计算机网络 - HTTP
HTTP的特点
HTTP = hypertext transfer protocol,即超文本传输协议。在网络分层模型里面有说到,HTTP是应用层协议。它的主要特点如下:
- 无状态
HTTP是建立在TCP协议上的,我们知道TCP协议是有状态的。有状态意味着内部存在一些数据结构去维护这个状态。而HTTP是无状态的,没有记忆能力。 - 请求-应答
“一发一收,有来有回”,连接是请求方主动发起,应用方收到请求后被动答复 - 灵活可扩展
报文的各个组成部分都没有严格的语法语义限制,可以自由发挥。只规定了一些基本的,例如空格分隔单词,换行分隔字段,“header+body”等。 - 可靠传输
依靠TCP协议的“可靠性” - 明文传输
HTTP1.0 HTTP1.1 HTTP2.0比较
HTTP1.1
HTTP1.1是用的最多的协议
持久连接
它引入了持久连接,即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection:keep-alive
管道机制
同一个TCP连接里,客户端可以同时发送多个请求
分块传输编码
在1.0版中,Content-Length字段不是必需的,因为浏览器发现服务器关闭了TCP连接,就表明收到的数据包已经全了。使用Content-Length字段的前提条件是,服务器发送回应之前,必须知道回应的数据长度。对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)。
因此,1.1版规定可以不使用Content-Length字段,而使用"分块传输编码"(chunked transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。每个非空的数据块之前,会有一个16进制的数值,表示这个块的长度。最后是一个大小为0的块,就表示本次回应的数据发送完了。
增加动词
增加了PUT,DELETE等
HTTP2.0
二进制
