
算法设计与分析报告4 实验四 动态规划
本文发布地址:
- https://cmd.dayi.ink/WNa3RGNaShmf_vPpUemWxA?both
- https://type.dayiyi.top/index.php/archives/237/
- https://blog.dayi.ink/?p=82
- https://www.cnblogs.com/rabbit-dayi/p/17816598.html
1.爬楼梯问题
- 小明住在 N 层楼梯之上,然后他可以一次 一脚 1 个台阶,一脚 2 个台阶,问总共多少种方法。
- 一个楼梯共有 n 级台阶,每次可以走一级或者两级,问从第 0 级台阶走到第 n 级台阶一共有多少种方案。
-
状态表示:
f[i]表示0->i个台阶有多少种方案
有限集合的值
属性:数值 -
状态计算:
对于f[i]的计算:- 对于第
i层台阶- 我可以从
i-1上一层到i层 - 我可以从
i-2上两层到i层
- 我可以从
- 由于表示的是方案数:
f[i-1]表示从0->i-1层的方案数f[i-2]表示从0->i-2层的方案数
- 而
f[i]的方案数是:- 上一层的方案数(也就是从
f[i-1]过来) - 上两层的方案数(也就是从
f[i-2]过来)
- 上一层的方案数(也就是从
- 对于第
-
由状态可以推出状态转移方程
\(f[i] = f[i-1]+f[i-2]\)
可以写代码(对于 N 范围比较小)
def main():
N = eval(input())
dp = [0 for i in range(N+1)]
dp[0] = 0
dp[1] = 1
dp[2] = 2
for i in range(3,N+1):
dp[i]=dp[i-1]+dp[i-2]
print(dp[N])
return
if __name__ =="__main__":
main()
\(N = 1000\)
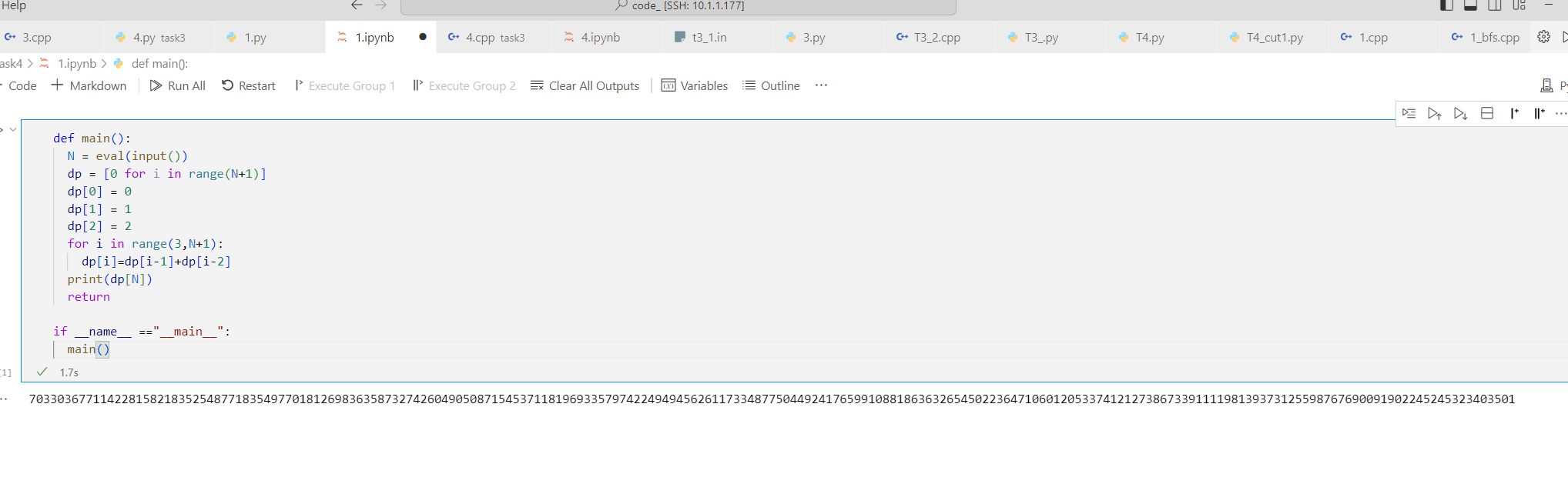
这个题还可以用矩阵快速幂来优化,数组也不需要开这么多。
斐波那契数列的递推关系可以用矩阵形式表示,并且通过矩阵乘法可以得到一个和斐波那契数列递推公式相同的关系。使用矩阵快速幂可以将时间复杂度从线性降低到对数级别。这样,我们就可以在非常快的时间内计算出f[N]的值,即到达第N层楼梯的方法数。
时间复杂度
- 矩阵快速幂的时间复杂度为\(O( \log N)\)
- 普通递推为\(O(N)\)
2.整数拆分问题
爆搜:同实验1
计数DP
设置状态 f[i][j]
表示:
2.整数拆分问题
