MySQL - 分库分表
原则
分库分表有一个前提:能不拆就不拆,能少拆就少拆,避免过度设计和过早优化,优先考虑升级硬件,索引优化,读写分离等等。因为拆分会带来开发和后期维护的成本。那为什么仍然需要分库分表呢?第一,某些系统还是需要依赖MySQL来保证金融级的事务。第二,MySQL本质是单机数据库,支持不了太大的数据量和高并发。所以只能是,数据量和并发大到没其他办法了,我们才分库分表
- 分表: 解决查询慢,让每次查询的数据总量减少。
- 分库: 解决高并发。
如何选择Sharding Key?
主要的考虑因素就是:业务是怎么查的。例如订单系统,如果根据订单ID(主键)进行分片,查订单ID的时候就根据订单ID和分片算法找到是哪个分片就在分片上查就行了。但是如果是用户订单界面,查的是用户ID呢?这个问题可以这样解决,根据用户ID分片,然后规定订单ID的10-14位为用户ID的后四位,,查订单ID的时候通过10-14位找到分片位置。
但如果有各种各样的查询呢?例如商家查询自己店铺的订单,各种订单数据报表统计等等。一般做法是把订单数据同步到其他存储系统里面去,去其他存储系统解决。例如我们再构建一个以店铺ID作为sharding key的只读订单库,给商家查询。或者把订单同步到HDFS(Hadoop分布式文件系统)中,用大数据技术生成报表
如何选择分片算法
-
范围分片,例如根据订单的时间来分片。
👍这种方式对查询比较友好,我们可以规定所有查询都必须带上时间,那么就可以支持各种各样的查询。
👎容易出现热点数据。如大部分查询都是针对最近三个月的查询,那么其他历史时间的分片根本用不上。不太适合并发量很大的情况。 -
哈希分片
通过哈希算法。要保证sharding key均匀分布。
👍数据分布相对均匀,不容易出现热点数据。
👎后期分片扩容,迁移旧数据(可以用一致性hash算法避免这个问题)
👎跨分片查询的复杂问题,查询条件不带片键,需要在内存中合并数据 -
查表
自定义规定一个分片映射表,查数据前先查映射表。
👍灵活性高,分片可以随时改变,可以人为让数据均匀分布
👎性能较差,如果分片映射表本身数据太多,那么这个表将成为热点和性能瓶颈(但可以通过缓存来加速)。
分库分表带来的问题
事务一致性
分库,会导致跨库事务,跨分片也是分布式事务,没有简单方案,要使用2PC等。事务在访问共享资源时发生冲突或者死锁的概率增大。
跨节点关联join问题
解决:
字典表
每个数据库都保存一份
字段冗余
反范式设计,利用空间换时间。冗余字段的一致性问题
数据组装
分两次查询,先查id再查数据。
ER分片
确定表之间的关系,存在关联关系的表记录放在同一个分片上,避免跨分片的join。
跨节点分页排序函数问题
全局主键避重问题
UUID
32个16进制数字,优点是简单,本地生成,性能高,没有网络耗时。缺点UUID很长,无序性导致数据位置频繁变动,分页。
SnowFlake分布式自增ID算法
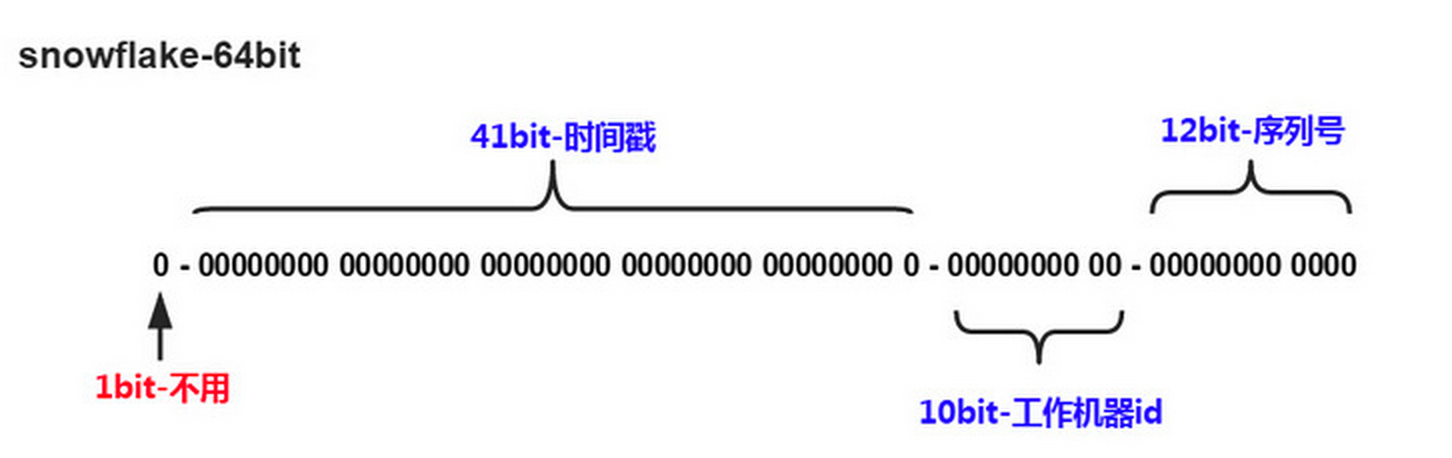
