仅分配CPU的计算资源。现代操作系统都是直接调度线程。操作系统根据进程来分配各种资源,根据线程来进行CPU计算任务的调度。
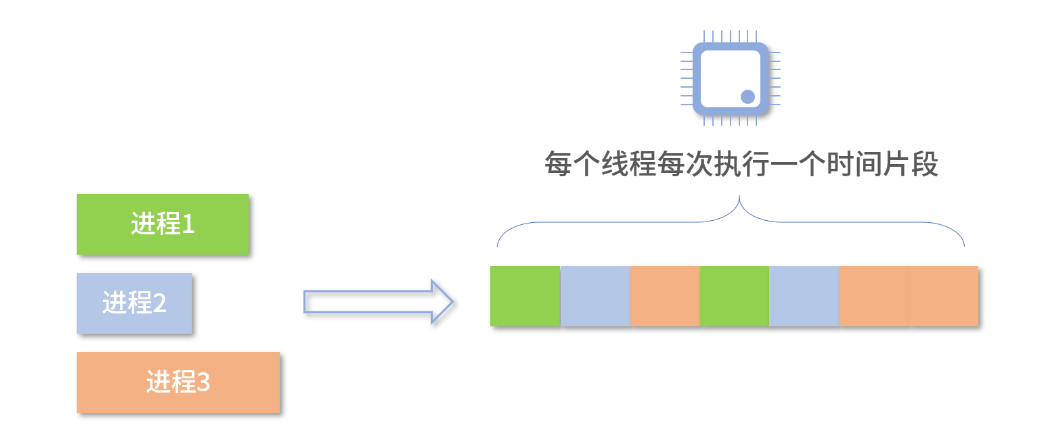
🌴中断
线程在执行任务的时候,有时会等待磁盘数据,等待网络IO等,此时就会进入阻塞状态,要等待事情做好了,通过中断通知CPU,操作系统再把这个阻塞状态置为就绪状态,重新排队。
✨硬中断
硬中断由外部设备(例如:磁盘,网卡,键盘,时钟)产生,用来通知操作系统外设状态变化。
时钟中断: 一种硬中断,用于定期打断 CPU 执行的线程,以便切换给其他线程以得到执行机会。
硬中断的处理流程如下:
- 1、外设 将中断请求发送给中断控制器;
- 2、中断控制器 根据中断优先级,有序地将中断传递给 CPU;
- 3、CPU 终止执行当前程序流,将 CPU 所有寄存器的数值保存到栈中;
- 4、CPU 根据中断向量,从中断向量表中查找中断处理程序的入口地址,执行中断处理程序;
- 5、CPU 恢复寄存器中的数值,返回原程序流停止位置继续执行。
✨软中断
软中断是一条 CPU 指令,由当前正在运行的进程产生。
软中断模拟了硬中断的处理过程:
- 1、无
- 2、无
- 3、CPU 终止执行当前程序流,将 CPU 所有寄存器的数值保存到栈中;
- 4、CPU 根据中断向量,从中断向量表中查找中断处理程序的入口地址,执行中断处理程序;
- 5、CPU 恢复寄存器中的数值,返回原程序流停止位置继续执行。
🎨线程切换
- 当操作系统发现线程需要切换了,会发送一个中断信号给CPU(软中断)
- CPU停止执行当前的程序,操作系统将CPU所有寄存器的数值保存到栈中
- CPU根据中断向量,从中断向量表查找中断程序的入口地址,执行该地址保存的指令(中断处理程序)
- 操作系统执行调度程序,决定下一个要执行的线程
🚀进程的创建
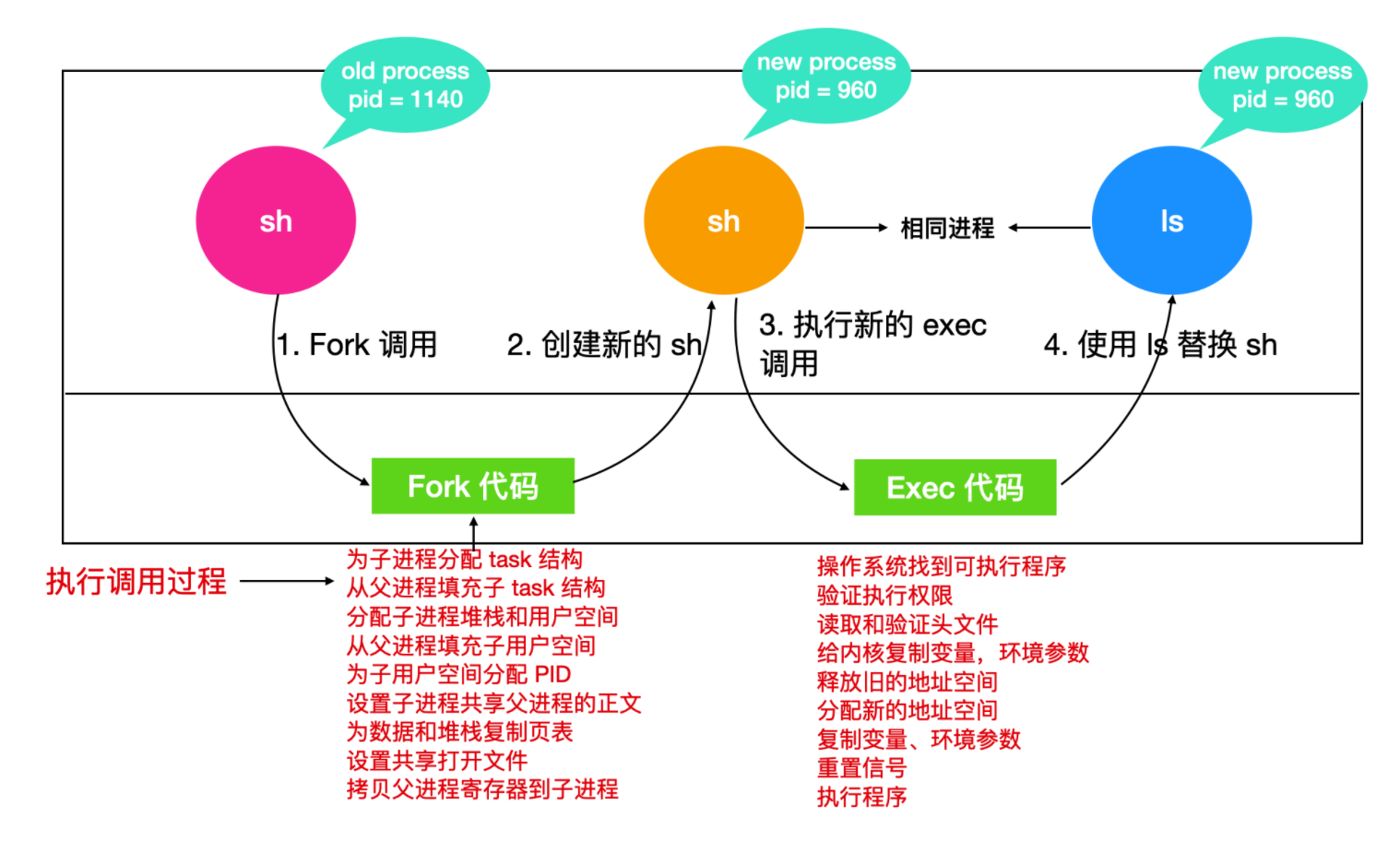
