MongoDB - Data Models
Data Model概念
如果要给MongoDB打标签,那么首选的几个标签无非是NoSQL, 非关系型数据库, 分布式文档存储数据库。而关系型数据库,非关系型数据库一个非常重要的区别就是Data Model。Data Model 决定了“要怎么存”,“适用怎么查”等,也是选型的一个重要考虑因素。
所以呐,我们不能用MySQL那一套建表的惯性来思考。MongoDB的Data Model主要有两类,Embedded Data Models和Normalized Data Models。
Embedded Data Models
嵌入式数据模型,顾名思义,我们把子文档嵌入在主文档里面。如下图,主文档是用户属性,而用户的联系方式,操作权限级别等子属性,一并用嵌入的方式,放进我们的用户属性文档里面。

这种数据模型可以很好的应用于“一对一”,“一对多”的关系结构上,例如上面的用户联系方式就是“一对一”,用户操作权限级别就是“一对多”(一个用户只有一个操作级别,一个操作级别对应很多用户)。
👍 优势:📢MongoDB本身是推荐使用这样的数据模型的。其一,因为这种结构对于“读”场景来说,只用做一次读操作,不用去查很多表;其二,MongoDB对单文档操作时原子性的,所以天生对于一个文档的不同field的更新操作是安全的。
👎 缺点:数据冗余,以及数据冗余带来的性能问题等;“多对多”的关系比较难以表达。
Normalized Data Model
标准化数据模型,就和之前学过的关系型数据库很像了,它使用references来关联两个文档。
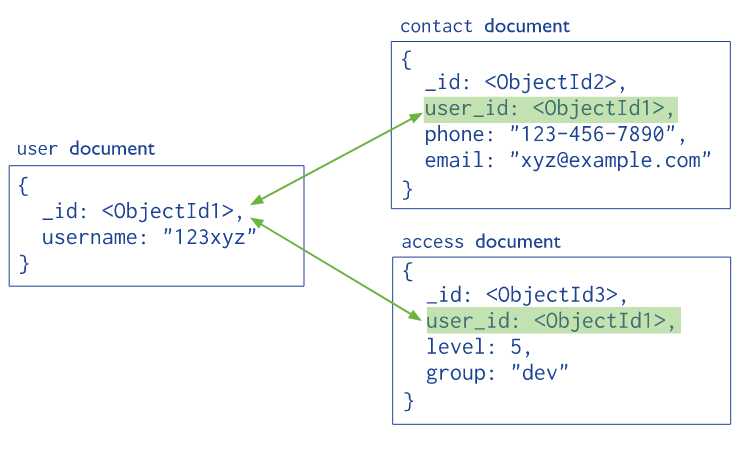
标准化数据模型主要就是针对嵌入式数据模型的两个缺点来补充的。而对于标准化数据模型查询时,避免不了的join操作,MongoDB提供了$lookup,$graphLookup来提供。但是我们在使用MongoDB的时候,仍然需要优先考虑嵌入式数据模型。如果必须存在很多join操作,那需要考虑是不是不要使用MongoDB了。
设计Data Model
Data Model设计的元素
数据模型的元素:
- 实体(Entity), 描述业务的主要数据集合: who, where, when, what, how, why etc.
