Clickhouse原理解析
Clickhouse的标签 #OLAP #列式存储
行式数据库和列式数据库适用于不同的业务场景:
- 如何查询
- 多久查一次
- 各类查询的比例
- 各类查询要求的延迟和吞吐量
- 每种查询读取多少数据
- 读和写的关系,比例
- 数据集的大小
- 如何使用本地数据集
- 是否用事务
- 数据复制和完整性的要求
OLAP
OLAP的特点
对于OLAP的场景,有几个关键特征:
- 绝大多数请求是读请求
- 数据以大的批次(>1000)更新,或者根本没有更新
- 已经入库的数据不能修改
- 读数据总是提取相当多的行但是列的一小部分
- 宽表 大量的列
- 查询少
- 列的数据相对较小
- 处理单个查询需要高吞吐量,每台每秒十亿行+
- 事务不必须
- 数据一致性要求低
- 每个查询有一个大表,其他的都很小
- 查询结果明显小于源数据,适合于单个服务器的RAM中
输入/输出:
- 分析类查询通常只读取宽表的一小部分列,例如读取100列中的5列,列式数据库可以减少20倍的IO消耗。
- 数据总是打包成批量,压缩变得容易,数据按照列存储也更容易压缩,降低了IO的体积
- IO降低,更多数据能被系统缓存
OLAP的架构
OLAP架构分为三类:
- R OLAP (Relational OLAP),即直接使用关系模型构建,数据模型通常是星型或雪花模型。这类架构对数据的实时处理能力要求很高。
- M OLAP (Multidimensional OLAP), 它是为了缓解ROLAP的性能问题。MOLAP使用多维数据组的形式保存数据,其核心思想是借助预先聚合结构,使用空间换取时间的形式来提升查询性能。这个架构的缺点是,维度预处理可能会导致数据的膨胀。且一般只保留聚合后的结果导致无法查询明细数据。
- H OLAP(Hybrid OLAP),即上两者的混合。
以ROLAP为例,传统关系型数据库就被Hive和SparkSQL这类新兴技术取代。但仍然太慢了。MOLAP架构也依托MapReduce或Spark这类新兴技术,作为数据立方体的计算引擎,其预聚合结果的存储载体也转向HBase这类高性能分布式数据库。主流MOLAP架构已经能在亿万级数据的体量下,实现毫秒级查询响应。MOLAP也仍然存在维度爆炸,数据同步实时性不高的问题。
除了ROLAP,MOLAP两类方案以外,也有另辟蹊径的选择,即直接使用搜索引擎实现OLAP查询,如ElasticSearch。在百万级别数据的场景下,ES能支持实时聚合查询,但数据体量增大,性能也捉襟见肘。
另外一条路就是ClickHouse。其具有ROLAP,在线实时查询,完整的DBMS,列式存储,不需要任何数据预处理,批量更新,完善的SQL和函数,支持高可用,不依赖Hadoop复杂生态,开箱即用。
ClickHouse的前世今生
todo
ClickHouse不适用的场景
- 不支持事务
- 不擅长根据主键按行粒度查询,不应作为k-v用
- 不擅长按行删除数据
ClickHouse的核心特性
ClickHouse是一款MPP(Massive Parallel Processing)架构的列式存储数据库。
完备的DBMS功能
- DDL 动态创建修改删除数据库,表和视图,无需重启
- DML 动态查询,插入,修改或删除数据
- 权限控制
- 数据备份与恢复,提供了数据备份导入导出恢复机制
- 分布式管理
列式存储与数据压缩
想让查询变得更快,最简单有效的方法就是减少数据扫描范围和数据传输时的大小。按列存与按行存比可以有效地减少扫描数据量:
假设一张数据表A拥有50个字段A1~A50,以及100行数据。现在需要查询前5个字段并进行数据分析,则可以用如下SQL实现:
SELECT A1,A2,A3,A4,A5 FROM A