操作系统提供fork()指令进行进程的创建,返回一个非零值(PID, 进程标识符,Process Identifier),调用fork函数的进程被称作父进程,创建出来的进程被称为子进程,子进程的所有状态和父进程一致,且有自己的地址空间,他们相互独立,即若父进程修改了一些变量,子进程感知不到这些变化;但他们仍能共享相同的文件,如果在 fork 之前,父进程已经打开了某个文件,那么 fork 后,父进程和子进程仍然共享这个打开的文件。对共享文件的修改会对父进程和子进程同时可见。
第一次调用fork的进程被称作原始进程,一个原始进程可以生成一颗继承树,如下图:
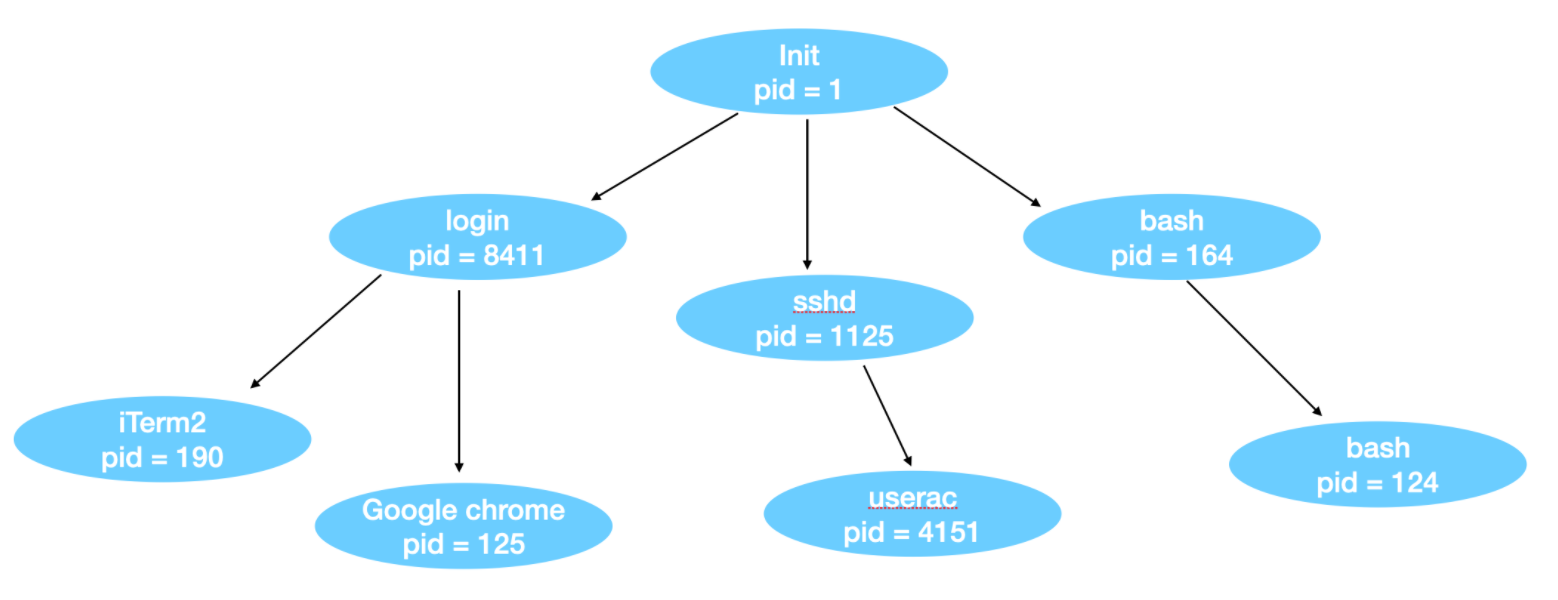
Linux进程
在 Linux 内核结构中,进程会被表示为 任务,通过结构体 structure 来创建。内核会将所有进程的任务结构组成为一个双向链表。PID 能够直接被映射称为进程的任务结构所在的地址,从而不需要遍历双向链表直接访问。对于每个进程来说,在内存中都会有一个 task_struct 进程描述符与之对应。进程描述符包含了内核管理进程所有有用的信息,包括 调度参数、打开文件描述符等等。进程描述符从进程创建开始就一直存在于内核堆栈中。
进程描述符可以归为下面这几类:
调度参数(scheduling parameters):进程优先级、最近消耗 CPU 的时间、最近睡眠时间一起决定了下一个需要运行的进程内存映像(memory image):我们上面说到,进程映像是执行程序时所需要的可执行文件,它由数据和代码组成。进程映像包含以下内容:
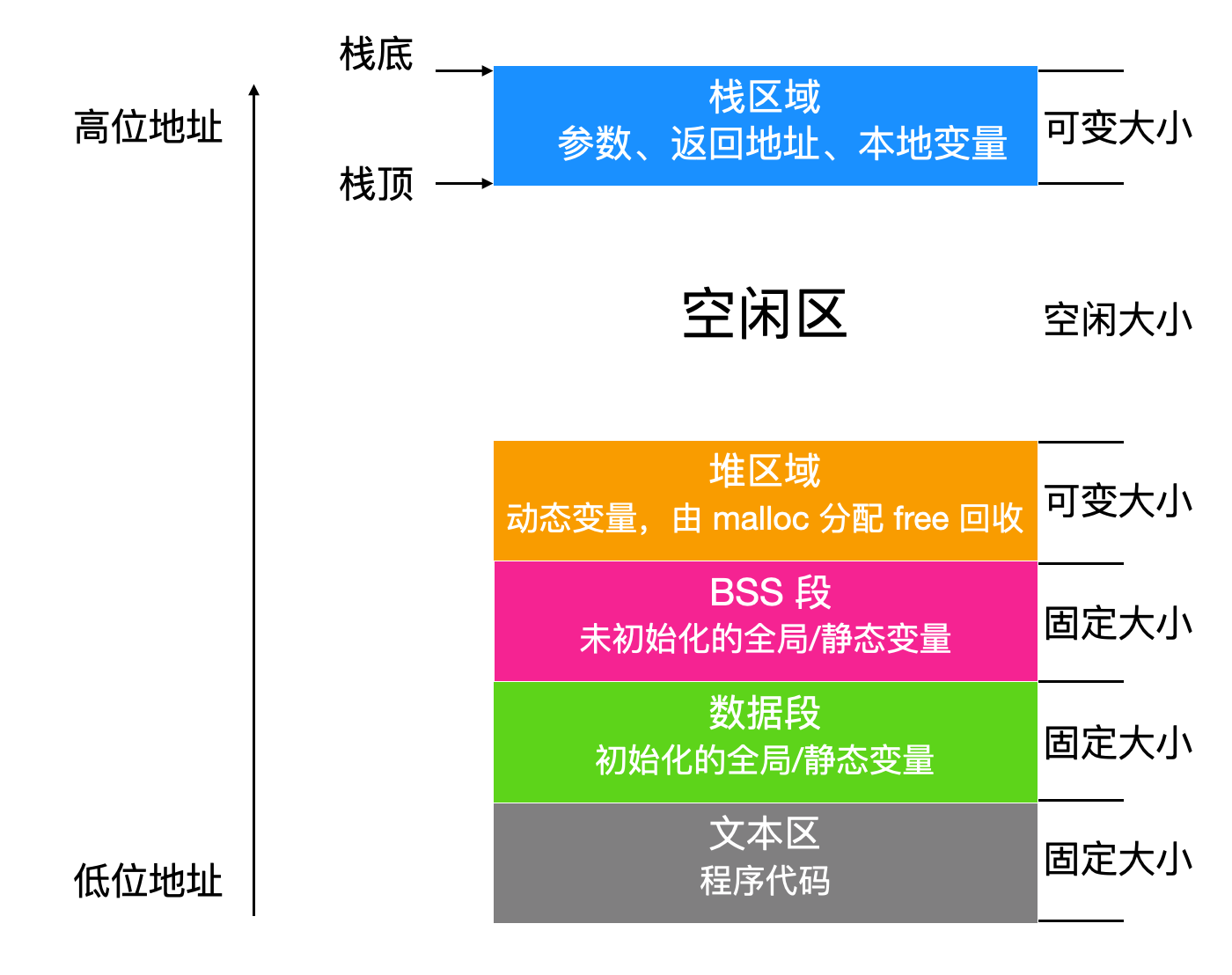
信号(signals):显示哪些信号被捕获、哪些信号被执行寄存器:当发生内核陷入 (trap) 时,寄存器的内容会被保存下来。系统调用状态(system call state):当前系统调用的信息,包括参数和结果文件描述符表(file descriptor table):有关文件描述符的系统被调用时,文件描述符作为索引在文件描述符表中定位相关文件的 i-node 数据结构统计数据(accounting):记录用户、进程占用系统 CPU 时间表的指针,一些操作系统还保存进程最多占用的 CPU 时间、进程拥有的最大堆栈空间、进程可以消耗的页面数等。内核堆栈(kernel stack):进程的内核部分可以使用的固定堆栈其他: 当前进程状态、事件等待时间、距离警报的超时时间、PID、父进程的 PID 以及用户标识符等