- 属性(Attribute), 描述实体里面的单个信息,或者也叫field
- 关系(Relationship), 描述实体与实体之间的数据规则
- 结构规则:1-1, 1-N,N-N
- 引用规则:e.g. 电话号码不能单独存在
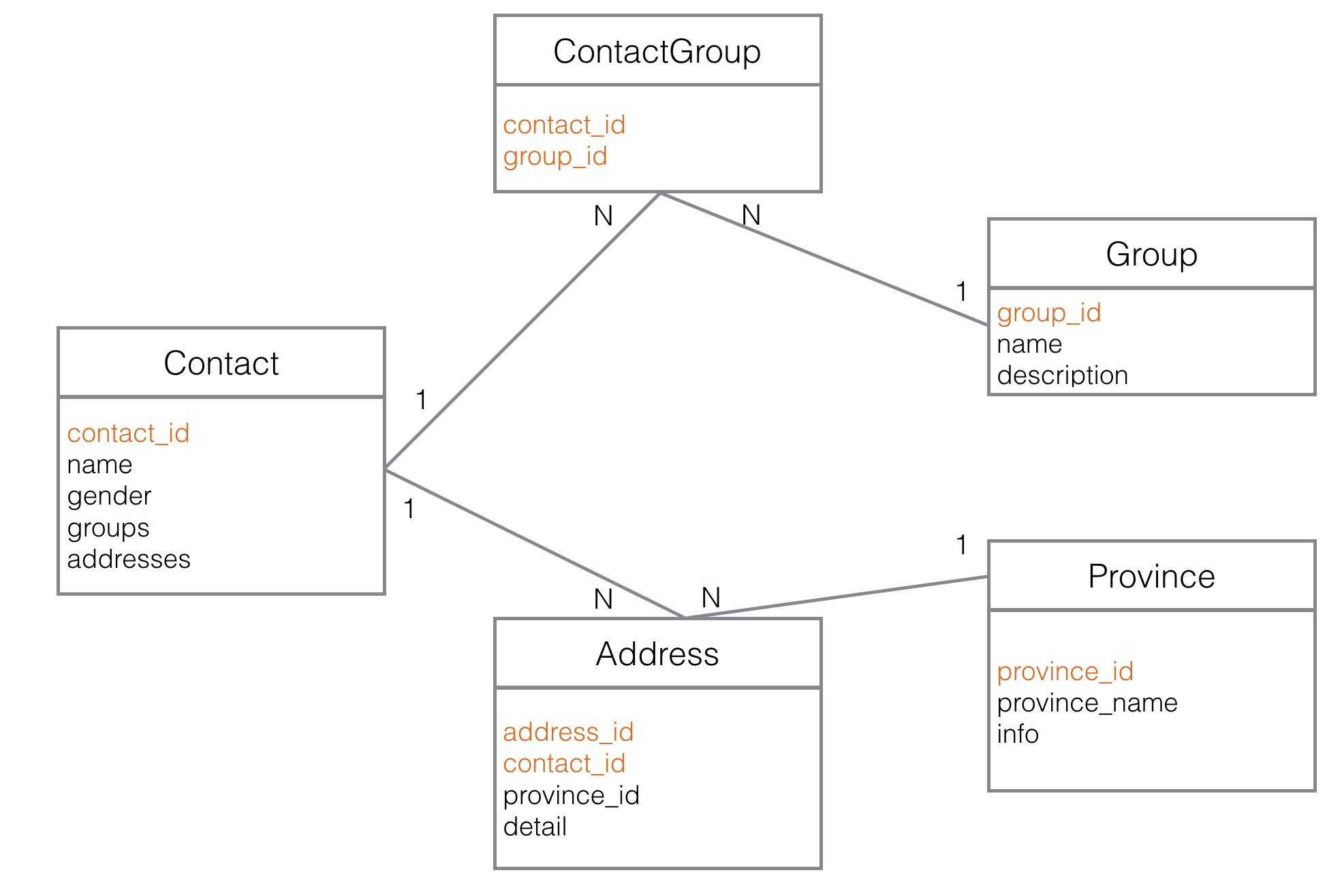
第三范式下的物理模型
e.g. 一个电话本联系人和分组的数据存储模型,在第三范式的要求下(数据库不存在冗余),物理模型如下:
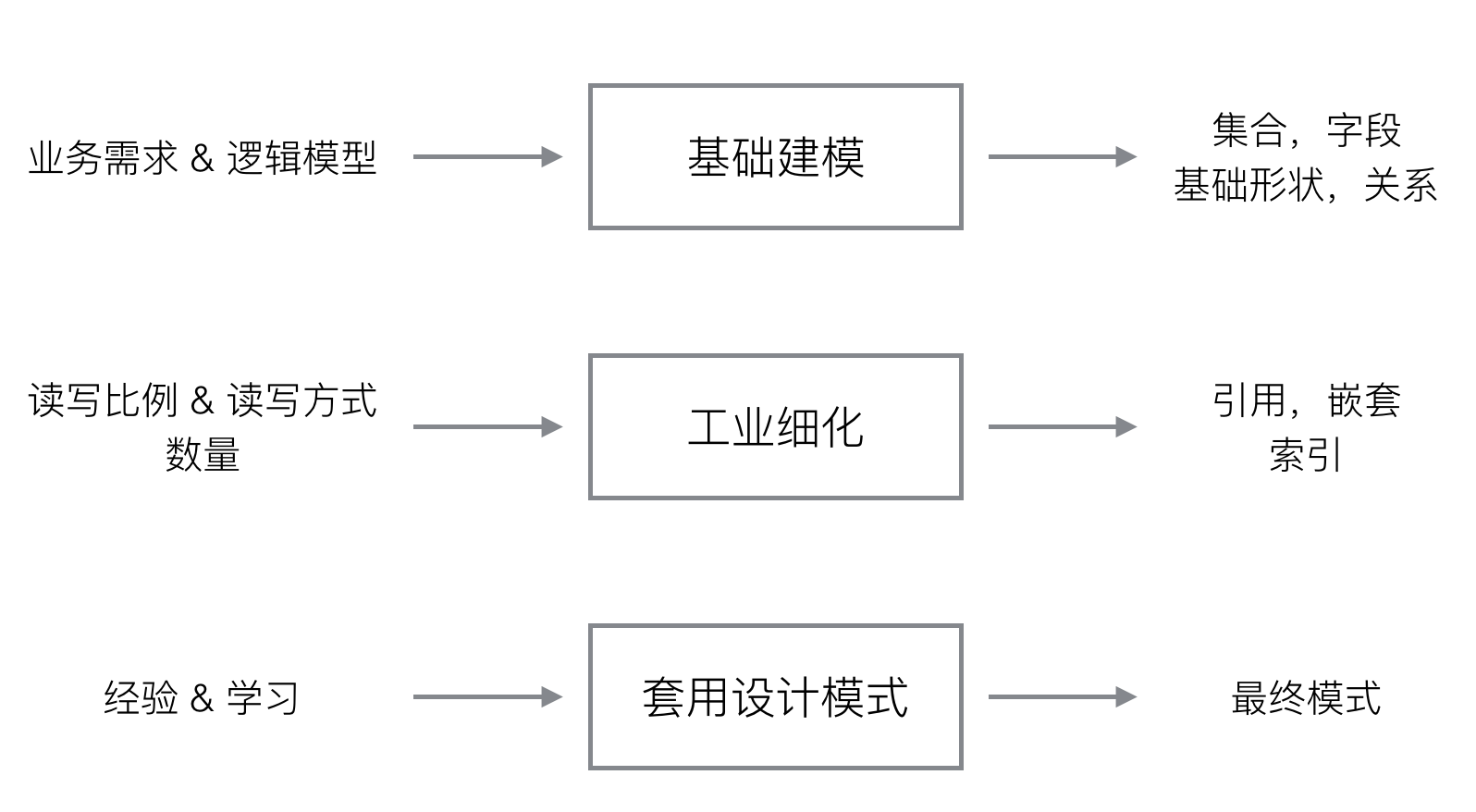
模型设计三部曲
JSON文档模型设计:
- 特点:不用遵循第三范式,允许冗余
- 设计原则:性能+易用
基础建模
- 一对一关系以内嵌为主,使用子文档或者直接在顶级;例外:内嵌后文档超过16MB(因为MongoDB文档大小限制为16MB)。
- 一对多关系也以内嵌为主,使用数组来表示。例外:文档超过16MB, 数组太大,长度不确定等等
- 多对多关系,通过内嵌实现一对多,通过冗余实现多对多。例外:同上。
工业细化
技术需求分析:
- 最频繁的数据查询模式