如果数据按行存储,数据库首先会逐行扫描,并获取每行数据的所有50个字段,再从每一行数据中返回A1~A5这5个字段。不难发现,尽管只需要前面的5个字段,但由于数据是按行进行组织的,实际上还是扫描了所有的字段。如果数据按列存储,就不会发生这样的问题。由于数据按列组织,数据库可以直接获取A1~A5这5列的数据,从而避免了多余的数据扫描。
按列存储的另一个优势是对数据压缩的友好性。压缩的本质是按照一定步长对数据进行匹配扫描,发现重复部分就进行编码转换,如,对abcdefghi和bcdefghi进行压缩,(9,8)表示从下划线往前移动9个字节会匹配8个字节的重复数据。
压缩前:abcdefghi_bcdefghi
压缩后:abcdefghi_(9,8)
压缩的实质就是,数据中的重复项越多,压缩率就越高,数据体量就越小。数据体量越小,则数据在网络中的传输越快,对网络带宽和磁盘IO的压力也就越小。同一列字段重复项的可能性高。Clickhouse数据默认使用LZ4算法压缩,数据总体压缩比可以达到8比1,列式存储除了降低IO和存储压力以外,也为向量化执行做好了铺垫。
向量化执行引擎
向量化执行可以简单看做一项消除程序中循环的优化。为了实现向量化执行,需要利用CPU的SIMD(Single Instruction Multiple Data)指令,它是在CPU寄存器层面实现数据并行操作。ClickHouse目前利用SSE4.2指令集实现向量化执行。
关系模型与SQL查询
关系模型相比文档和键值对等其他模型,拥有更好的描述能力,能够更加清晰地表述实体间的关系。在OLAP领域,已有的大量数据建模工作都是基于关系模型展开的。
多样化的表引擎
多线程与分布式
由于SIMD不适用于带有较多分支判断的场景,ClickHouse也大量使用了多线程技术来提速,与向量化执行形成互补。ClickHouse在数据存取方面,既支持分区(纵向扩展,利用多线程原理),也支持分片(横向扩展,利用分布式原理)。
多主架构
HDFS,Spark,HBase和Elasticsearch这类分布式系统,都采用了Master-Slave主从架构,由一个主节点作为leader统筹全局。而ClickHouse采用Multi-Master多主架构,集群中的每个节点角色对等。多主架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,规避了单点故障问题,非常适合与多数据中心,异地多活的场景。
在线查询
即便在复杂查询的场景下,也能够做到极快响应,无需对数据进行任何预处理加工。
数据分片与分布式查询
数据分片是一种分治思想的体现,将数据进行横向切分,ClickHouse支持分片,分片依赖集群,每个集群由1个到多个分片组成,每个分片对应一个服务节点。ClickHouse不像其他分布式系统那样,可以高度自动化分片。它提供了本地表(Local Table)和分布式表(Distributed Table)的概念,一张本地表等于一份数据的分片。分布式表本身不存任何数据,它是本地表的访问代理,作用类似于分库中间件。借助分布式表可以代理访问多个数据分片,实现分布式查询。分布式表读,本地表写。
ClickHouse的架构设计
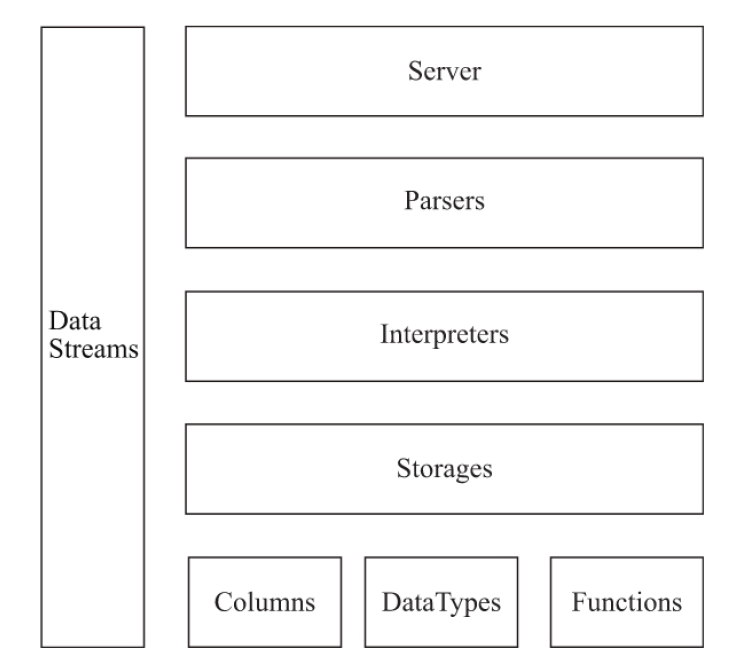
- Column & Field
Column和Field是ClickHouse数据最基础的映射单元,按列存储数据,一列数据由一个Column对象表示。如需操作单列中的一行数据,则需要使用Field对象,Field对象代表一个单值。 - DataType
数据的序列化和反序列化工作由DataType负责。 - Block与Block流
Block对象可以看做数据表的子集。Block对象本质是由数据对象,数据类型和列名称组成的三元组,即Column, DataType以及列名称字符串。IBlockInputStream和IBlockOutputStream负责数据的读取和关系运算。 - Table
底层设计中没有所谓的Table对象,直接使用IStorage接口指代数据表 - Parser与Interpreter