创建进程的过程:为子进程开辟一块新的用户空间的进程描述符,然后从父进程复制大量的内容。为这个子进程分配一个 PID,设置其内存映射,赋予它访问父进程文件的权限,注册并启动。
例如,用户输出 ls,shell 会调用 fork 函数复制一个新进程,shell 进程会调用 exec 函数用可执行文件 ls 的内容覆盖它的内存。
系统调度
应用执行程序总是在CPU计算的高峰和IO处理的高峰之间交替。
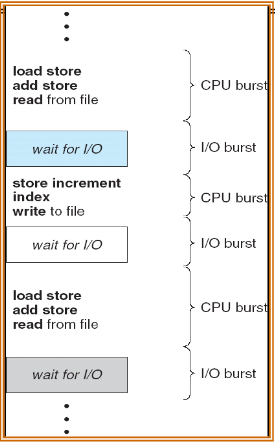
系统调度的单位
通常是以线程作为系统调度的单位。切换线程的开销远小于切换进程的开销:
- 切换线程: 保存/转储一些寄存器
- 切换进程: 改变地址空间,expensive & disrupts caching
调度算法的评估标准
- 最小响应时间(Minimize Response Time)
响应时间是用户看到的时间,即用户从提交任务,到任务完全执行完所需要的时间。 - 最大吞吐量(Maximize Throughput)
每秒能处理最多的任务。提高吞吐量的两个方面:1.减小其他开销(overhead, 如上下文切换 context-switching);2.高效使用硬件资源(如CPU, disk, memory等) - 公平性
CPU资源能在不同用户程序之间以相同的方式被享用;一般来说,更好的平均响应时间往往需要系统更不公平:Trade-off between fairness and avg response time。
通用调度算法
FCFS First Come First Served
也叫做FIFO or Run until done; 即先到先做,直到完成(线程阻塞)。会导致车队效应(Convoy effect),即当小任务排在大任务之后的时候,很多小任务很久都得不到执行,导致平均等待时间和平均响应时间都很大。