- 最常用的查询参数
- 最频繁的数据写入模式
- 读写操作比例
- 数据量大小
方式:
- 基于内嵌的文档模型
- 在如下情境下,使用引用避免性能瓶颈
- 内嵌文档太大
- 内嵌文档或数组会频繁修改
- 内嵌数组持续增长没有封顶
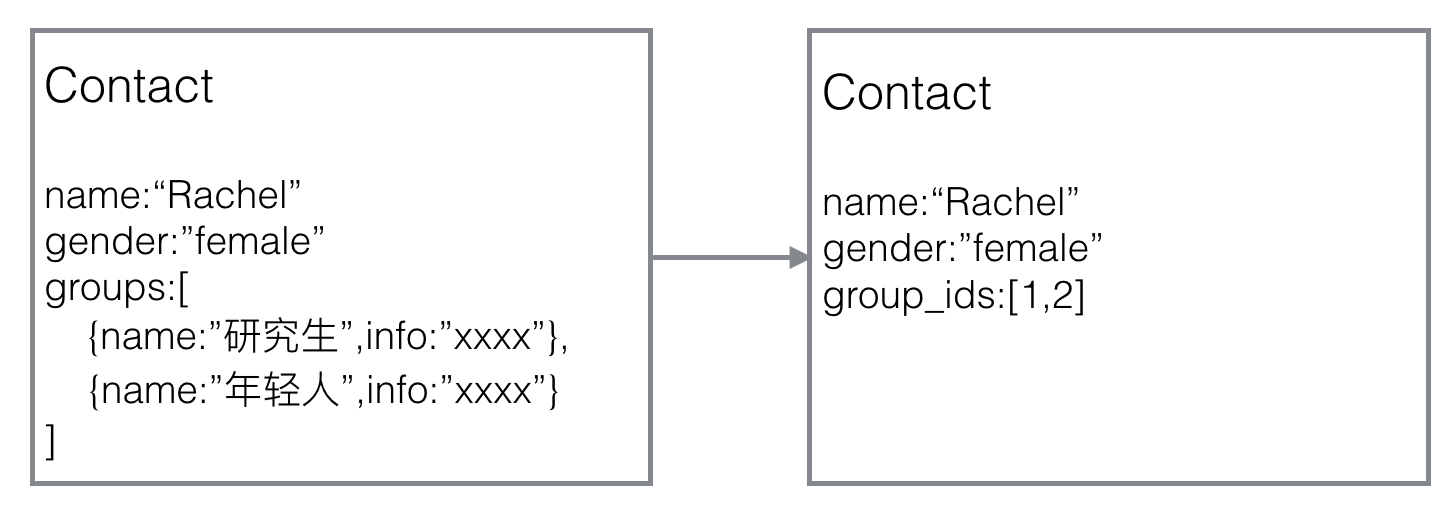
栗子1🌰:上述物理模型,如果对于Contact和Group使用内嵌和冗余实现N对N, 如果联系人数量有千万级,对分组Group有频繁改动,那么改一次group_name,就是千万级的DB操作,这个使用可以使用引用来避免:
使用$lookup实现类似join的多表查询,查询的结果就包含一个新的field"group"里面是分组的具体信息:(注意:$lookup只能做left outer join, 且from表不能是分片表)
db.contact.aggregate([
{
$lookup:{
from:"group",
localField:"group_ids",
foreignField:"group_id",
as:"group"
}
}
])