Parser分析器分组创建AST对象(Abstract Syntax Tree 抽象语法树),Interpreter负责解释AST,并进一步创建查询的执行管道。他们与IStorage一起,串联整个数据查询的过程。Parser分析器可以将一条SQL语句以递归下降的方法解析成AST语法树的形式。不同SQL语句,会经由不同Parser实现类解析。Interpreter会首先解析AST对象,然后执行业务逻辑(分支判断,设置参数,调用接口等),最终返回IBlock对象,以线程的形式建立一个查询执行管道。 - Functions与Aggregate Functions
ClickHouse提供普通函数和聚合函数。普通函数例如四则运算,日期转换,网址提取,IP脱敏等,是没有状态的,采用向量化的方式作用于一整列数据。聚合函数是有状态的,支持序列化和反序列化,能够在分布式节点之间进行传输,以实现增量计算。 - Cluster & Replication
ClickHouse的集群由分片(shard)组成,每个分片又通过副本(Replica)组成。与一些流行的分布式系统相区别的是,ClickHouse1个节点只能拥有一个分片,即,如果要实现1分片1副本,至少要部署2个节点。
ClickHouse为什么快
着眼硬件
基于将硬件功效最大化的目的,ClickHouse会在内存中进行Group BY,并使用HashTable装载数据。同时,他们很在意CPU L3级别的缓存,在一个一个细节上做到最优。
特性算法 特殊优化
例如,在字符串搜索方面,针对不同场景,ClickHouse选择了不同算法,对常量,使用Volnitsky算法,对于非常量,使用CPU的向量化执行SIMD,暴力优化;正则匹配使用re2和hyperscan算法。对不同场景也进行不同的针对性优化,例如去重计数uniqueCombined函数,会根据数据量不同选择不同算法,数据较少时,选择array保存;数据量中等时,选择hashset;数据量很大时,使用HyperLogLog算法。
最佳实践
分区表
数据分区是针对本地数据而言的纵向切分,借助数据分区,查询过程中跳过不必要的目录提升查询性能。
分布式DDL执行
将普通DDL语句转换成分布式执行,只需要加上ON CLUSTER cluster_name即可。集群中的每个节点都会以相同的顺序执行相同的语句。
数据删除与修改
DELETE和UPDATE这类操作被称为Mutation查询,Mutation语句是一种“很重”的操作,更适用于批量数据修改和删除,不支持事务,一旦被提交执行,会立刻对现有数据产生影响,无法回滚,并且它是一个异步后台过程,语句被提交后就会立即返回,执行的具体进度要通过System.mutations系统表查询。
删除的过程:
每执行一次DELETE语句,都会在mutations系统表生成一条对应的执行计划,当is_done字段为1时表示执行完成。同时,在数据表的根目录下,会以mutation_id为名生成与之对应的日志文件用于记录相关信息。数据删除的过程是以数据表的每个分区目录为单位,将所有目录重写为新的目录,新目录命名规则是在原有名称上加上system.mutations.block_numbers.number。数据在重写过程中会将需要删除的数据去掉。旧目录不会被立刻删除,而是标记为非激活状态,等MergeTree引擎下一次合并动作触发时,才会被物理删除。
数据字典
数据字典是ClickHouse提供的一种简单实用的存储媒介,以键值和属性映射的形式定义数据。字典中的数据会主动或者被动加载到内存,支持动态更新。由于字典数据常驻内存的特性,适合保存常量或经常使用的维度表数据,避免不必要的JOIN查询。
表引擎

MergeTree
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。
创建MergeTree数据表