👍 简单
👎 小任务会被大任务阻塞
Round Robin
每个任务都获取一小块CPU的时间片,一般是10-100ms。当时间片(time quantum q)用完了,该任务会被抢占(Preemption),然后被移动到队尾去等待下一次分配时间片。
- q 很大的时候,RR趋近于FCFS
- q 特别小的时候,趋近于交错执行
- q 的取值需要大到一定程度能够在上下文切换导致的开销和平均响应时间之间的综合考虑下取得一个较好的结果。
目前的时间片的取值大部分是在10ms-100ms,而上下文的开销在0.1ms-1ms,大概1%的开销能在接受范围内。
👍 对于短小的任务更友好,比较公平
👎 对于大型任务的上下文开销不可小觑
RR的实现,需要依赖时钟中断和一些同步。
Strict Priority
严格优先级调度算法。每个优先级都有一个等待队列,总是先执行高优先级的任务,相同优先级的队列里的任务使用RR来调度。这会带来的问题有:1. 饥饿,低优先级的任务阻塞在高优先级之后。2. 死锁,如果高优先级的任务需要低优先级的任务释放锁,导致死锁。解决方式————动态优先级,在基础优先级的前提下,根据交互程度,锁,burst behaviour等等,对优先级进行启发式(heuristics)的调整。
SJF & SRTF
SJF 最短任务优先(Shortest job first)和 SRTF 最短剩余执行时间优先(Shortest remaining time first)。SRTF 是 SJF 的抢占版,即如果正在执行的任务剩余完成时间比新来的任务长,就先去执行新任务。 这些方式会使得avg response time尽可能地小。SRTF总是至少比SJF的表现更好,所以我们考虑SRTF。SRTF在有很多小任务的情况下也会导致饥饿的发生,即大任务得不到执行。
👍 对avg response time的优化
👎 很难预知一个任务需要多久时间执行
👎 不公平
为了预知任务的执行模式,时间等,可以引入一些预测算法,如Kalman filters等
