操作系统 - 内存管理
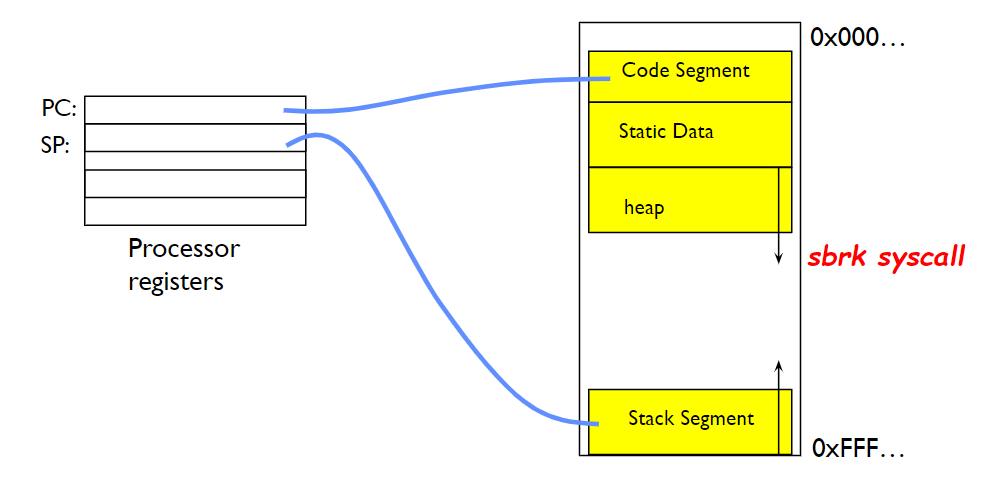
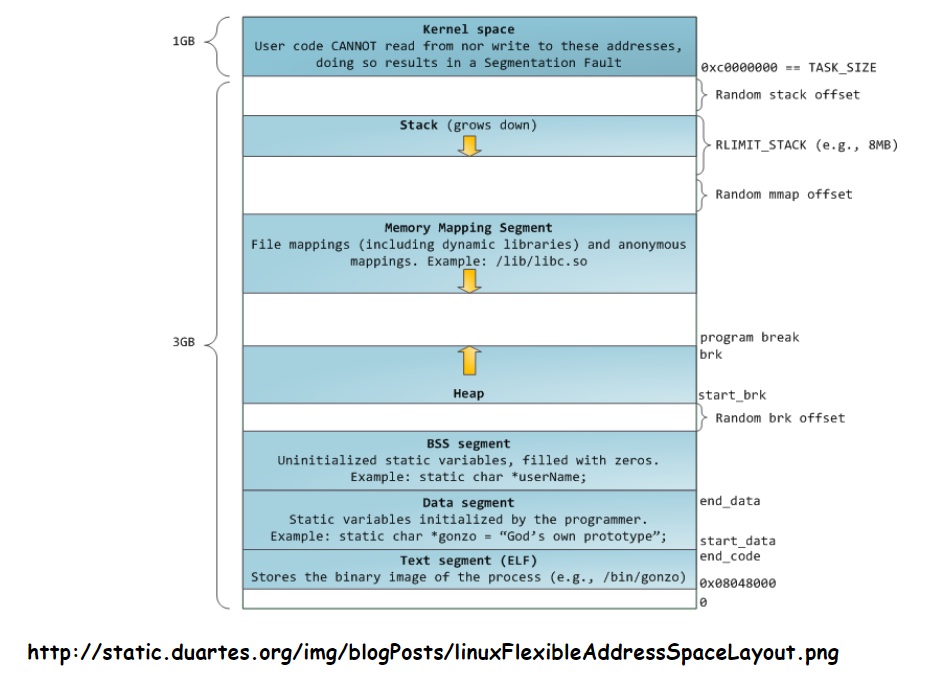
进程的地址空间结构
多线程进程和单线程进程的空间结构
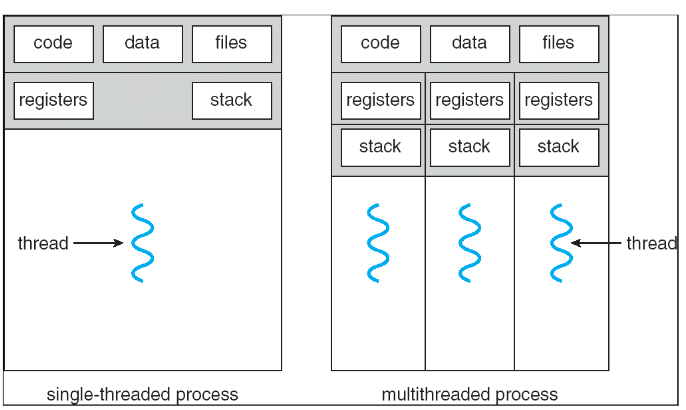
- 线程是对并发的一个封装 Thread encapsulate concurrency
- 地址空间是对保护的一个封装 Address space encapsulate protection
如何解决内存不够用的问题?