PARTITION BY
选填,分区键,指定数据以何种标准进行分区,可以是单个列字段,可以是多个列字段,也支持列表达式。若不声明分区键,则ClickHouse会生成一个名为all的分区。
ORDER BY
必填,排序键,指定一个数据片段内,数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同,可以为单列或多列字段。
PRIMARY KEY
选填,主键,声明后会根据主键字段生成一级索引加速表查询,默认情况下,主键与排序键相同,所以直接通过使用ORDER BY为指定主键。与其他数据库不同的是MergeTree主键允许重复数据(ReplacingMergeTree可以去重)
SAMPLE BY
选填,抽样表达式,声明数据以何种标准进行采样。如果有使用,需要在主键配置中声明同样表达式,抽样表达式需要配合SAMPLE子查询使用。
SETTINGS
index_granularity选填,这是一个非常重要的参数,表示索引的粒度,默认值是8192,即默认情况,每间隔8192行数据才生成一条索引。
MergeTree存储结构
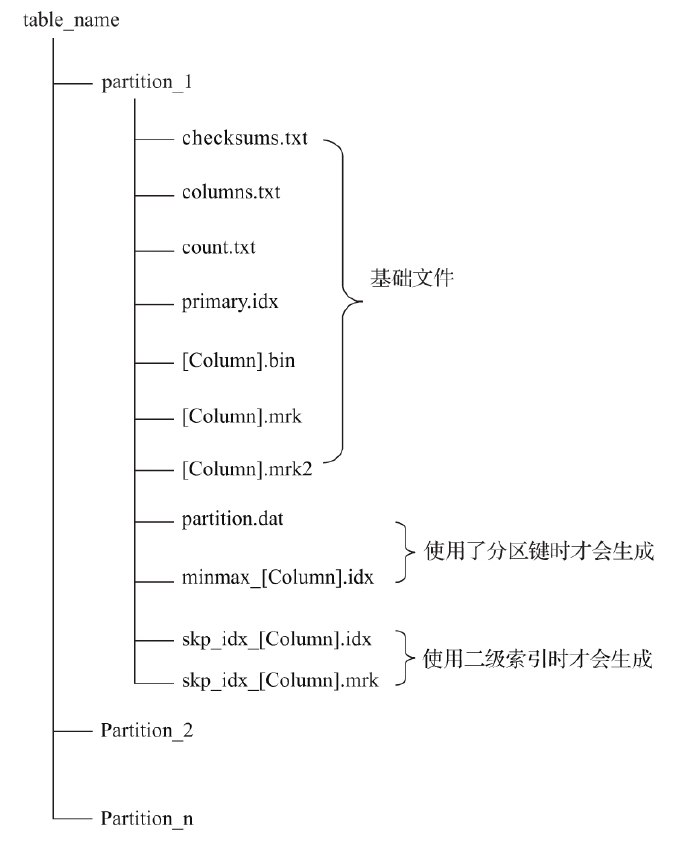
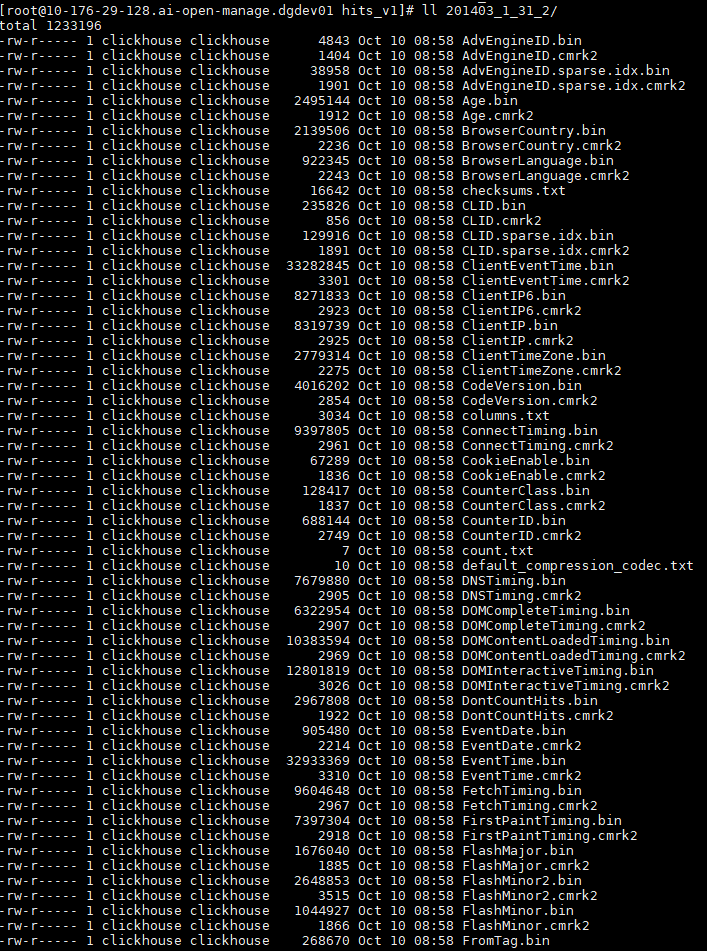
- partition 分区目录,相同分区数据最终会合并到一个目录,不同分区数据不会合并在一起。
- checksums.txt 校验文件,二进制存储。保存了各个文件的size和size的hash,校验文件的完整和正确性
- columns.txt列信息文件,明文存储
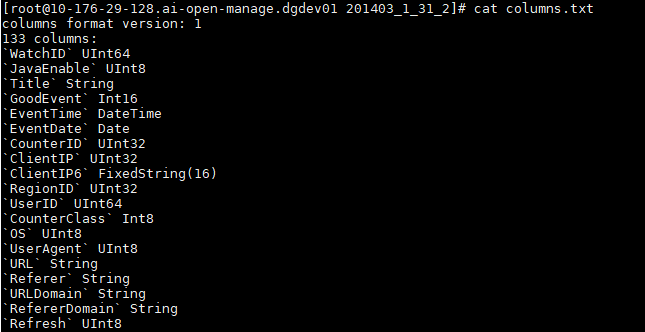
- count.txt 计数文件,当前分区数据总行数,明文存储

- primary.idx 一级索引,二进制存储,存放稀疏索引
- [column].bin 数据文件,默认LZ4压缩格式存储
- [column].mrk 列字段标记文件,二进制存储,保存了.bin文件数据的偏移量信息。标记文件与稀疏索引对齐,又和.bin文件一一对应,所以标记文件建立了primary.idx稀疏索引和.bin数据文件之间的映射关系。先通过primary.idx找到数据的偏移量信息.mrk,再通过偏移量直接从.bin文件读取数据
- [column].mrk2 如果使用了自适应大小的索引间隔,则标记文件以.mrk2命名。工作原理和作用与.mrk标记文件相同。
- partition.dat与minmax_[column].idx,如果使用了分区键,则额外生成partition.dat和minmax索引文件,二进制存储。partition.dat保存当前分区下分区表达式最终生成的值,minmax索引记录当前分区下分区字段对应原始数据的最大最小值。
- skp_idx_[column].idx 与skp_idx_[column].mrk,如果建表时声明了二级索引,则会额外生成相应的二级索引与标记文件。二级索引又叫做跳数索引,目前拥有minmax,set,ngrambf_v1,tokenbf_v1四种类型。
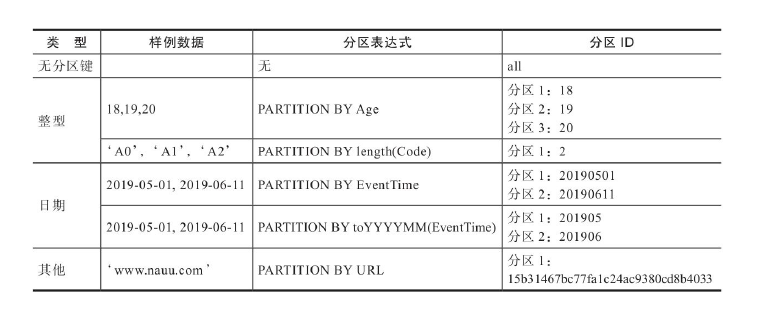
数据分区的规则
MergeTree数据分区的规则由分区ID决定,
- 不指定分区键,分区ID默认为all,所有数据写入这个目录
- 使用整型,直接按照该整型的字符串形式输出作为分区ID的取值
- 使用日期类型,按照YYYYMM等格式字符串作为分区ID
- 使用其他类型,不属于整型和日期,则通过128位Hash算法取其Hash值作为分区ID
- 若分区键是多个列,则通过每个的列对应的分区ID用中短线依次拼接
分区目录
分区目录并不只是分区ID,而是后面有一串数字:
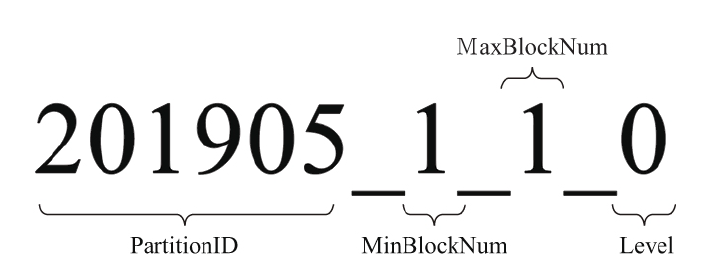