Lottery Schedule
给每个线程一些tickets,优先级越高给的越多,但至少给一个,每个CPU时间片,随机选一个ticket执行
Linux优先级
Linux 系统会给每个线程分配一个 nice 值,这个值代表了优先级的概念,nice值越高,任务的优先级越低(It is nice to others~)。nice 值默认值是 0 ,但是可以通过系统调用 nice 值来修改。修改值的范围从 -20 - +19。nice 值决定了线程的静态优先级。一般系统管理员的 nice 值会比一般线程的优先级高,它的范围是 -20 - -1。nice值是在用户视角下的优先级,内核视角下的优先级是0-139,0-100保留给实时进程,100-139映射成nice值保留给普通进程。
O(1) 调度器
在Linux 2.6 版本的内核中使用的调度算法。
每个CPU维护两个队列active队列和expired队列。active队列存放时间片尚未用完的任务,expired队列存放时间片已经耗尽的任务。当一个任务的时间片用完之后会被移动到expired中去,并重新计算优先级。当active队列为空之后,会交换指针,使得expired队列变为active队列。O(1)调度器为每一个优先级提供了一个任务链表。
- 常数时间确定优先级,需要在位图找到第一个为1的,即含有任务的队列中为最高优先级的队列
- 常数时间获取下一个任务,在上面的队列链表中取第一个任务来执行
综上,不管是优先级计算还是队列切换都与任务个数无关,能在O(1)的时间复杂度下进行。
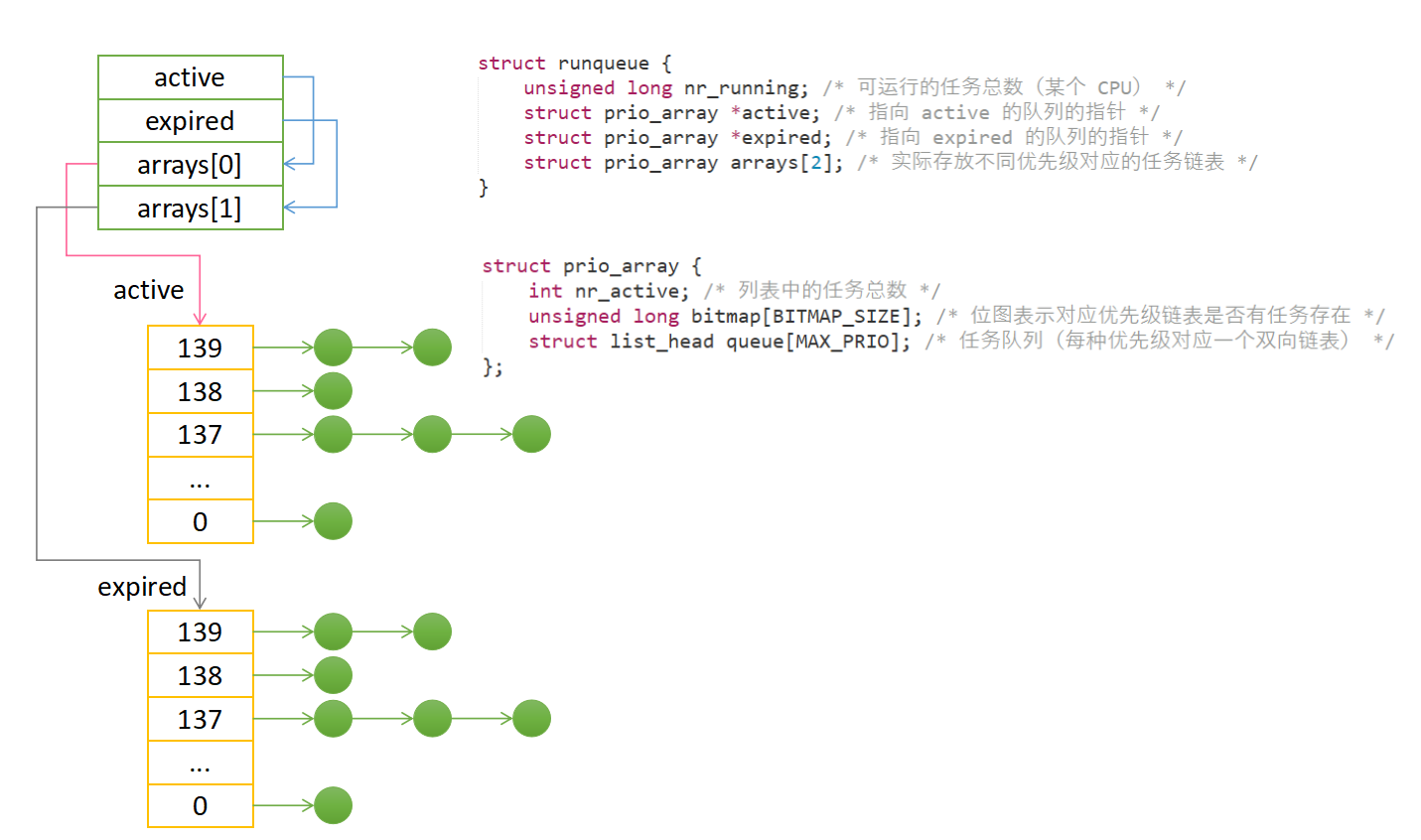
O(1)调度器为了更好地提供服务,通常会对优先级进行一些启发式调整。
- 对交互线程(IO-bound)的优先级进行奖励
- 对CPU占用线程的优先级进行惩罚
- 对饥饿线程的优先级进行奖励
- 对一直执行的线程的优先级进行惩罚
系统区分静态优先级和动态优先级。动态优先级采取上述机制。系统维护一个sleep_avg变量。
CFS 调度器
CFS(Complete Fair Scheduler)完全公平调度器。