栗子2🌰:联系人头像比较小时,可以直接放在contact表(mongoDB支持存储二进制),但如果联系人头像比较大,改动不频繁,且基础查询比例很小(一般不查头像)这些情况,也可以用引用,把头像放到另外一个集合,来提升查询效率。
- 根据业务需求,使用冗余优化访问性能
套用设计模式
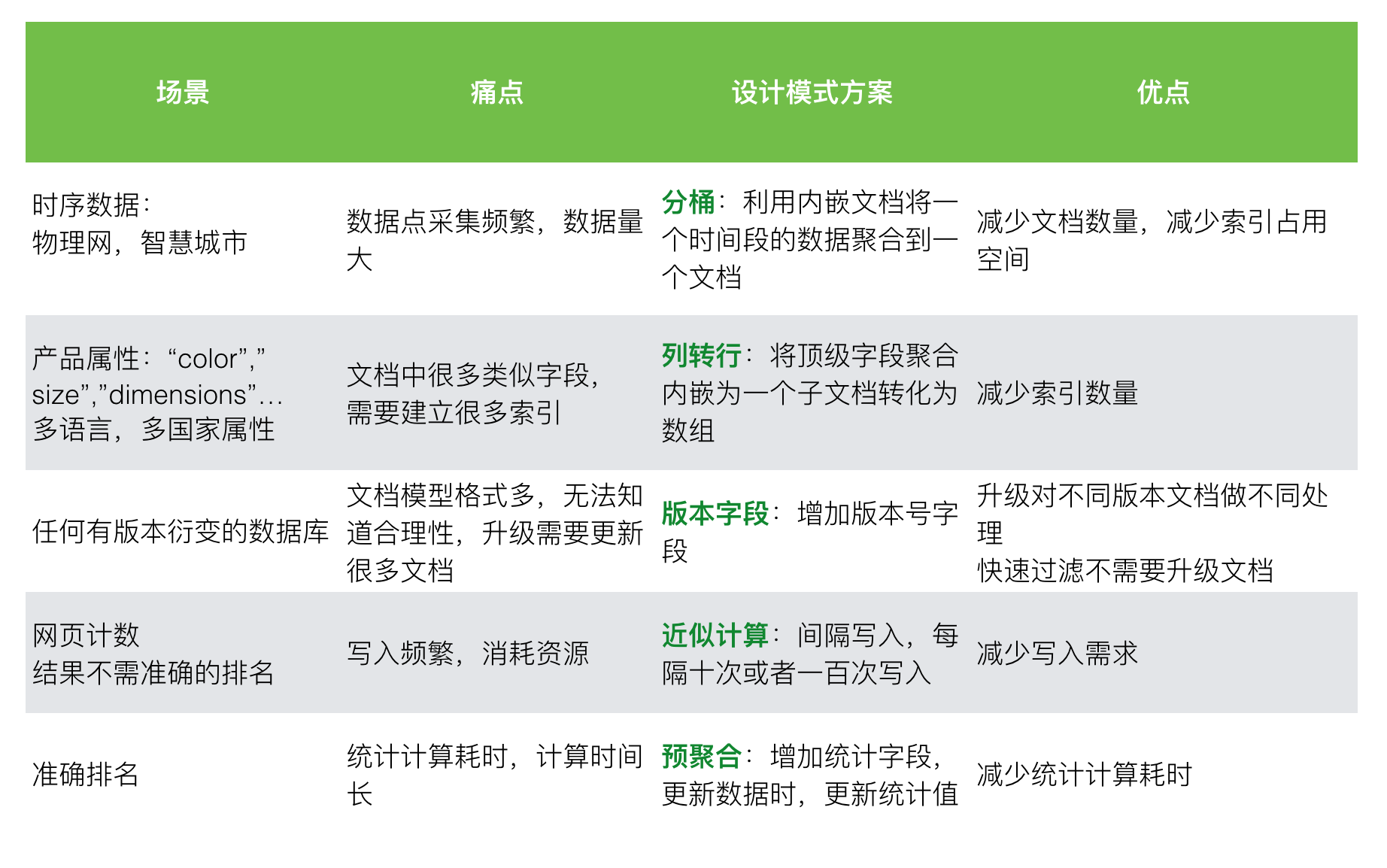
其他应用场景
这里列举一些官方展示的应用场景的考虑:
原子操作
如果有些field需要作为一个原子操作一起更新,就需要考虑把它们放在一个文档里面。例如图书馆里书籍信息里面的可用数量和借书信息需要一起更新:
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly",
available: 3,
checkout: [ { by: "joe", date: ISODate("2012-10-15") } ]
}
就可以:
db.books.updateOne (
{ _id: 123456789, available: { $gt: 0 } },
{
$inc: { available: -1 },
$push: { checkout: { by: "abc", date: new Date() } }
}
)
关键字搜索
这里的关键字搜索和全文搜索是不一样的。MongoDB可以创建multi-key index。图书管理书籍信息如下:
{ title : "Moby-Dick" ,
author : "Herman Melville" ,
published : 1851 ,
ISBN : 0451526996 ,
topics : [ "whaling" , "allegory" , "revenge" , "American" ,
"novel" , "nautical" , "voyage" , "Cape Cod" ]
}
可以在topics数组上创建multi-key index
db.volumes.createIndex( { topics: 1 } )
查询就可以根据关键字查,如:
db.volumes.findOne( { topics : "voyage" }, { title: 1 } )
其他
例如针对金融数据,IoT数据等等