SWAP技术
如果空间不足,将没有在执行的进程的数据从内存移动到磁盘腾出内存空间给需要的进程。
👎 产生内存碎片
👎 频繁切换
虚拟内存技术
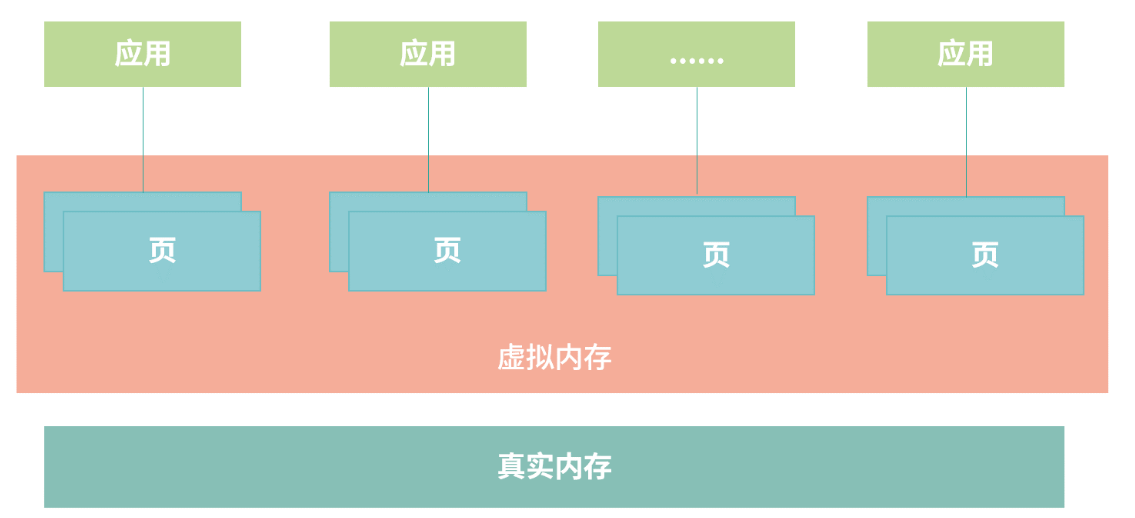
操作系统将虚拟内存分为整齐的页(Page), 整齐的页能避免内存碎片,且在操作系统的角度考虑只用以页为单位思考哪些页被高频使用,哪些被低频使用。
页和页表
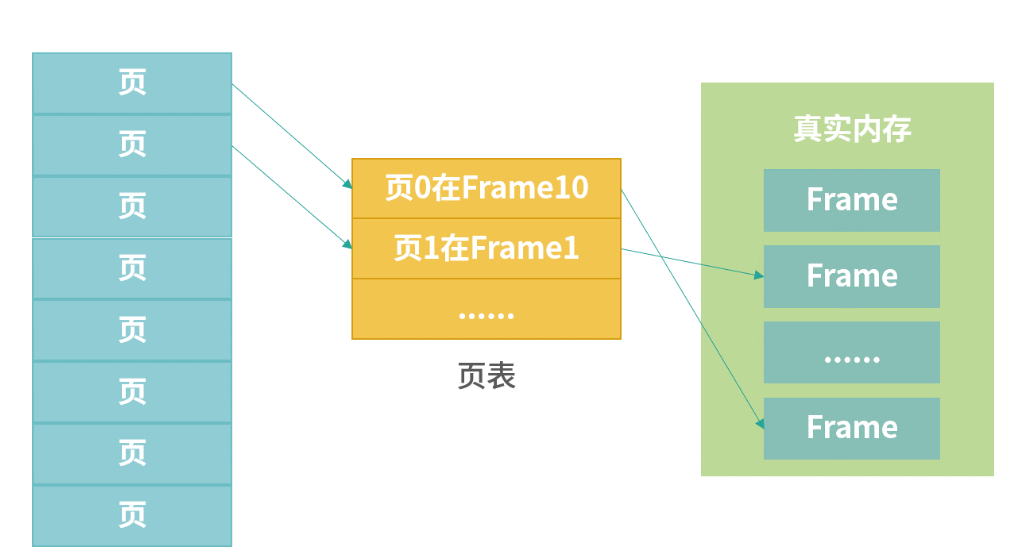
页表维护的就是页(虚拟内存)到真实内存的映射,可以通过页表编号算出物理地址,这个计算过程发生在CPU的MMU(Memory Management Unit)单元
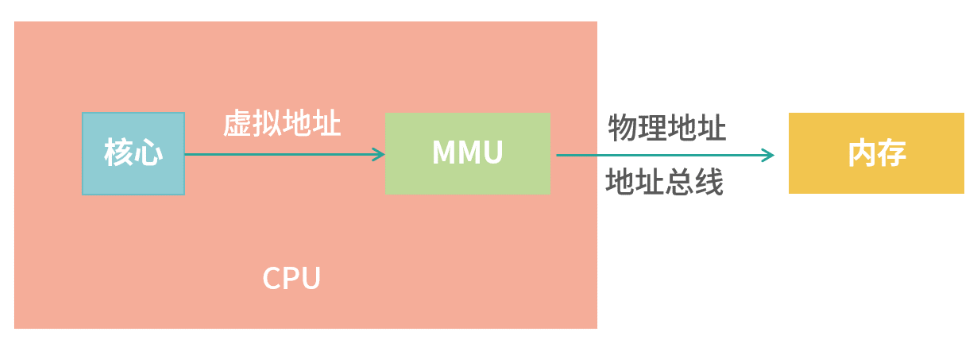
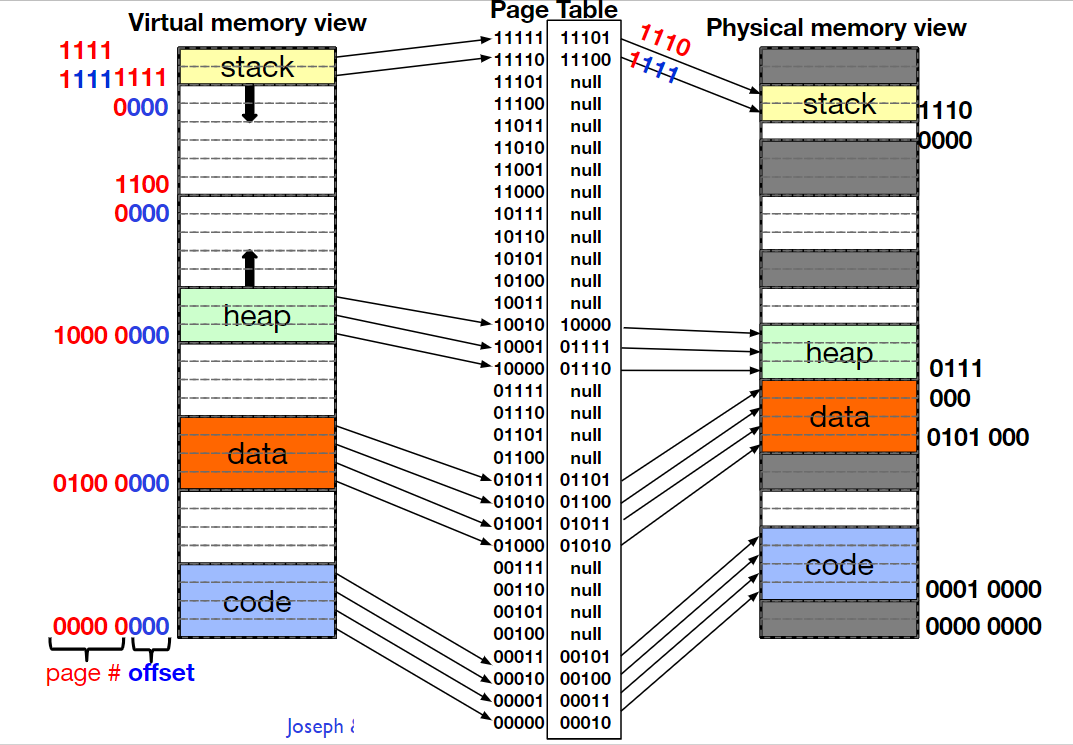
TLB
指令执行非常快,但是MMU中查页表存在读取内存的操作,即便是用CPU缓存,整个过程也需要几个CPU的指令周期,但我们希望该任务能在0.2个CPU周期内完成,即地址缓存不会增加指令的CPU周期,所以在MMU内部还有一个转置检测缓冲区(Translation Lookaside Buffer TLB), 该缓存就主要存储页编号(Page Number)到表编号(Frame Number)的映射,通过硬件实现,速度很快。
🎄 TLB Miss
- 软失效(Soft Miss)