它实现了一个基于权重的公平队列算法,从而将 CPU 时间分配给多个任务(每个任务的权重和它的 nice 值有关,nice 值越低,权重值越高)。每个任务都有一个关联的虚拟运行时间 vruntime,它表示一个任务所使用的 CPU 时间除以其优先级得到的值。相同优先级和相同 vruntime 的两个任务实际运行的时间也是相同的,这就意味着 CPU 资源是由它们均分了。为了保证所有任务能够公平推进,每当需要抢占当前任务时,CFS 总会挑选出 vruntime最小的那个任务运行。
内核版本在 2.6.38 之前,每个线程(任务)会被当成独立的调度单元,并且和系统中其它线程共享资源,这就意味着一个多线程的应用会比单线程的应用获得更多的资源。之后,CFS 不断改进,目前已经支持将一个应用中的线程打包到 cgroup 结构中,cgroup 的 vruntime 是其中所有线程的 vruntime 之和。然后 CFS 就可以将它的算法应用于cgroup 之间,从而保证公平性。当某个 cgroup 被选中后,其中拥有最小 vruntime 的线程会被执行,从而保证 cgroup 中的线程之间的公平性。
CFS 引入了红黑树(本质上是一棵半平衡二叉树,对于插入和查找都有 O(log(N)) 的时间复杂度)来维护运行队列,树的节点值是调度单元的 vruntime,拥有最小 vruntime 的节点位于树的最左下边。

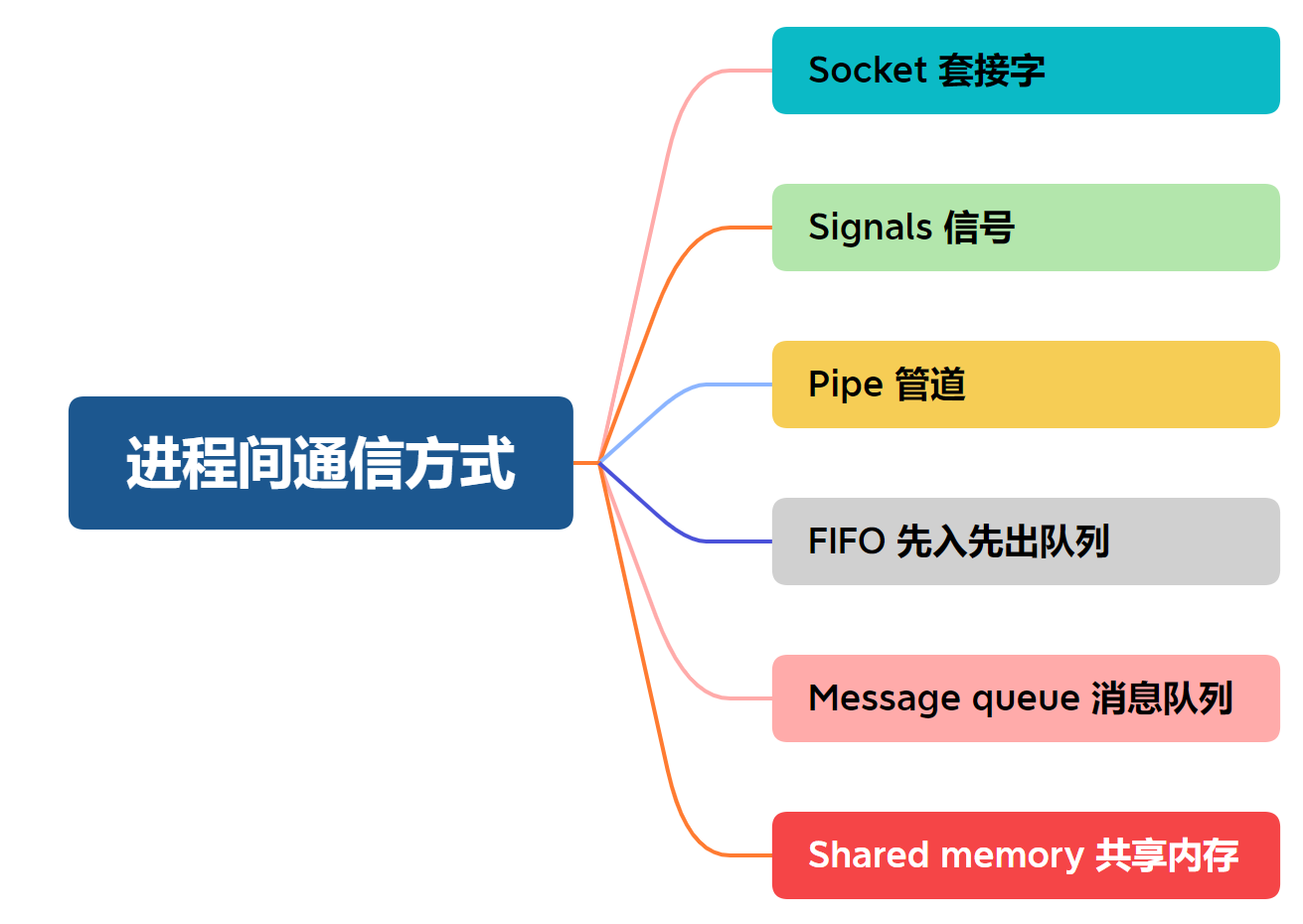
进程通信
Linux进程间的通信机制被称为IPC(Internal-Process communication), 其通信机制可以分为以下6种:
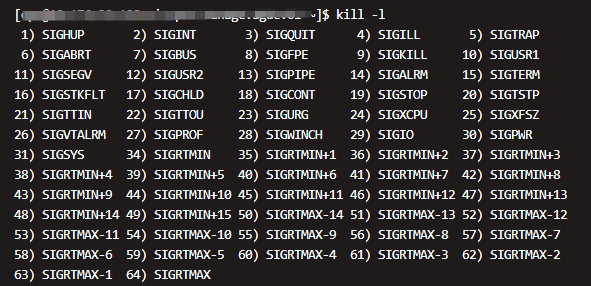
信号
UNIX系统最开始使用的就是信号,向进程发送异步事件信号。kill -l 命令可以列出系统使用的信号。
Linux中的
