随笔分类 - 存储组件
摘要:分布式锁实现方式 分布式锁实现方式: 基于数据库 原子操作 如shedlock组件 基于redis 单点的setnx k v nx px , v需要为随机数,删除时使用lua脚本保证原子性,if v==线程设置的值 才 del 防止其他线程错误释放锁 redis redlock 多节点依次加锁,大多
阅读全文
摘要:三种策略 Cache Aside 只读缓存模式,即读操作命中缓存直接返回,未命中从后端数据库加载到缓存再返回。写操作直接更新数据库,并删除缓存。 👍一切以后端数据库为准,最常用的方式。 Read/Write Through 应用层读写只操作缓存,不关心数据库。操作缓存时,缓存层会自动从数据库加载或
阅读全文
摘要:策略分类 内存写满了怎么办?Redis提供了以下几种内存淘汰的策略: No eviction 不淘汰数据 即,内存写满后,再有写请求时,Redis直接返回错误,不会提供服务。这也是Redis3.0之后的默认淘汰策略。 淘汰数据 设置过期时间的数据中淘汰 💜 volatile-ttl :根据过期时间
阅读全文
摘要:# 小结 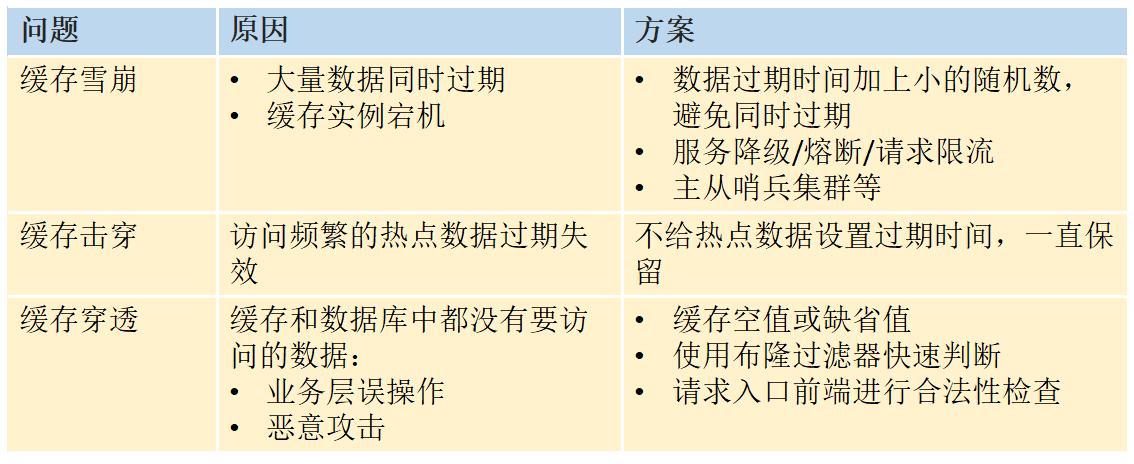 # 布隆过滤器 工作原理: 布隆过滤器是一个由初值为0的长度为L的bit数组和N个哈希函数组成
阅读全文
摘要:扩容的思路 纵向扩展 scale up: 一台8G的变成一台24G的 :+1: 简单 :-1: 受硬件条件的限制 :-1: 单机容量大对性能的影响,如Redis的fork操作耗时是和内存数据量正相关的 横向扩展 scale out: 一台8G的变成3台8G的 :+1: 扩容灵活,不会增大单机的存储
阅读全文
摘要:> 数据库的发展总是从 单机 -> 主从 -> 分片集群 # Redis的主从复制 从单机到主从的根本优势在于: - 可实现读写分离,分摊读压力;某个从库用于做统计等后台功能 - 数据可靠,一份数据,多处拷贝,一台机器坏掉了,也不至于数据没了 - 服务可靠,主节点挂了不能写,可以从从节点选一个上来
阅读全文
摘要:# 持久化方式 因为Redis是内存操作,意味着掉电就GG, 所以为了保证异常重启等问题后能尽快恢复服务,还是需要一定的持久化机制来保证。Redis提供了两种持久化机制: - AOF Append Only File - RDS Redis Database ## AOF AOF文件记录的命令本身,
阅读全文
摘要:即便是单线程,Redis还是那么快? 一说到Redis的IO模型,就会说到Redis是“单线程”处理的。这里的单线程,主要是指网络IO和键值读写,也就是处理我们业务的基本请求是单线程的,但是Redis也存在一些如持久化,主从复制等是有多线程完成的。 网络IO Redis的网络IO采用的是多路复用机制
阅读全文
摘要:Redis key-value结构组织 首先,Redis使用了一个全局哈希表来保存所有的键值对。这个全局哈希表,也就是一个存放哈希桶(entry)的数组。Redis可以用哈希算法算出某个key的哈希值,直接取到这个数组这个位置的元素,也就是O(1)的读写。每个entry包含了两到三个部分,一个是*k
阅读全文