1_1表示最小数据块编号和最大数据块编号,_0表示目前合并的层级即被合并过的次数。
合并过程中:
- MinBlockNum,取同一分区内所有目录中最小的MinBlockNum值
- MaxBlockNum,取同一分区内所有目录中最大的MaxBlockNum值
- Level取同一分区内最大的Level值并加1
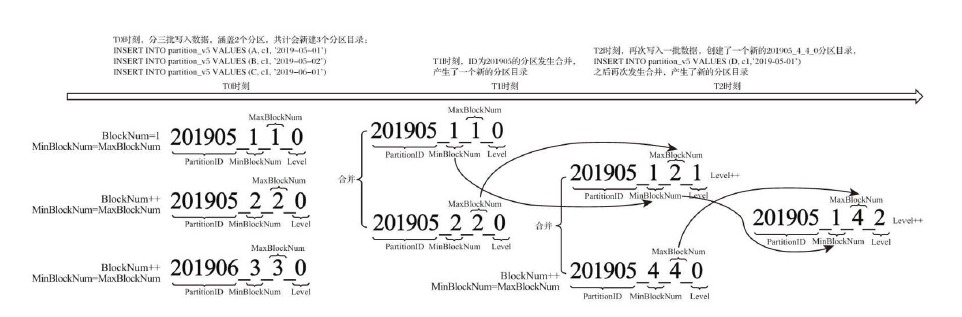
一级索引
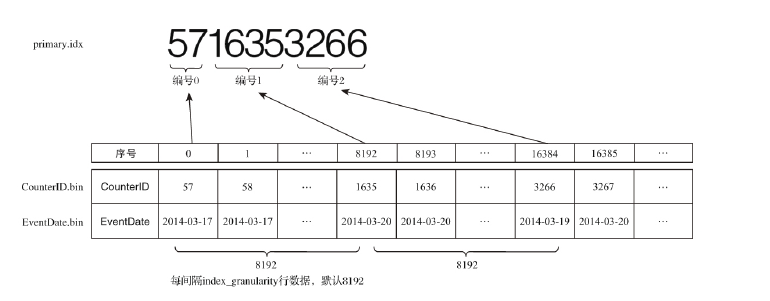
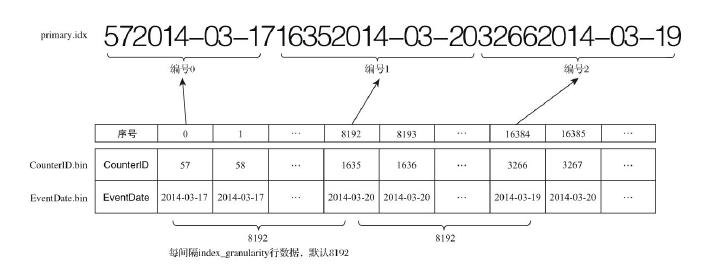
主键定义后根据index_granularity间隔为数据表生成一级索引保存到primary.idx文件,索引数据按照primary key排序。一级索引采取稀疏索引实现,由于稀疏索引占用空间小,所以索引数据常驻内存。
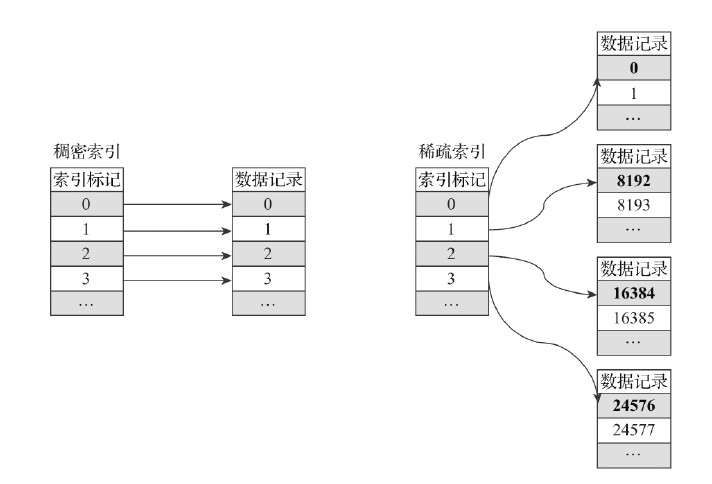
索引数据生成规则:
索引查询过程
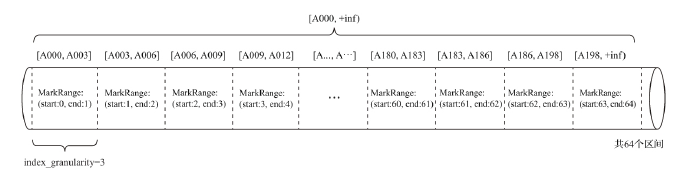
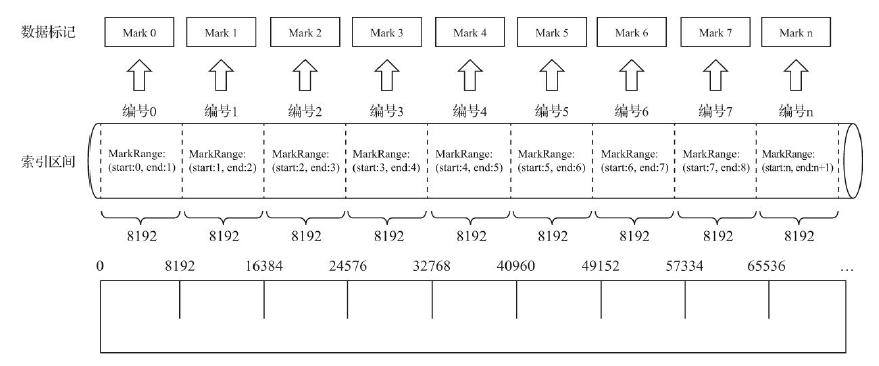
有一份测试数据共192条记录,主键为string类型,从A000到A191, MergeTree的索引粒度index_granularity=3,根据索引生成规则,primary.idx的物理存储如下:

根据索引数据,MergeTree会将此数据片段划分成192/3=64个MarkRange,相邻步长为1,如下图:
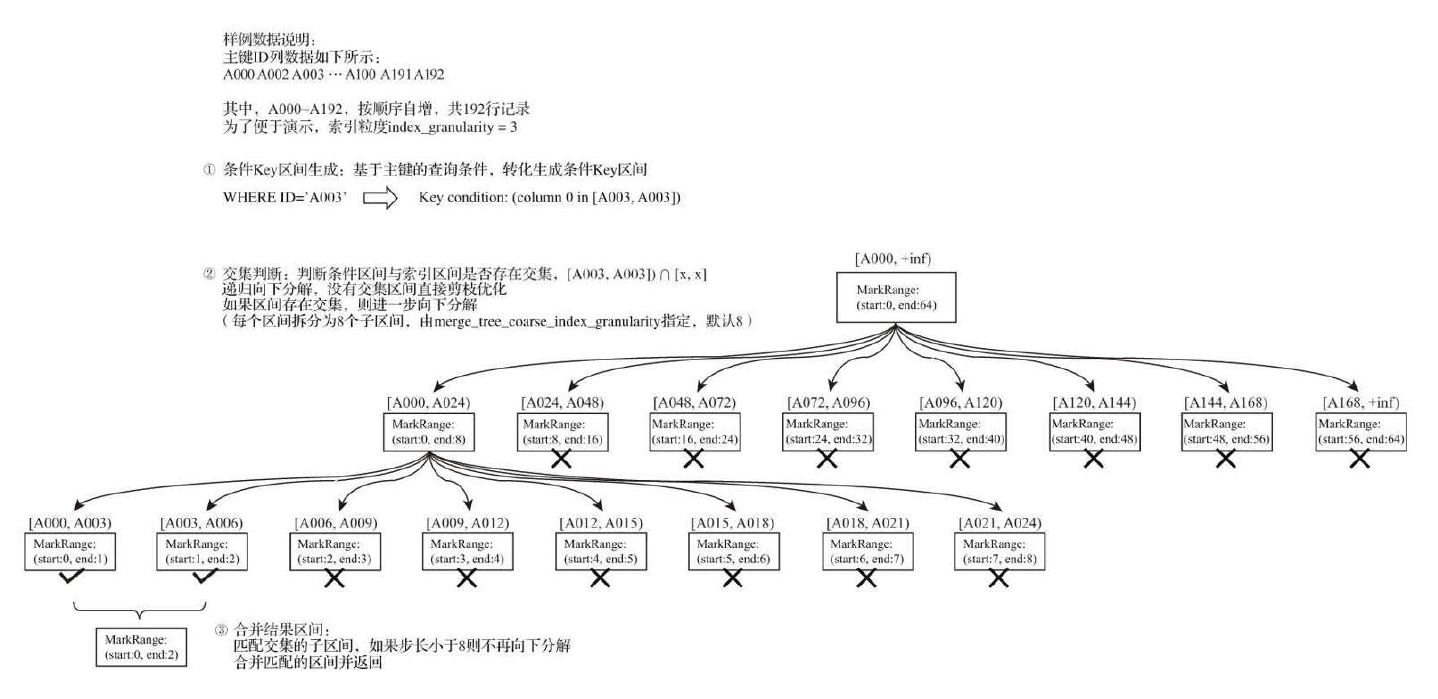
索引查询步骤:
- 生成查询条件区间。如
where ID = 'A003'-> ['A003', 'A003'],ID > 'A000'-> ('A000', +inf) - 递归交集判断
- 合并MarkRange区间
如下图,判断的步长为8,由merge_tree_coarse_index_granularity指定
二级索引
MergeTree支持二级索引,跳数索引。建表时需要声明跳数索引,索引声明后会额外生成相应的索引与标记文件(skp_idx_[column].idx与skp_idx_[column].mrk)。对跳数索引而言,index_granularity定义了数据的粒度,granularity定义了聚合信息汇总的粒度即granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。如下图的minmax跳数索引:

MergeTree目前支持4种跳数索引,分别是minmax,set,ngrambf_v1,tokenbf_v1:
- minmax 记录一段数据内的最小和最大值
- set set索引直接记录字段的取值,完整形式是
set(max_rows),表示在一个index_granularity内,索引最多记录的行数,如果max_rows=0,则表示无限制。 - ngrambf_v1 数据短语的布隆表过滤器,只支持String和FixedString类型。ngrambf_v1只能提升in,notIn,like,equals和notEquals查询性能,完整表达式为
ngrambf_v1(n,size_of_bloom_filter_in_bytes,number_of_hash_functions,random_seed),n为根据n的长度将数据切割为token短语,其他是布隆过滤器参数 - tokenbf_v1是ngrambf_v1的变种,同样也是一种布隆过滤器索引,只是token的处理方法不一样
数据存储
首先数据是经过压缩,默认LZ4算法,其次,数据会事先按照ORDER BY的声明排序,最后,数据是以压缩数据块的形式被组织并写入.bin文件中的。
压缩数据块