kill命令用来终止指定的进程(terminate a process)的运行,是Linux下进程管理的常用命令。通常,终止一个前台进程可以使用Ctrl+C键,但是,对于一个后台进程就须用kill命令来终止,我们就需要先使用ps/pidof/pstree/top等工具获取进程PID,然后使用kill命令来杀掉该进程。kill命令是通过向进程发送指定的信号来结束相应进程的。在默认情况下,采用编号为15的TERM信号。TERM信号将终止所有不能捕获该信号的进程。对于那些可以捕获该信号的进程就要用编号为9的kill信号,强行“杀掉”该进程;Negative(负数) PID values may be used to choose whole process groups;命令格式:kill[参数][进程号]
进程可以选择忽略发送过来的信号,只有两个不能忽略:SIGSTOP,SIGKILL
管道
两个进程间可以建立一个管道,一个进程写,一个进程读,管道是同步的,当进程试图读一个空管道,该进程会被阻塞直到数据可用。shell中的管线就是管道实现。
例如:
# 用 last 将显示的登陆者信息,仅留下用户名
[mrcode@study ~]$ last
# 账户 终端机 登录 IP 日期时间
mrcode pts/1 192.168.0.105 Mon Dec 2 01:25 still logged in
mrcode pts/0 192.168.0.105 Mon Dec 2 01:25 still logged in
mrcode pts/1 192.168.0.105 Mon Dec 2 00:21 - 01:12 (00:51)
# 用空格分隔的数据,那么可以这样做
[mrcode@study ~]$ last | cut -d ' ' -f 1
mrcode
mrcode
mrcode
# 利用 last ,将输出的数据仅取账户,并排序
[mrcode@study ~]$ last | cut -d ' ' -f 1 | sort
mrcode
mrcode
mrcode
共享内存
两个进程之间还可以通过共享内存进行进程间通信,其中两个或者多个进程可以访问公共内存空间。两个进程的共享工作是通过共享内存完成的,一个进程所作的修改可以对另一个进程可见(很像线程间的通信)。