摘要:数据库请求流程 应用端 应用端视角里(MongoDB驱动程序与MongoDB进行交互),一次数据库请求流程如下: 选择节点 在复制集读操作里,选择节点会受readPreference参数影响 排队等待 总连接数大于最大连接数maxPoolSize,连接满了如何解决:优化查询性能,提高服务端资源等 连
阅读全文
摘要:索引数据结构 MongoDB的索引和MySQL一样用的是B+树。由于在MySQL索引部分对B+树已经做了介绍,这里就不再描述啦,详见 MySQL - 存储&索引 虽然但是,很多地方都说MongoDB索引的数据结构是B-树,在我看了蛮多博客以及一些同学询问官方得到的回复,以及极客时间上MongoDB课
阅读全文
摘要:MongoDB的部署架构 mongodb常见部署方式如下: 各个节点含义 mongos : 路由节点,为业务程序提供集群单一入口,转发应用端请求。选择合适的数据节点进行读写,合并多个分片数据节点的返回。无状态,至少2个。 config: 配置节点,提供集群元数据的存储(数据节点有哪些),分片数据分布
阅读全文
摘要:写操作事务 writeConcern - w writeConcern决定写操作落到多少节点上才算成功,其取值包括: 0:发起写操作,不关心结果 n 1 ⇐ n ⇐ 集群最大数据节点数:写操作复制到n个节点才算成功。 majority: 写操作被复制到大多数节点才算成功 发起写操作的线程将阻塞到写操
阅读全文
摘要:CURD insert db.collection.insertOne() db.collection.insertMany() db.fruits.insertOne({name:"apple"}) db.fruits.insertMany([ {name:"apple"}, {name:"pea
阅读全文
摘要:原则 分库分表有一个前提:能不拆就不拆,能少拆就少拆,避免过度设计和过早优化,优先考虑升级硬件,索引优化,读写分离等等。因为拆分会带来开发和后期维护的成本。那为什么仍然需要分库分表呢?第一,某些系统还是需要依赖MySQL来保证金融级的事务。第二,MySQL本质是单机数据库,支持不了太大的数据量和高并
阅读全文
摘要:架构 复制集(replica set)提供了数据冗余和高可用。它是一组mongod进程。 一个复制集里面有很多数据节点(data bearing node)和一个可选择的仲裁节点(arbiter node)。数据节点的角色也分为主节点(primary node)从节点(secondary node)
阅读全文
摘要:Data Model概念 如果要给MongoDB打标签,那么首选的几个标签无非是NoSQL, 非关系型数据库, 分布式文档存储数据库。而关系型数据库,非关系型数据库一个非常重要的区别就是Data Model。Data Model 决定了“要怎么存”,“适用怎么查”等,也是选型的一个重要考虑因素。 所
阅读全文
摘要:MongoDB知识图谱 在网上看了半天,感觉可能学习MongoDB的官方文档会比较好一点。 MongoDB简介 MongoDB是一个文档型数据库(document database)。它存储数据的数据结构(文档)是一个Key-Value Pair的集合,其中Value也可以是一个数组,一个其他的文档
阅读全文

