MySQL 学习笔记 - 存储 & 索引
存储
数据页
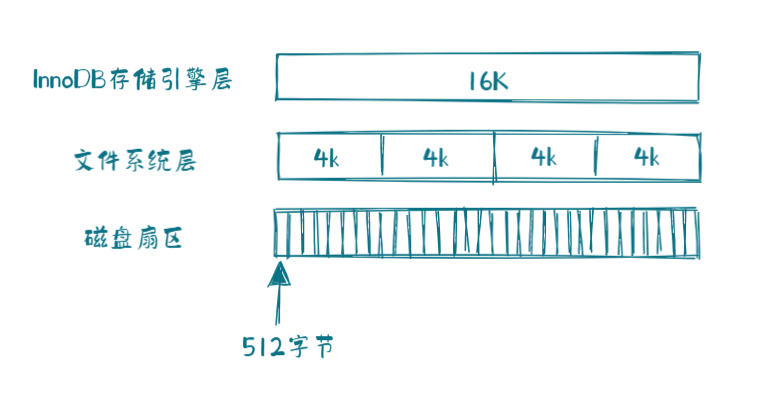
计算机中的磁盘存储数据的最小单元是扇区,一个扇区512字节。文件系统最小单元是块,一个块4K。InnoDB最小单元是页(也就是我们说的数据页),一个页是16K。如下图:
缓存池 buffer pool
InnoDB用缓存池来管理内存。缓存池中的内存页有三个状态:空的(还可以写入),脏页(内存与磁盘数据不一致,磁盘没来得及更新),干净页(内存与磁盘数据一致)。(也可以说,内存中的数据页一定是最新的)
缓存池有两个作用,一个是在WAL(Write-ahead Logging)中起到加速更新的作用,也就是先写日志,再改缓存,等有空的时候再刷到磁盘上。另外一个就是加速查询,当事务提交,但是磁盘上还未更新时,如果有新的查询来读这个数据页,可以直接查内存返回就行了。
注意
这里的缓存池和架构中描述select语句需要先查询缓存是两个概念。查询缓存,其实是把查询语句作为key,查询结果作为value,存起来,需要查询语句完全匹配,才能直接返回查询结果。MySQL 8.0版本直接将查询缓存的功能删掉了。
内存管理
有缓存就一定离不开命中率和淘汰策略。show engine innodb status可以显示内存命中率,而InnoDB管理内存使用的就是LRU算法。
LRU (Least Recently Used)
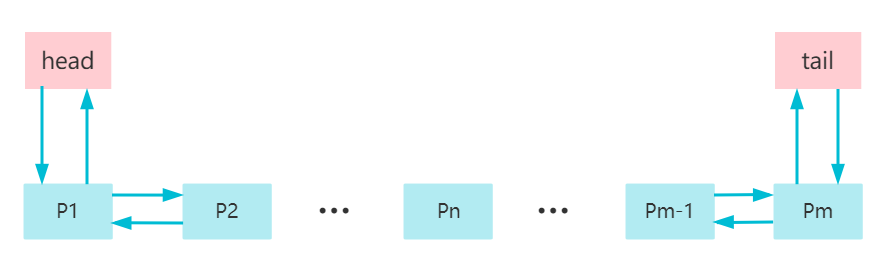
第一次接触LRU是做的一道leetcode算法题,让你去实现一个LRU的结构。其实就是一个HashMap+双向链表(或者可以直接用LinkedHashMap)。LRU的核心思想就是,每次访问到一个数据,就把它移动到链表的头部,而当容量超过设定值时,就淘汰掉链表尾部的数据,因为它被认为是最近最少访问到的(相对于链表里其他数据),以后被访问到的概率也相对较小,如下图:
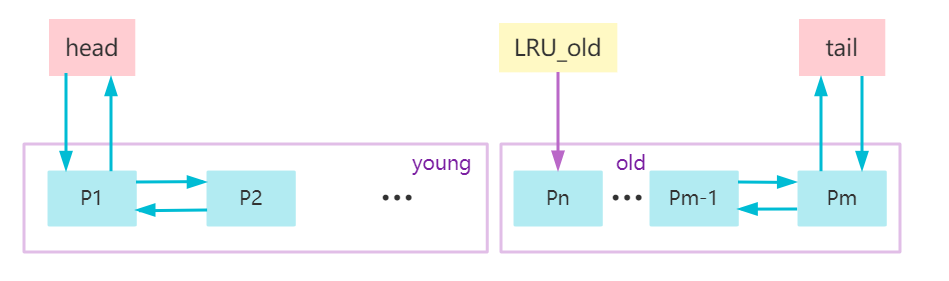
回到InnoDB的内存管理来,如果直接采用LRU在数据库这里会出现一些问题。例如一个场景是需要全表扫描一个数据量很大的历史数据表,那么这个时候,会让buffer pool里原来的热点数据全部被淘汰掉,内存命中率急剧下降,磁盘压力增加,SQL语句响应变慢。所以InnoDB在这个LRU的基础上,做了改进。对链表进行了分区,分为young和old区,占比大约是5:3。分区之后buffer pool更新淘汰的策略为:
- 如果访问一条不存在buffer pool中的数据,则将该数据插入old区的头部
- 如果访问一条存在于buffer pool 且存在于young区的数据,则移动该数据到链表头部;如果该数据存在于old区,则根据这个数据页在链表中存在的时间是否大于一个参数(
innodb_old_blocks_time,该值默认为1s),如果大于则移动到链表头部,如果小于,则不变其位置,如下图:
优化之后,如果出现上述场景,那么这些历史数据始终会存在于old区,并且很快会被其他数据淘汰掉,热点数据不会一下子被挤出去。
在上面这个例子中,一次查一个这么大的表,会不会把MySQL内存打爆呢?答案是不会,因为MySQl是“边读边发”的。
索引
在MySQL的架构中有提到,索引是依赖存储引擎的,这里主要讲的都是InnoDB的索引~
索引相当重要,目录之于字典。没有索引,如此大量的数据(汉字),想查一个字,难道要挨着一页一页翻?
问题1 InnoDB索引数据结构是什么,为什么选这个?
InnoDB索引是用B+树实现的。为什么用B+树这个问题,其实可以变成:“为什么不用hash”,“为什么不用二叉树”,“为什么不用B树”... (毕竟只有有的选才有为什么这样选的原因)
首先,为什么不用HashMap这种结构?HashMap在散列得很好的情况下对数据访问的时间复杂度是O(1),听上去很好,但是它不适合区间查询,排序等。试想一个select name from user_info where age <= 20 and age >=14,那就用不上hash了,只能一个一个查。
B树 & B+树
B树(又叫B-树)和B+树与二叉树的一个很大的不同就是,它们都是多叉树。B树和B+树最大的区别,在于:1. B树的非叶子节点是存数据的,但是B+树只有叶子节点存数据。 2. B+树的叶子节点存有相邻叶子的双向指针,如下图:
B树:
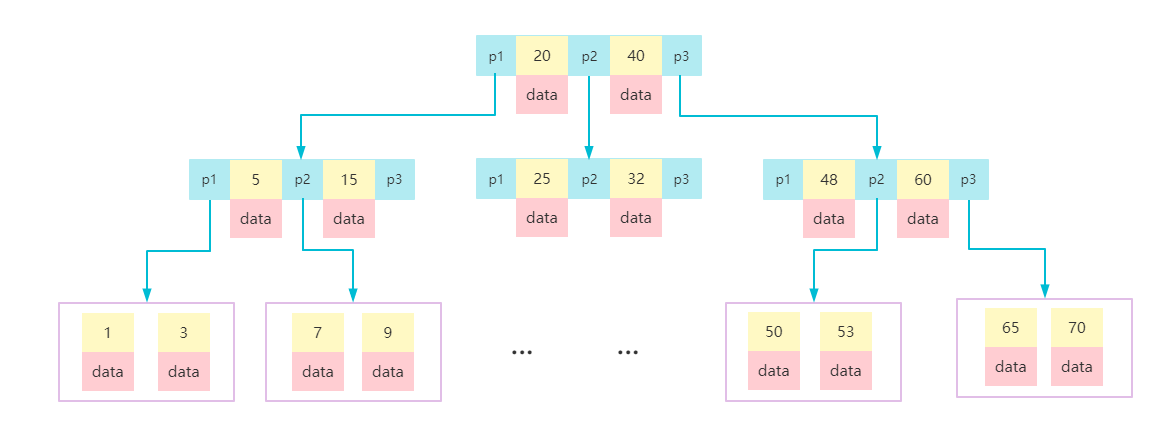
B+树
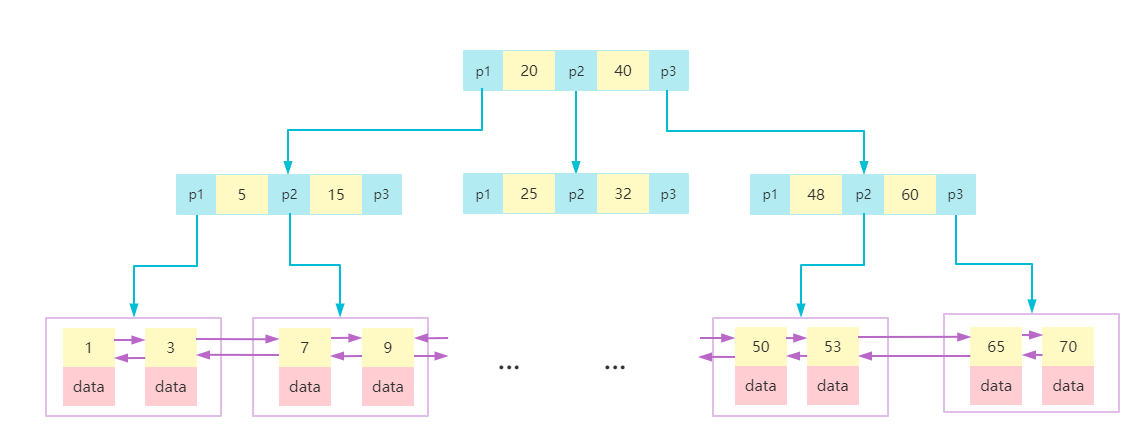
为什么不用二叉树或者B树。二叉树树高很高时(数据量很大时),对应的磁盘IO次数就会很多(索引也是文件放在磁盘的,如果没能一次性加载到内存,就得在需要访问哪个索引节点的时候,加载那个磁盘块进来),查询性能就会很差。B树虽然可以保证树高2-3层满足大部分场景,但是范围查询效果不好,容易从根节点多次遍历;其次,B树非叶子节点存储数据会导致节点占用空间变大,一个页中可存储的数据量变小,树高增高,磁盘IO增多。