在使用共享内存前,需要经过一系列的调用流程,流程如下
- 创建共享内存段或者使用已创建的共享内存段
(shmget()) - 将进程附加到已经创建的内存段中
(shmat()) - 从已连接的共享内存段分离进程
(shmdt()) - 对共享内存段执行控制操作
(shmctl())
先入先出队列
FIFO也被叫做命名管道(Named Pipes),与管道相比,它的区别在于,未命名管道传输的数据可能丢失,是由操作系统负责维护内存的缓冲区,将字节从写入器传输到读取器,一旦写入或者输出终止的话,缓冲区将被回收,传输的数据会丢失。而命名管道具有支持文件和独特 API ,命名管道在文件系统中作为设备的专用文件存在。当所有的进程通信完成后,命名管道将保留在文件系统中以备后用。
消息队列
略
套接字
套接字一般用于两个进程之间的网络通信,需要TCP, UDP等基础协议的支持。
套接字有以下几种分类:
顺序包套接字(Sequential Packet Socket): 此类套接字为最大长度固定的数据报提供可靠的连接。此连接是双向的并且是顺序的。数据报套接字(Datagram Socket):数据包套接字支持双向数据流。数据包套接字接受消息的顺序与发送者可能不同。流式套接字(Stream Socket):流套接字的工作方式类似于电话对话,提供双向可靠的数据流。原始套接字(Raw Socket): 可以使用原始套接字访问基础通信协议。
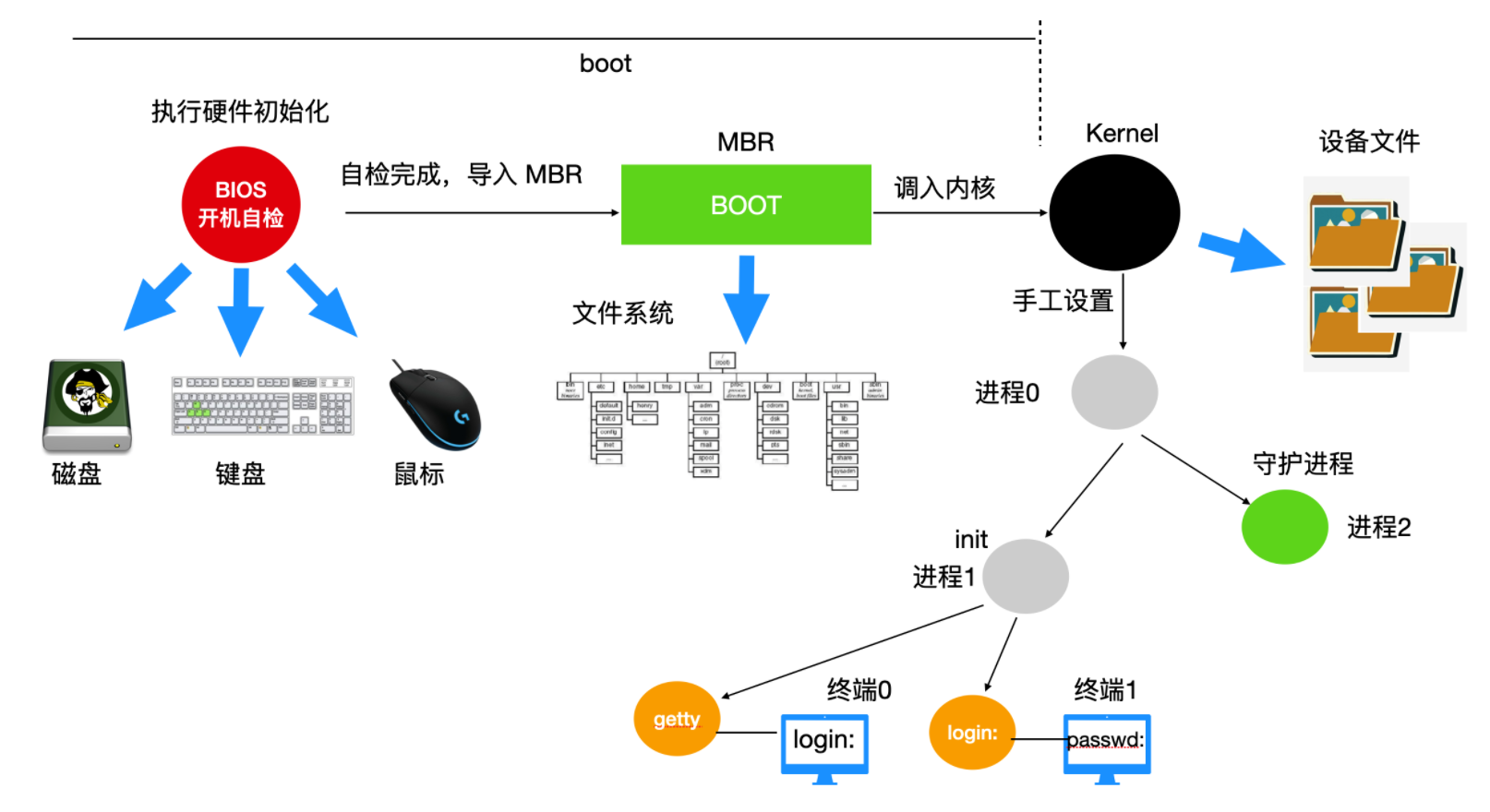
Linux启动
用户态线程与内核态线程映射
内核态线程
👍 可以利用多核CPU优势;操作系统级优化
👎 创建切换成本高,切换到内核态;扩展性差,数量不能太多
用户态线程
👍 创建切换成本小
👎与内核协作成本高,无法利用多核,操作系统无法针对线程调度优化
- One to One
- Many to One
- Many to Many
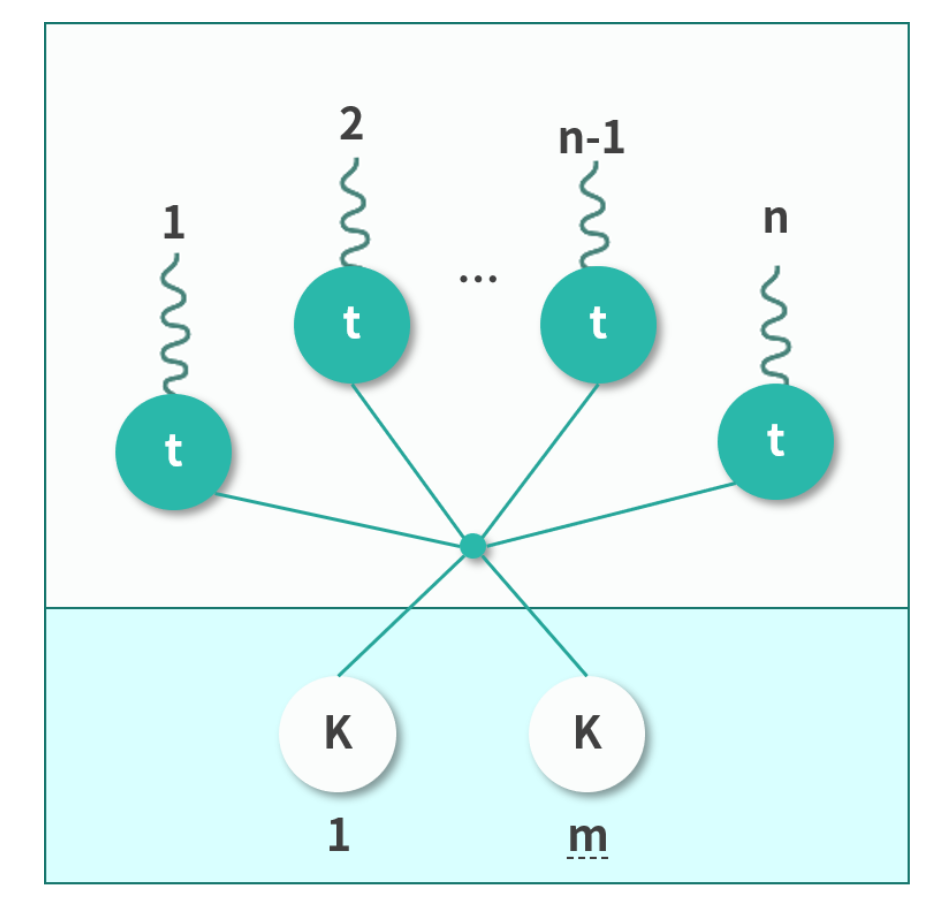
通常m < n, 一般把m设置为内核的核数(Linux采用该模型)



