Hive表 Hadoop HBase 初了解
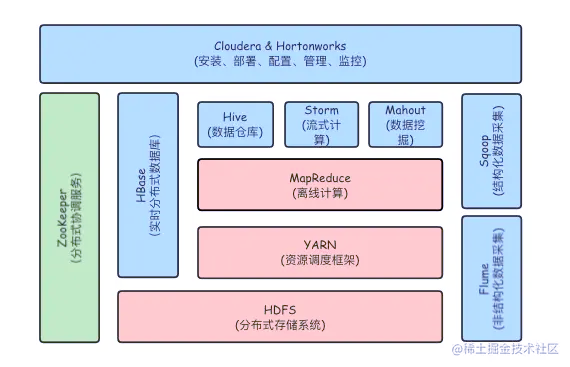
生态圈
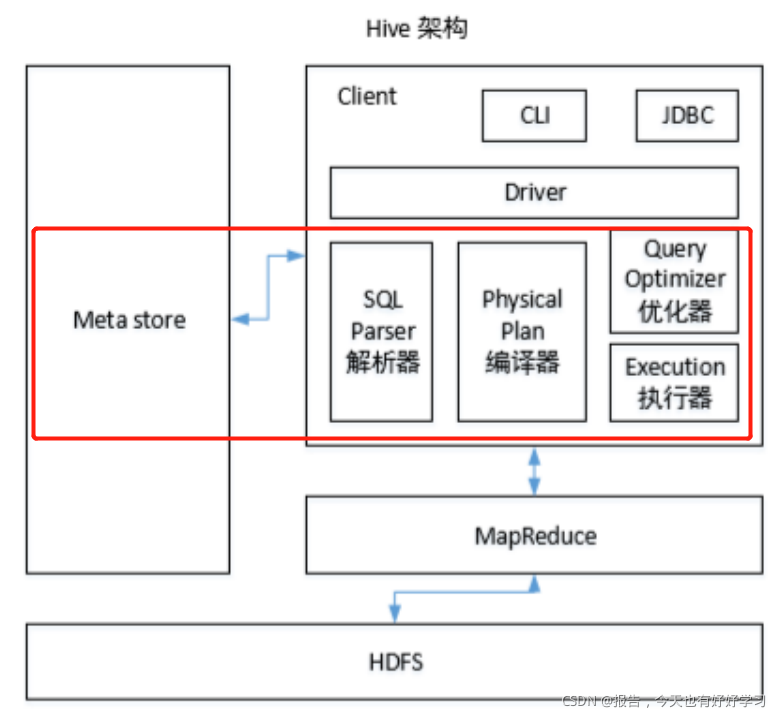
Hive
Hive是基于Hadoop的一个数据分析工具,没有数据存储能力,只有数据使用能力,是将结构化的数据文件映射为一张数据库表,通过MapReduce实现,本质是将查询语句转换为MapReduce的任务进行数据访问,提供类SQL查询功能。
搭建Hive数仓时,将相关常用指令如select, from, where和函数用MapReduce写成模板,封装到Hive中。不直接使用MapReduce是因为MapReduce学习成本较高,开发难度大。红圈里的是Hive的部分,Hive主要用于海量数据的离线分析场景:
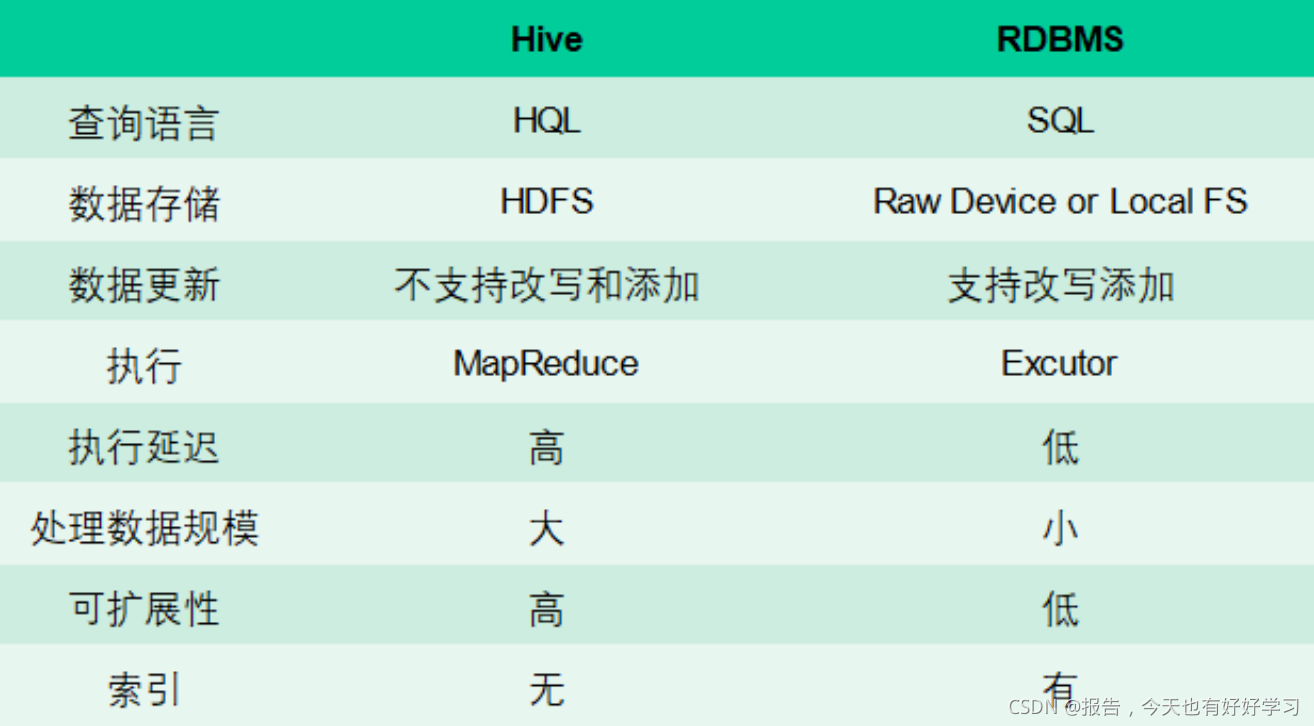
Hive & 关系型数据库管理系统
Hadoop
Hadoop = HDFS(文件系统) + MapReduce(数据处理) + YARN(资源协调器)。