所以B+树对于范围查询(叶子节点有双向列表,可以直接向后访问到),控制树高(减少IO)都效果相对比较好。
问题2 为什么总是倾向选择自增主键?
第一个问题是主键索引和非主键索引的区别。主键索引又叫做聚簇索引。InnoDB的索引用的B+树,只有叶子节点才存数据。对于主键索引来说,叶子节点存的就是row,也就是完整的一行数据记录;而非主键索引叶子节点存的仅仅是主键索引的值。
为什么用自增id作为主键的原因可以从逻辑,时间,空间上三个方面来说。
- 从逻辑上来说,对于一个需要作为唯一标识的字段,它最好是无意义的。因为一旦它有意义了,发生重复,冲突的可能性会大大增大。
- 从时间/性能上说,自增id作为主键,会保证索引的递增,不会出现由于索引的无序插入导致叶子节点分裂合并等情况,而这些情况就会损耗性能。
- 从空间上来说, 自增id如果用bigint为8个字节,如果用身份证号,需要20个字节,主键索引占用的空间越多,那么其他所有二级索引树占用的空间就会更大(叶子节点存的主键索引的值)
回表
根据以上表述,可以知道,当我们查询一个非主键索引的时候,需要先从非主键索引的B+树上找到对应的主键索引值,再从主键索引的B+树上找到具体需要的数据,这个过程就叫做回表。
回表一听就不是什么好事。那如何减少回表呢?要么你查的时候就直接用主键索引查;要么,就使用覆盖索引,也就是说创建的这个索引上的信息就完全能满足查询,也就不需要在多此一举回表了。像上一个例子,select name from user_info where age <= 20 and age >=14,如果有一个<age,name>的索引,就不用再回表。
问题3 如何设计索引?
第一个事情,如何判断一个索引“好不好”。有一个概念叫做区分度,即一个索引字段的取值不同值越多,它的区分度就越高,相对来说就是个“好”的索引,像性别这种,要么男,要么女的就属实不是个区分度高的属性。除此之外,索引一定是为查询服务的,它的开销除了存储成本,还有就是我们插入数据,更新数据时的开销。规范来说,需要查询的字段都应该建立索引。当然也要利用好最左前缀原则,例如已经有了一个<a,b>的索引,我查where a like '学%'也是能用上索引的。
最左前缀原则
联合索引的前N个字段或者字符串索引的最左M个字符。
每个公司甚至每个组,可能都有一套索引规范,一定要仔细学习,认真思考。比如,一般来说有的DBA规定,只要是业务上具有唯一特性的字段,即使是多个字段的组合也需要建立唯一索引;varchar字段上建索引时,必须制定索引长度等等。
其他问题
- 为什么优化器会选错索引?