一个压缩数据块由头信息和压缩数据两部分组成。头信息有9位字节,1个UInt8和2个UInt32,分别代表使用的压缩算法类型,压缩后数据大小和压缩前数据大小。每个压缩数据块的体积按照其压缩前的数据字节大小,被严格控制在64KB-1MB,上下限分别由min_compress_block_size默认65536和max_compress_block_size默认1048576参数指定。写入过程遵循,如果单批次数据<64KB,则继续获取下一批数据,直到>=64KB,生成下一个压缩数据块。单批次位于64KB-1MB,直接生成压缩数据块,单批次>1MB,截断1MB大小,剩下数据继续按此规则执行。
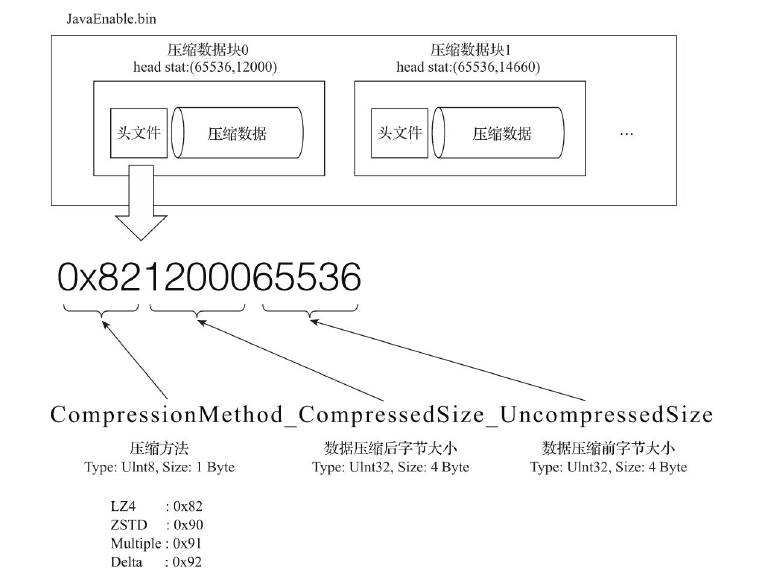
压缩和解压的动作本身有性能损耗,所以需要控制被压缩数据的大小,以求在性能损耗和压缩率之间的平衡。读取某列数据时,需要将压缩数据加载到内存并解压,通过压缩数据块,可以在不读取整个.bin文件的情况下将读取粒度降低到压缩数据块级别。
数据标记
数据标记(.mrk)是衔接一级索引(primary.idx)和数据(.bin)的桥梁,数据标记和索引区间是对齐的,也和.bin文件一一对应。一行标记数据包含两个整型数值的偏移量信息。分别表示在此段数据区间内在对应的.bin压缩文件中,压缩数据块的起始偏移量,和压缩块解压后其未压缩数据的起始偏移量。标记数据与一级索引不同,并不常驻内存,而是使用LRU缓存策略加快其取用速度。
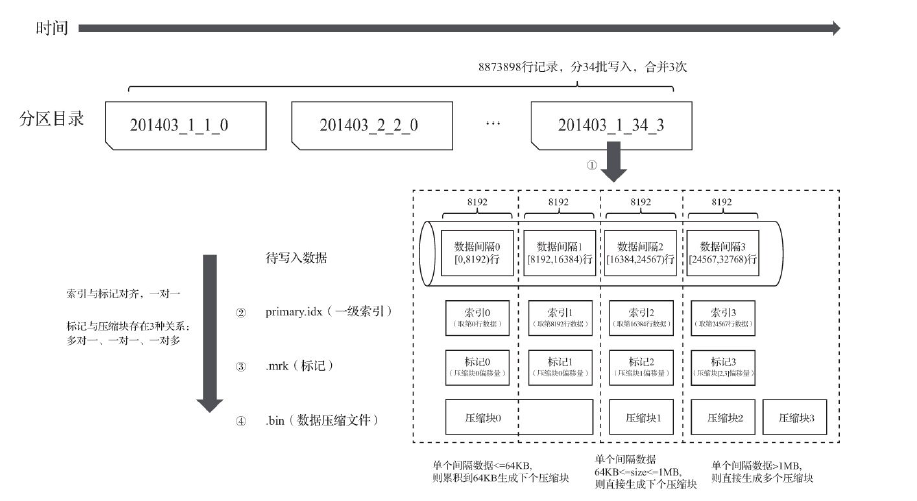
完整的写入过程:
查询过程:
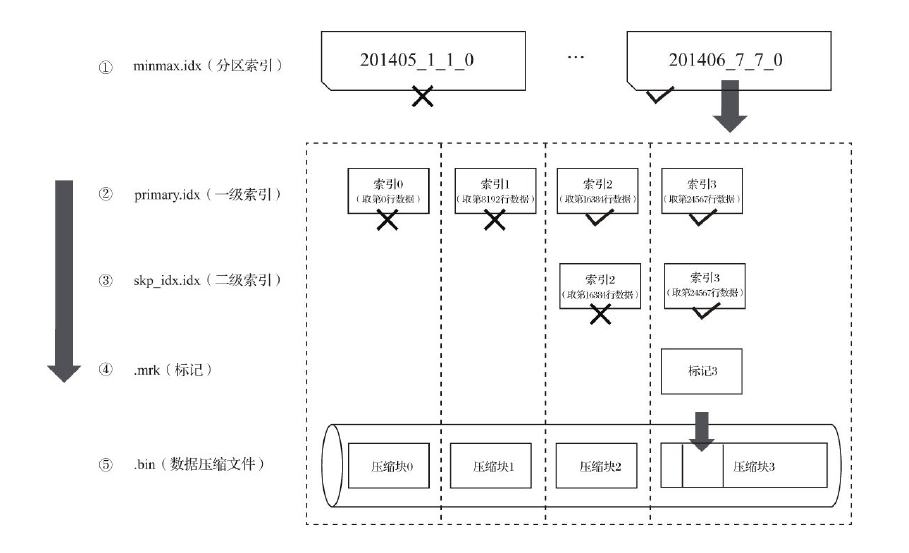
如果一条查询语句没有指定任何WHERE条件,或是指定了WHERE条件,但条件没有匹配到任何索引,就不能预先减少数据范围。在后续查询的时候会扫描所有分区目录和目录内索引段的最大区间。虽然不能减少数据范围,但是MergeTree仍然能借助数据标记,多线程的形式同时读取多个压缩数据块,以提升性能。
MergeTree系列表引擎
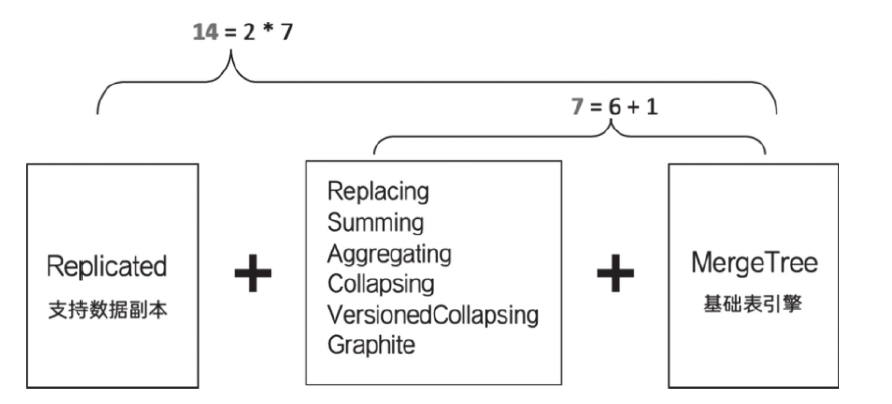
ReplacingMergeTree
MergeTree虽然有主键,但它的主键却没有唯一键的约束。ReplacingMergeTree就是这种背景下为了数据去重而设计的,它能在合并分区时删除重复数据。ORDER BY是去除重复数据的依据而非PRIMARY KEY。但是ReplacingMergeTree是以分区为单位删除重复数据的,只有在相同的数据分区内重复的数据才可以被删除,不同数据分区之间的重复数据依然不能被剔除,且只有在合并分区的时候才会触发删除重复数据的逻辑。
SummingMergeTree
对于不需要明细数据,只关注查询数据的归总结果的场景。它能在合并分区时,按照预先定义的条件根据ORDER BY的定义聚合汇总数据,将同一分组下的多行数据汇总合并成一行,既减少了数据行,又降低了后续汇总查询的开销。
一般情况下ORDER BY和PRIMARY KEY取值相同,不必单独声明PRIMARY KEY。如果需要同时定义ORDER BY 和PRIMARY KEY,通常只有一种可能,就是明确希望这两者不同,这种情况通常在使用SummingMergeTree或AggregatingMergeTree时才会出现。因为SummingMergeTree和AggregatingMergeTree的聚合都是根据ORDER BY进行的,主键与聚合条件定义分离,为聚合条件留下空间。
如果同时声明了ORDER BY与PRIMARY KEY,MergeTree会强制要求PRIMARY KEY列字段必须是ORDER BY的前缀。这种约束保证了即时两者定义不同的情况下,主键是排序键的前缀,不会出现索引与数据顺序混乱的问题。同理,该汇总逻辑也只会在合并分区的时候触发,同一分区数据会汇总,不同分区不会汇总。汇总字段会使用SUM计算,非汇总字段会根据ORDER BY取第一行的数据。