HTTP/1.1 版的头信息肯定是文本(ASCII编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧"(frame):头信息帧和数据帧。二进制协议的一个好处是,可以定义额外的帧。HTTP/2 定义了近十种帧,为将来的高级应用打好了基础。如果使用文本实现这种功能,解析数据将会变得非常麻烦,二进制解析则方便得多。
多工
HTTP/2 复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应,这样就避免了"队头堵塞"。举例来说,在一个TCP连接里面,服务器同时收到了A请求和B请求,于是先回应A请求,结果发现处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。这样双向的、实时的通信,就叫做多工(Multiplexing)。
键入网址回车 - 发生了啥?
步骤如下:
- 浏览器查找域名的IP地址
先是浏览器自己的缓存,然后检查系统缓存(本机域名解析文件hosts),然后查找路由器缓存,然后向根域名服务器请求,然后递归向其他域名服务器请求。这里就会涉及到DNS解析。 - 浏览器向服务器发送HTTP请求
- TCP连接
- HTTP请求
- 收到服务器返回的HTTP报文(HTML响应)
- 根据HTML渲染解析页面
状态码
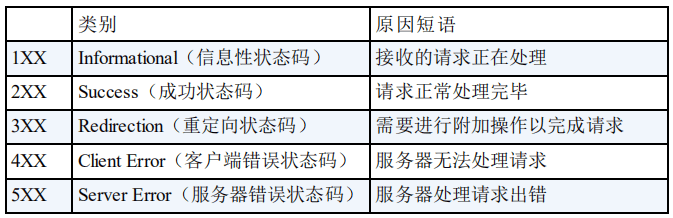
DNS解析
DNS解析指的就是域名到IP地址的解析,如下图所示:
图片来源:https://segmentfault.com/a/1190000006879700
域名解析系统是一个分层级的庞大系统:
- 本地DNS服务器
我们的电脑和手机里面都设置了本地DNS服务器,简称(LDNS) - 权威域名服务器
- 顶级域名服务器
- 根域名服务器
全世界有13个根DNS,10个在美国,英国瑞典1个,日本1个。但每个根都有镜像,全世界有一千多个物理服务器。我国境内对根DNS的请求,基本都由国内的镜像完成了,没有路由到国外的根服务器上去。
Cookie机制