Frame还在内存中,但是TLB缓存没有,需要刷新TLB缓存,比如使用常见的LRU算法
- 硬失效(Hard Miss)
Frame不在内存中,需要从磁盘加载:操作系统首先要触发一个页中断(原有线程被休眠),中断响应程序从磁盘读取Frame到内存,再触发中断通知更新TLB, 并唤醒之前被中断的线程去排队。
🎄 TLB 缓存设计
从全相联映射(Fully Associative Mapping)直接映射(Direct Mapping)到n路组相联映射(n-way Set-Associative Mapping)
- 全相联映射
把所有缓存条目都放到数组中,给定Page Number 遍历整个数组; 👎存在明显的性能缺陷
- 直接映射
用一个类似Hash函数的计算,比如缓存行号 = Page Number % 64, 假设虚拟地址空间大小为1 G, 页大小为4 K, 一共有1024 * 1024 / 4 = 262144 个页表条目,平均262144/64 = 4096个页共享一个缓存行,但这种设计无法实现LRU缓存,因为每次替换的条目是固定的。于是有了n路组相联映射。
组相联映射允许一个虚拟页号(Page Number)映射到固定数量的 n 个位置。举个例子,比如现在有 64 个条目,要查找地址 100 的位置,可以先用一个固定的方法计算,比如 100%64 = 36。这样计算出应该去条目 36 获取 Frame 数据。但是取出条目 36 看到条目 36 的 Page Number 不是 100,这个时候就顺延一个位置,去查找 37,38,39……如果是 4 路组相联,那么就只看 36,37,38,39,如果是8 路组相联,就只看 36-43 位置