AggregatingMergeTree
AggregatingMergeTree可以看做SummingMergeTree的升级版,很多设计思路是一致的,例如同时定义ORDER BY和PRIMARY KEY的原因和目的。AggregatingMergeTree有会根据ORDER BY声明的字段聚合,具体聚合的方式由建表时的聚合语句决定,如下。
CREATE TABLE agg_table(
id String,
city String,
code AggregateFunction(uniq,String),
value AggregateFunction(sum,UInt32),
create_time DateTime
)ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id,city)
PRIMARY KEY id
除了建表语句之外,在后续的读写方式都有改变,例如写入时,需要调用与聚合方法对应的State函数,uniq->uniqState;查询时,需要调用与聚合方法对应的Merge函数,uniq-> uniqMerge
INSERT INTO TABLE agg_table
SELECT 'A000','wuhan',
uniqState('code1'),
sumState(toUInt32(100)),
'2019-08-10 17:00:00'
SELECT id,city,uniqMerge(code),sumMerge(value) FROM agg_table
GROUP BY id,city
但上述方法并不是该引擎最常见的使用方式,该引擎最常见的方式和结合物化视图使用,作为物化视图的表引擎。如下,新增数据针对底表,查询数据使用物化视图
CREATE TABLE agg_table_basic(
id String,
city String,
code String,
value UInt32
)ENGINE = MergeTree()
PARTITION BY city
ORDER BY (id,city)
CREATE MATERIALIZED VIEW agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY city
ORDER BY (id,city)
AS SELECT
id,
city,
uniqState(code) AS code,
sumState(value) AS value
FROM agg_table_basic
GROUP BY id, city
CollapsingMergeTree
CollapsingMergeTree通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态,如果sign为1,则是一条有效数据,如果sign为-1,则该数据需要删除。分区合并时,同一数据分区内,sign为1和-1的会被抵消删除。
ReplicatedMergeTree
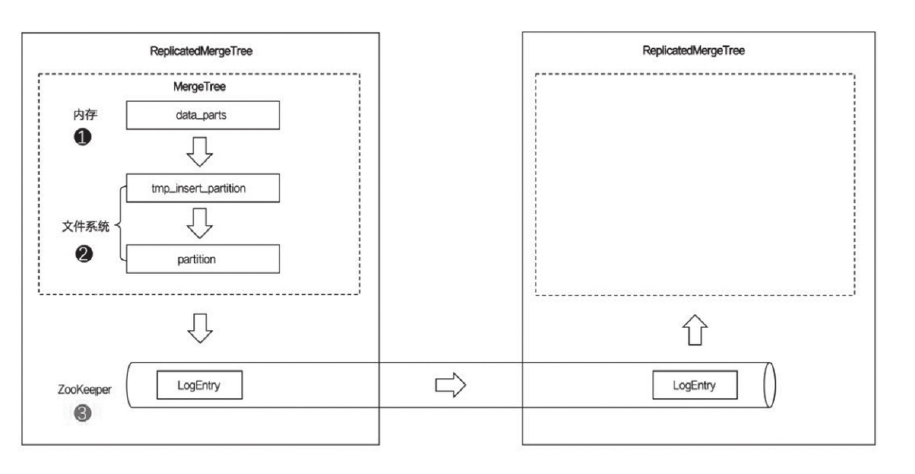
ReplicatedMergeTree借助ZooKeeper的消息日志广播功能,实现副本实例之间的数据同步功能。
数据查询
在绝大部分场景都该避免使用SELECT * 形式查数据,因为通配符对于采用列式存储的数据库而言没有任何好处。
在使用JOIN查询时,首先应该遵循左大右小的原则,即把数据量小的表放在右侧,因为执行JOIN查询时,右表都会被全部加载到内存中与左表比较。JOIN查询目前没有缓存支持,大量维度属性补全的查询场景中,建议使用字典代替JOIN查询。
副本与分片
副本
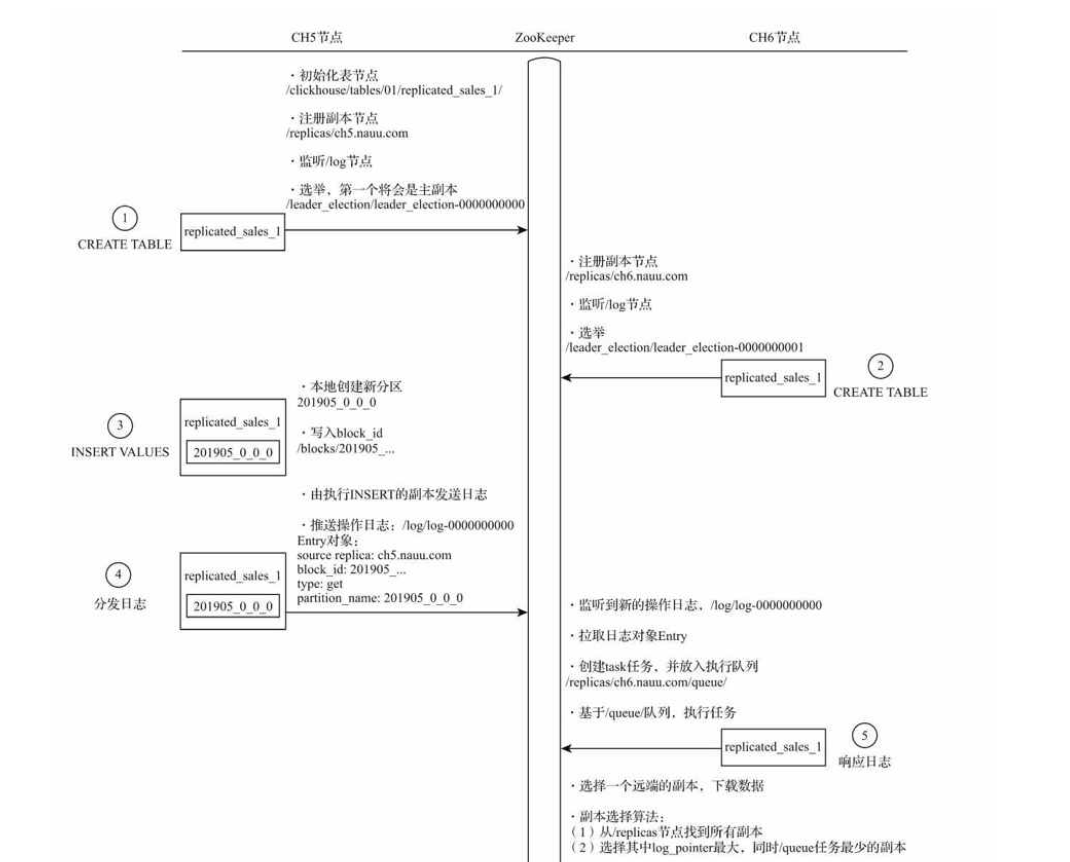
ReplicatedMergeTree的设计特点:
- 依赖ZooKeeper,执行INSERT和ALTER查询的时候,需要借助zk的分布式协同能力,实现多个副本之间的同步。
- 表级别的副本
- 多主架构,任意一个副本上执行INSERT ALTER效果相同。
- Block数据块 在INSERT写入数据时,会根据
max_insert_block_size将数据切分成若干Block数据块。Block数据块是数据写入的基本单元。具有写入的原子性和唯一性。
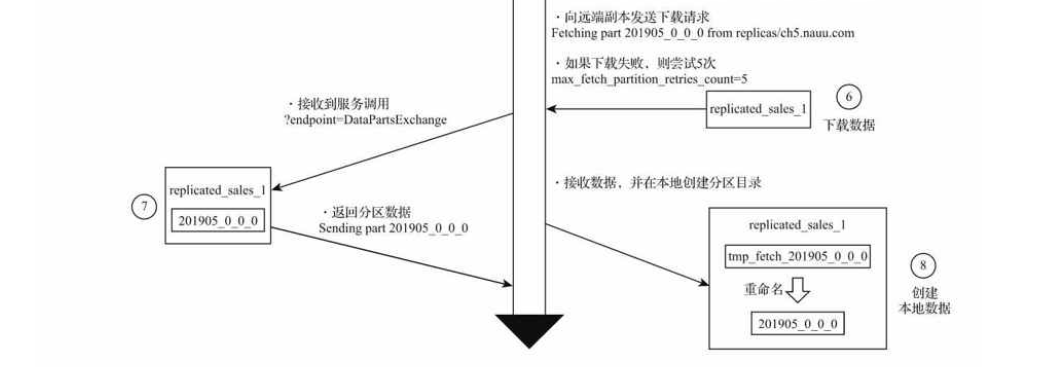
分片
副本虽然能降低数据丢失风险,提升查询性能(读写分离),但数据表容量的问题让然没有解决,单表的性能瓶颈只能靠分片来突破。ClickHouse的数据分片需要结合Distributed表引擎一同使用。Distributed表引擎自身不存储任何数据,作为分布式表的一层透明代理,在集群内部自动开展数据的写入,分发,查询,路由等工作。
- 本地表,通常以_local为后缀进行命名。本地表是承接数据的载体,可以使用非Distributed的任意表引擎。一张本地表对应了一个数据分片。
- 分布式表,通常以_all为后缀进行命名。分布式表只能使用Distributed引擎,它与本地表形成一对多的映射关系,日后将通过分布式表代理操作多张本地表。
ENGINE = Distributed(cluster, database, table, [,sharding_key])
其中,sharding_key是分片键,选填参数。在数据写入的过程中,分布式表会依据分片键的规则,将数据分布到各个host节点的本地表。
创建分布式表
CREATE TABLE test_shard_2_all ON CLUSTER sharding_simple (
id UInt64
)ENGINE = Distributed(sharding_simple, default, test_shard_2_local,rand())
然后再创建本地表
CREATE TABLE test_shard_2_local ON CLUSTER sharding_simple (
id UInt64
)ENGINE = MergeTree()
ORDER BY id
PARTITION BY id
Distributed表的操作分为如下几类:
- 会作用于本地表的查询,对于INSERT和SELECT,Distributed将会以分布式的方式作用于local本地表。
- 只会影响Distributed自身,不会作用于本地表的查询,例如CREATE,DROP,ALTER等,例如要彻底删除一张分布式表,需要分别删除分布式表和本地表。
- 不支持的查询;Distributed表不支持任何MUTATION类型的操作,包括ALTER DELETE和ALTER UPDATE
分片键
分片键要求返回一个整型取值,例如分片键可以是一个具体的整型字段,也可以是返回整型的表达式如rand()
分布式写入的核心流程
向集群分片写入数据时,通常有两种思路,一种是借助外部计算系统,事先将数据均匀分布,再由计算系统直接写入各个本地表。第二种思路是通过Distributed表引擎代理写入分片数据
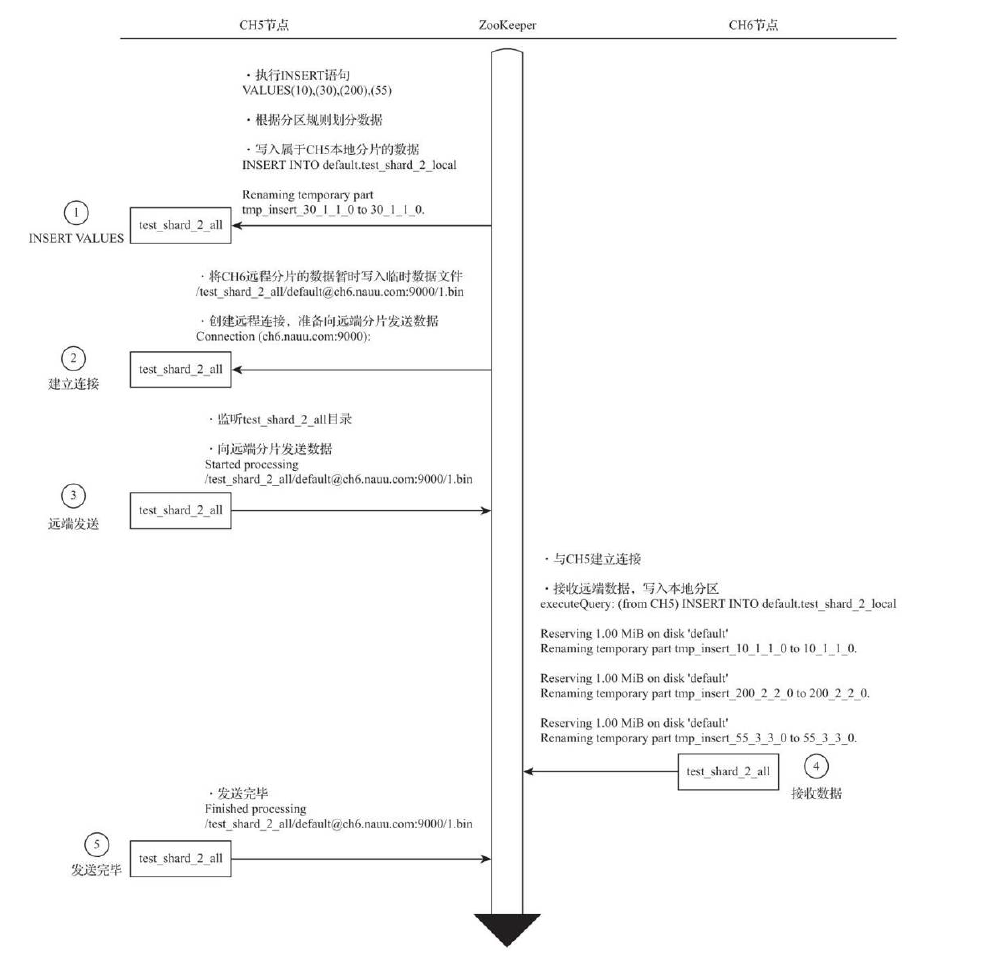
副本复制数据的流程
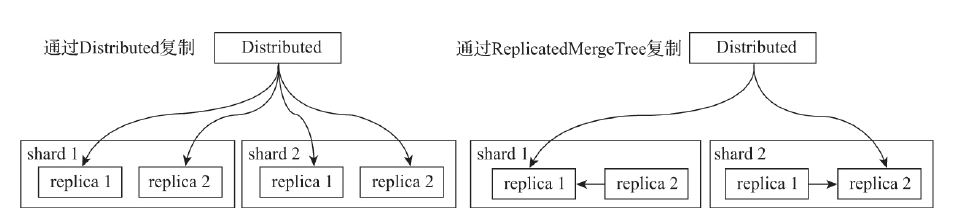
数据在多个副本之间,有两种复制实现方式:一种是借助Distributed表引擎,由它将数据写入副本;另一种是借助ReplicatedMergeTree表引擎实现副本数据的分发。
多分片查询的核心流程
Distributed表会拆分成若干个针对本地表的子查询,然后向各个分片发起查询,最终通过UNION汇总结果。
Global优化分布式子查询
如果分布式查询中使用子查询如IN,IN查询的子句是本地表,所以要改成GLOBAL IN。