Cookie是存在浏览器里的,是服务器委托浏览器存储在客户端里的一些数据。我们知道HTTP是无状态的,所以需要像Cookie这样传个小纸条,告诉服务器我这个客户端不是新人,以前有一些属性,可以根据这些属性提供个性化服务。
与之经常一起比较的是Session,Session是存储在服务端的,一般会用内存或者数据库(Redis一类的)来保存,也是记录用户的状态。例如购物车场景,通过Session标识并跟踪这个用户。
Nginx
参考资料
这里只是一些科普类的感性认知:
Nginx是个“轻量级”的Web服务器,它的CPU,内存占用都很少,同样的配置下能为更多的用户提供服务。
“进程池+单线程”工作模式
启动时预先创建好固定数量的worker进程,并绑定到独立的CPU上,除了worker进程,还有一个master进程来管理进程池,其作用是监控worker使worker异常后能自动恢复。
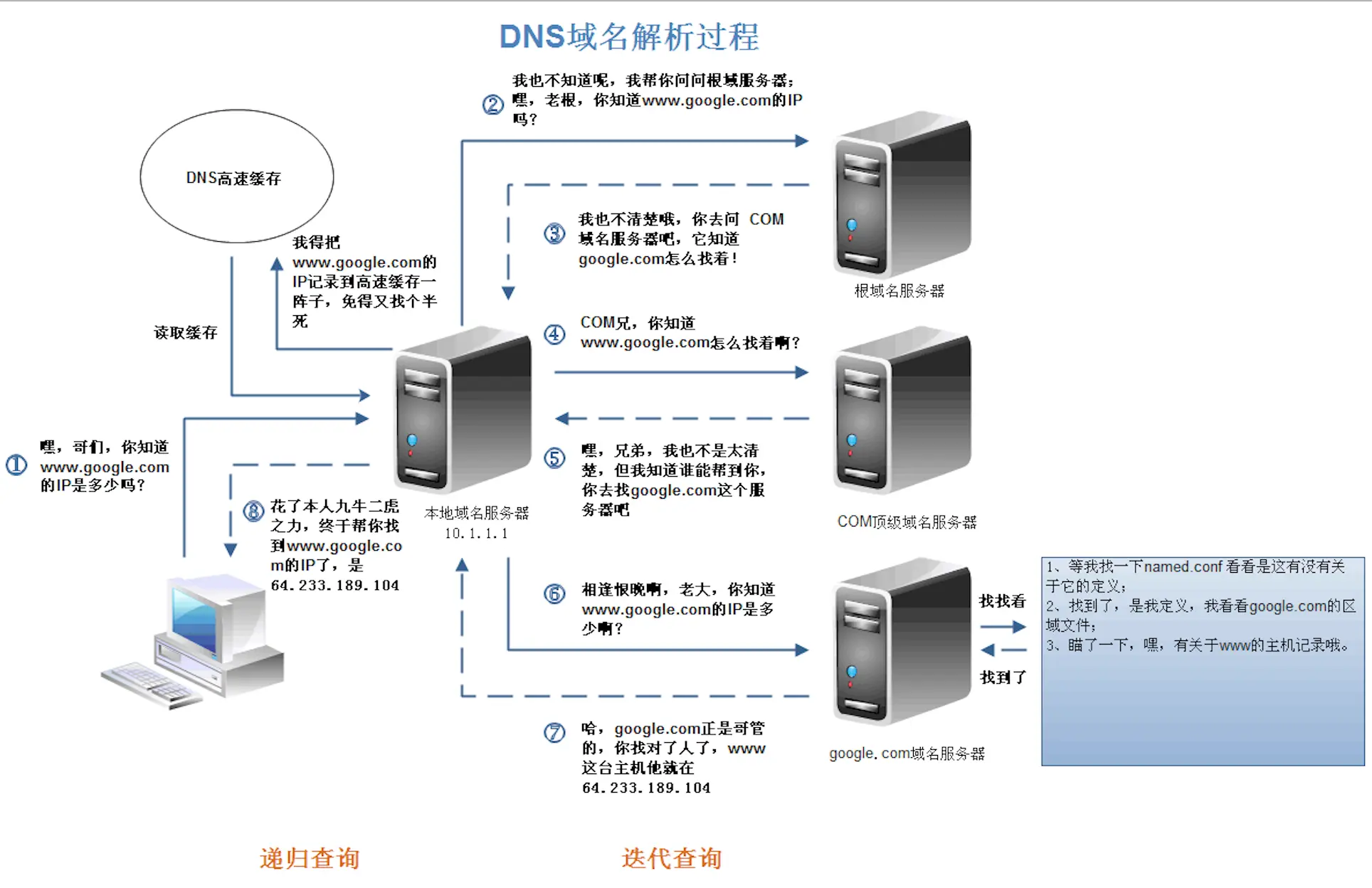
I/O多路复用
多线程虽然可以很容易处理并发,但也存在缺点:如数据竞争,同步,模型复杂等。Nginx采用单线程的方式,没有互斥锁,减少系统消耗,其利用了Linux内核的I/O多路复用接口epoll()。
Web服务器主要是“I/O密集型”而不是“CPU密集型”。一般的单线程处理,就会导致CPU“停下来”等待I/O,造成浪费。epoll让Nginx能把多个HTTP请求打散,都复用到一个单线程里,不按照先来后到,只有当连接真正可读可写才处理。如果阻塞,就立刻切换去处理其他请求。
epoll还有个特点是,大量连接管理都是在操作系统内核做的,减轻应用程序负担,每个连接仅仅需要很小的内存维护状态。
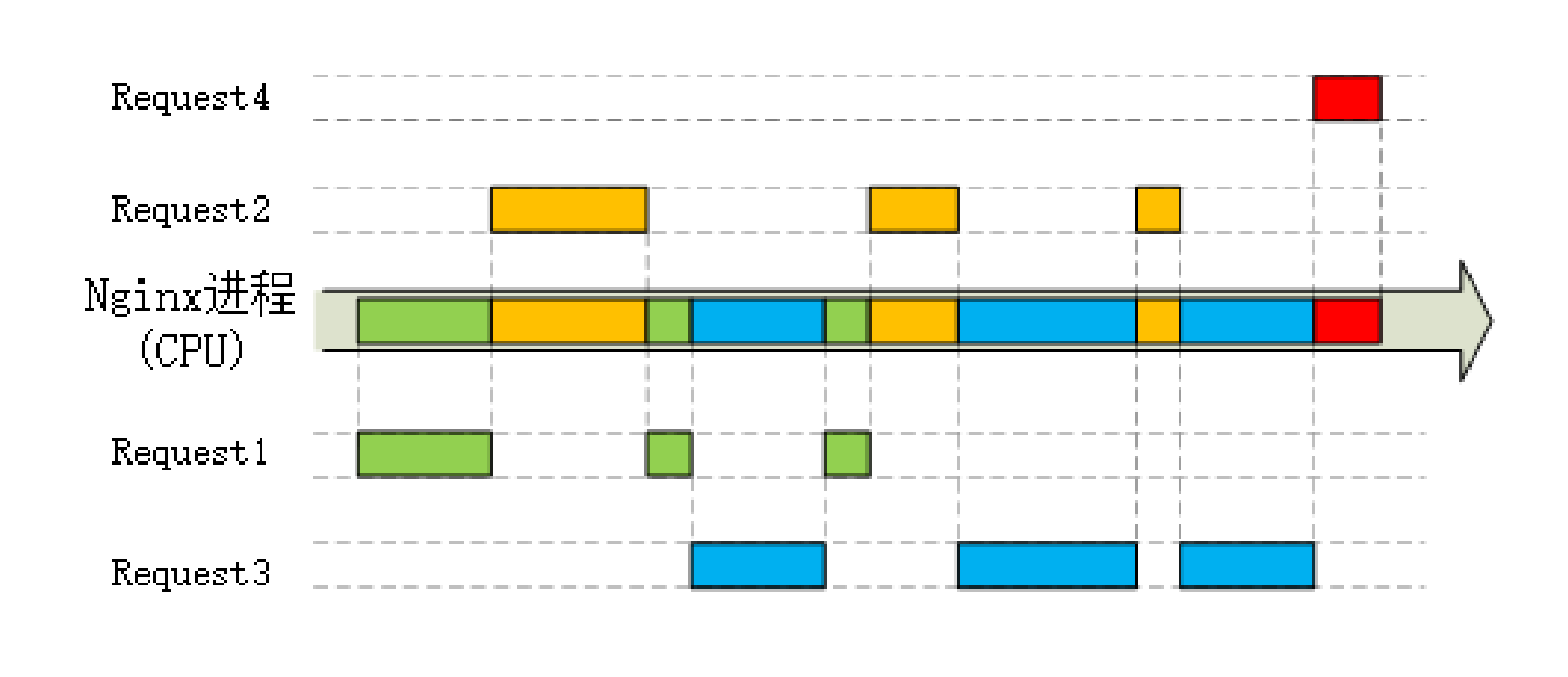
多阶段处理 - 责任链模式
HTTP处理的四大类模块:
- handler 模块:直接处理 HTTP 请求;
- filter 模块:不直接处理请求,而是加工过滤响应报文;
- upstream 模块:实现反向代理功能,转发请求到其他服务器;
- balance 模块:实现反向代理时的负载均衡算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号