所以新地址进来的时候,可以选出n个中最早更新的替换出去。e.g. i7 CPU的L1 TLB采用 4 - Way 64条目的设计; L2 TLB 采用 8 - Way 1024条目,具体设置背后有大量实验,实际数据的印证。
- n路组相联映射
上面这个问题实际要解决的一个直接点就是一个缓存条目应该可以被存在多个位置,这样就可以有选择。
大内存分页
如果我的页变大了,那么我缓存的条目会减少,TLB的查询性能也会提高,可以通过sudo sysctl -w vm.nr_hugepages=2048,或Java应用-XX:+UseLargePages来开启大内存分页。对内存需求较大时, 可以考虑开启大内存分页。比如搜索引擎。
页表条目
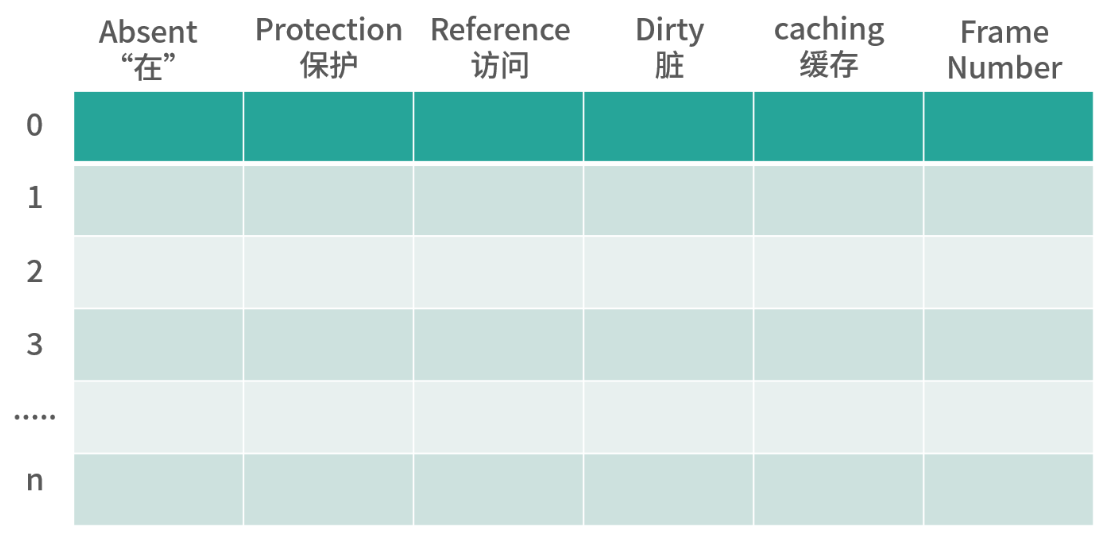
- Absent 0 : 数据在磁盘中; 1 : 数据在内存中
- Protection 3个bit,决定页用于读写执行
- Reference, 代表这个页被读写过,帮助进行内存回收
- Dirty 1 代表为脏页,回收时需要先写回磁盘
- Caching,描述页可不可以被CPU缓存
- Frame Number 即表编号,用编号乘以页大小加上偏移量可以得到物理地址
