Redis - 切片集群
扩容的思路
- 纵向扩展 scale up: 一台8G的变成一台24G的
👍 简单
👎 受硬件条件的限制
👎 单机容量大对性能的影响,如Redis的fork操作耗时是和内存数据量正相关的 - 横向扩展 scale out: 一台8G的变成3台8G的
👍 扩容灵活,不会增大单机的存储
👎 机制复杂,包括如何片键分片,避免热片,如何保证通信连接,数据聚合等等
以下主要讲的是Redis Cluster即Redis集群横向扩展的方式。
数据在哪个实例上?
Redis把数据分成了16384个哈希槽(Slot),通过CRC16(Key)%16384来获取数据应该放在哪个槽。而分片集群,就是把这些槽均匀分布在不同实例上。
例如,如果是有两个主节点的分片集群,那么主1存0-8191号slot,主2存8192-16383号slot;如果是4个主节点的分片集群,主1存0-4095,主2存4096-8191,主3存8192-12287,主4存12288-16383。
部署
集群模式部署的Redis实例如下:
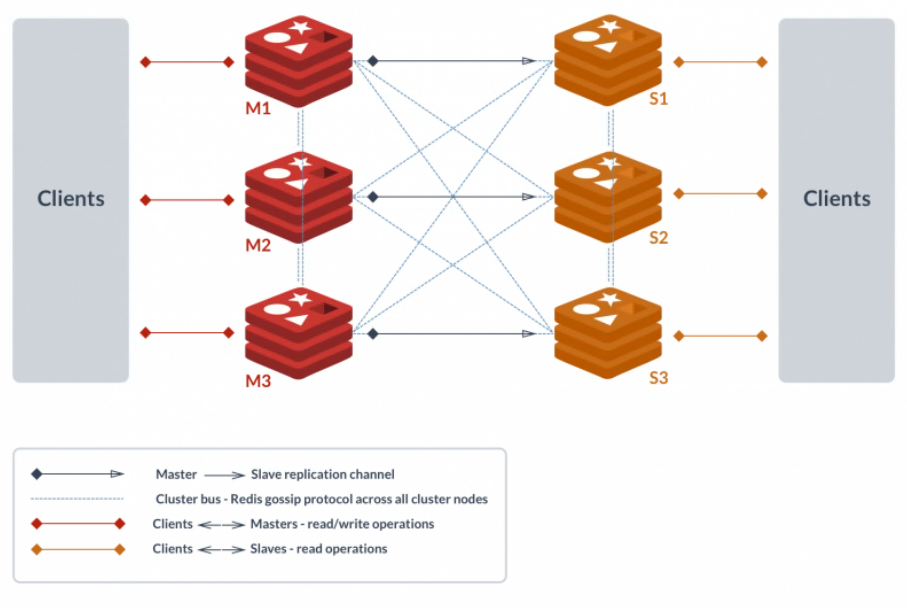
重定向
Redis主节点会互相知道各自存的slot映射关系,客户端也会缓存一份这个哈希槽的映射关系在本地,那么当一个命令(例如get)出现时,客户端可以自己计算键所对应的哈希槽号,然后直接向存该槽的数据节点发送命令。
但是这个映射关系会在1.集群变化,如扩缩容2.负载均衡优化,重新分布slot时,改变。如果客户端缓存的映射和实际的不一致,就要靠Redis提供的重定向机制来保证,假如客户端像实例1请求数据,实例1发现这个数据其实是在实例2上,就会回复客户端MOVED 哈希槽号 实例2HOST。如果请求时,正在发生数据迁移,那么会回复一个ASK 哈希槽号 实例2HOST给客户端,表明需要后续再确认。
无中心化
Redis Cluster采用的无中心化模式(无Proxy,客户端与数据节点直连,这和我们在Mongodb看到的Mongos不一样),所以就存在数据节点纠正客户端路由表的能力,和数据节点之间交换路由表的能力。使用哈希槽的方式是为了简化这个路由映射表,减少该表的存储空间,便于扩缩容,负载均衡,数据迁移等。
中心化方案
其他Redis集群化方案如Codis,Twemproxy都是中心化模式(增加Proxy层,像mongos一样的),让客户端操作Redis集群像操作一个Redis实例一样,增加Proxy也势必带来性能的损耗。