HDFS
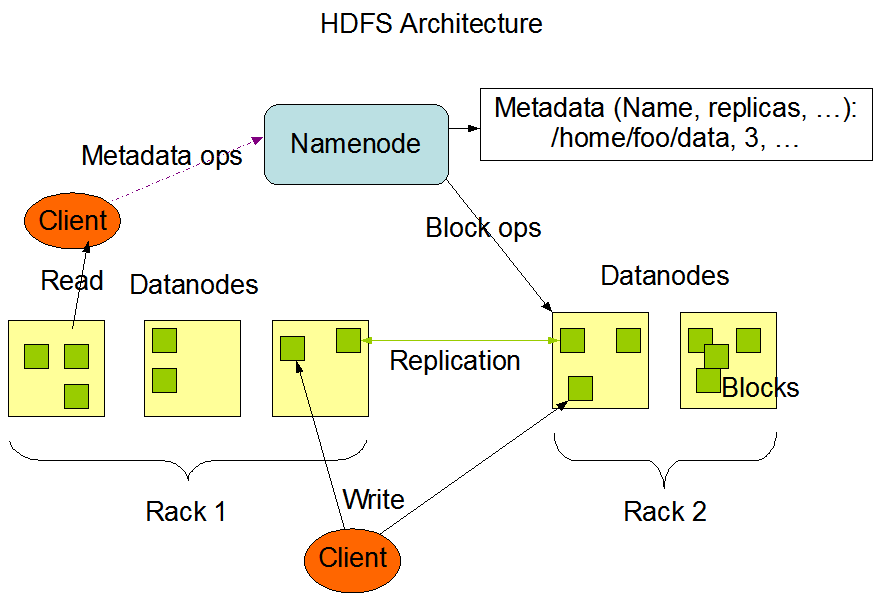
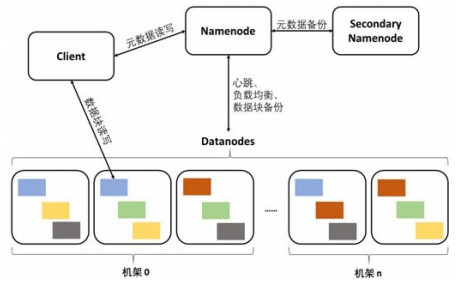
HDFS采用主从架构,由单个NameNode(NN)和多个DataNode(DN)组成。
- NameNode负责管理命名空间,管理元数据,管理Block副本策略(每个副本在不同DataNode), 处理客户端读写请求,为DataNode分配任务,监控和管理DataNode, 如果DataNode宕机,会进行移除和Rebalance。
- DataNode负责文件数据的存储和读写,HDFS将文件数据分割成若干数据块(Block),每个DataNode存储一部分数据块,这样文件就分布存储在整个HDFS服务器集群中。
- Block是HDFS最小存储单元,大小固定,默认一个Block有三个副本。
MapReduce
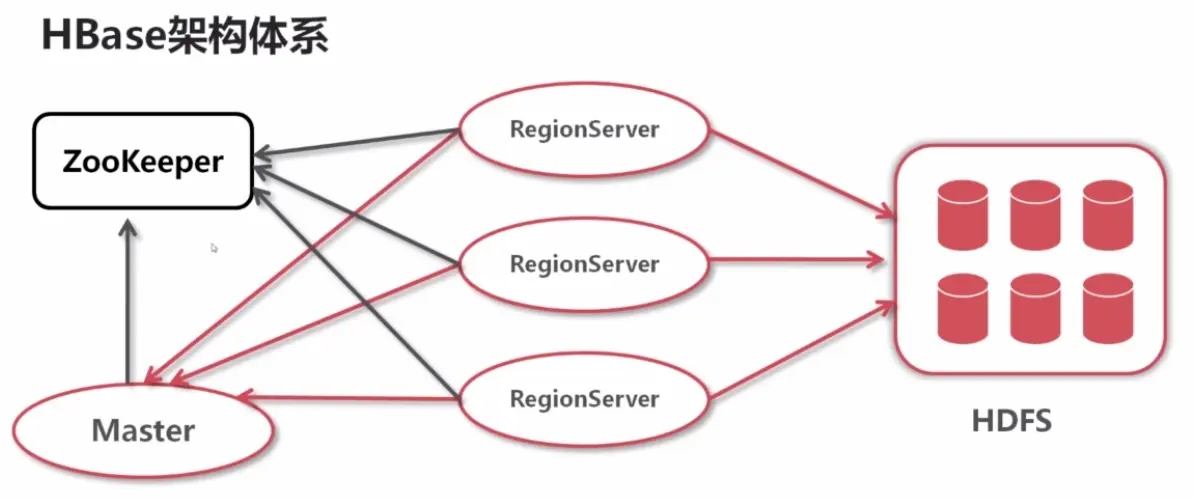
HBase
HBase是一种NoSQL数据库 todo