Twitter的snowflake算法解决了分布式系统生成全局ID的需求,生成64位的Long型数字,组成部分:
- 第一位未使用
- 接下来41位是毫秒级时间,41位的长度可以表示69年的时间
- 5位datacenterId,5位workerId。10位的长度最多支持部署1024个节点
- 最后12位是毫秒内的计数,12位的计数顺序号支持每个节点每毫秒产生4096个ID序列
这样的好处是:毫秒数在高位,生成的ID整体上按时间趋势递增;不依赖第三方系统,稳定性和效率较高,理论上QPS约为409.6w/s(1000*2^12),并且整个分布式系统内不会产生ID碰撞;可根据自身业务灵活分配bit位。
不足就在于:强依赖机器时钟,如果时钟回拨,则可能导致生成ID重复。
问题
为什么流传着单表大于2000w行innodb性能急剧下降的说法?
(1) 索引问题
MySQL加载索引是以页为单位,不是一次性全部加载到内存中,每次只加载需要的那一块。一般高度为3的数据就可以存储千万级别的数据了,只需要3次IO。数据太大可能导致树高增加后,IO次数增多。
对B+树进行修改时,如果修改不会引起B+树的结构变动,如分裂合并等,那么只需对根节点和非叶子节点加读锁(共享锁shared lock),对叶子节点加写锁(排他锁,exclusive lock)。如果对叶子节点的修改会引起结构调整线程SMO(Struction-Modification-Operation),即会对根节点加全局SX锁(行锁),然后对根到叶子可能要修改的节点加X锁,根节点始终持有SX锁,其他的SMO需要等待。所以数据量大且改动频繁的业务会有严重的瓶颈。
(2) I/O压力
数据量大,在磁盘上需要读取更多数据块,增加IO压力。也需要更多内存缓存数据,内存资源有限,内存不足也会增大磁盘IO压力。
(3)锁竞争
数据量增大,锁竞争增大,性能下降。
如果一张大表原本用的自增主键,查询也是查自增主键,如何拆分成多张表?
分库分表策略,查询非拆分字段的方案
垂直切分(按列,数据库以行为单位加载到内存,字段长度短访问高能加载更多数据,命中率更高,减少了磁盘IO)一些字段使用非常频繁和使用很少的,一些字段很大和很小的
和
水平切分(按行)以上。
非拆分字段的查询:
- 查表法,可以建立非拆分字段到片键字段的映射表,该表只有两个字段,kv结构可以很好使用cache来优化性能,且映射关系不会频繁变更,缓存命中率很高。
- 基因法:例如使用uid%8进行路由,则此时由uid最后3bit来决定这个数据,这3bit可以看做分库基因。生成uid时,先考虑分布式ID生成方案,再加上最后3位bit值,其他非拆分字段,可以加上这个基因,例如后面直接拼接这个值,所以查的时候可以直接取出基因%8,不再需要额外的映射表。
为什么要用B+树
B树,Hash, 红黑树,AVL树
在存储 & 索引这一章有讲B,B+和hash,这里重点看红黑树,旋转次数比AVL少,高度始终保持在H=logN,AVL(平衡二叉树):保持平衡耗时;这俩还是树高有点高