对于整数拆分问题,我们需要计算将一个正整数 n 拆分成若干个正整数之和的方法数。我们可以使用动态规划来解决这个问题。
-
状态表示:
f[i][j]表示将整数i拆分为最大加数不超过j的所有不同拆分方式的数量。 -
状态计算:
要计算f[i][j],我们可以考虑两种情况:- 不使用数字
j,即所有拆分方式中的最大加数小于j,这意味着我们只看f[i][j-1]的拆分方式。 - 至少使用一个数字
j,这时我们需要从i中减去j,并且新的拆分问题变成了拆分i-j为最大加数不超过j的方式,即f[i-j][j]。
因此,状态转移方程可以表示为:
\[f[i][j] = f[i][j-1] + f[i-j][j] \]其中
f[0][j]应初始化为 1,因为对于任何j,有且只有一种方式来拆分0(即不使用任何数)。 - 不使用数字
-
边界情况:
f[i][0]应该为 0,因为没有办法只用0来拆分任何正整数i。
其实,这就是背包问题对bia
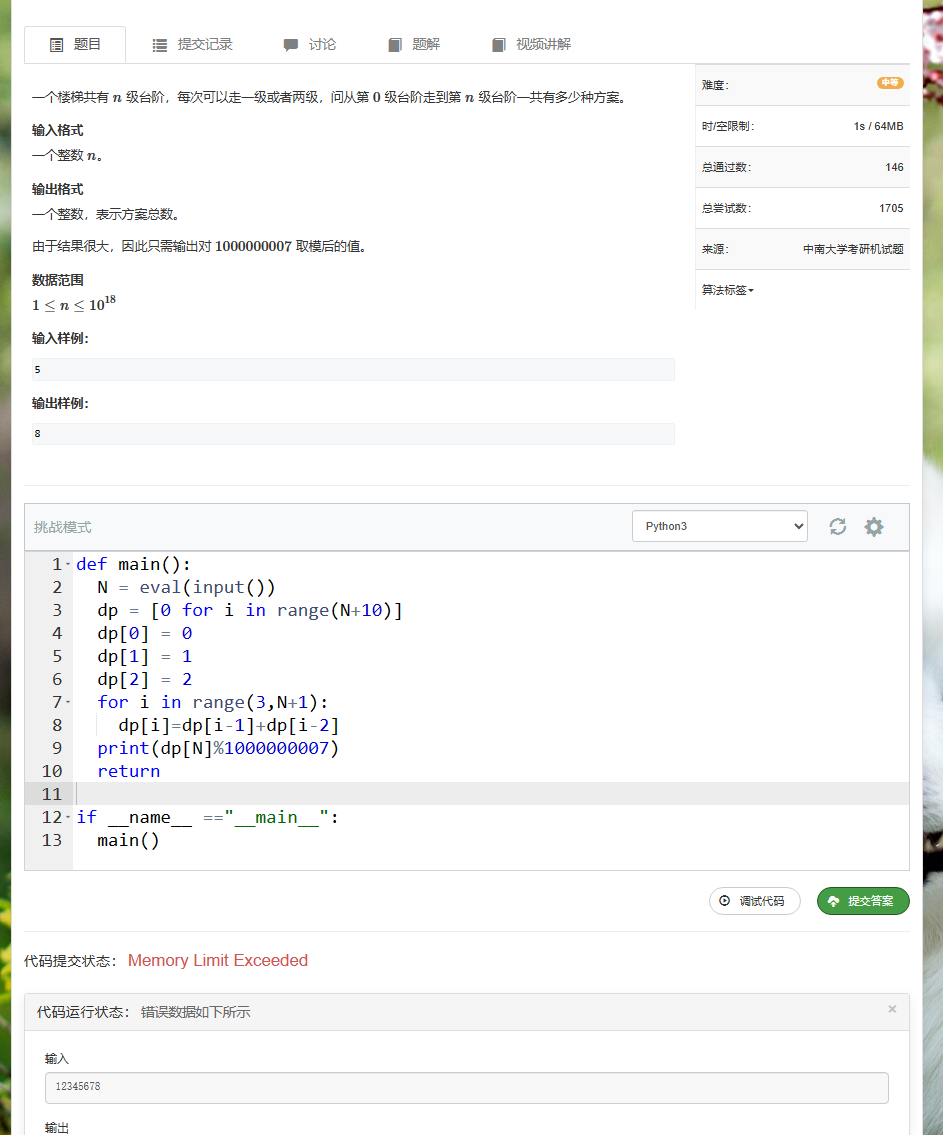
def dp(n):
dp = [[0 for _ in range(n+1)] for _ in range(n+1)]
for i in range(n+1):
dp[i][0] = 0
for j in range(n+1):
dp[0][j] = 1
for i in range(1, n+1):
for j in range(1, n+1):
dp[i][j] = dp[i][j-1]
if j <= i:
dp[i][j] += dp[i-j][j]
return dp[n][n]
n = 5
print(dp(n))
如果对空间进行压缩:
dp[i]来保存中间结果,dp[j]在迭代开始前代表的是dp[i-1][j]的值,在迭代结束后代表的是dp[i][j]的值。- j从大到小进行枚举,
dp[j],这样就能确保计算dp[j]时dp[j-1]还没被更新,其代表的仍是dp[i][j-1],而dp[j]表示的是上一轮的dp[i-1][j],即dp[i-j][j]
转移方程:
在压缩为一维数组之后,状态转移方程的形式并不变,但是实现方式发生了变化。
更新dp[j] 时,等号右边的 dp[j] 表示更新前的 dp[i-1][j],也就是未加入j 之前的整数 i 的拆分数;
dp[j-1] 则表示 dp[i][j-1],即加入 j 后整数 i 的拆分数。
压缩后的一维转移方程实现过程如下:
- 不使用数字
j时,对应于f[i][j-1]的是当前dp[j-1]。 - 使用至少一个数字
j时,对应于f[i-j][j]的是更新前的dp[j]。
方程如下:
代码:
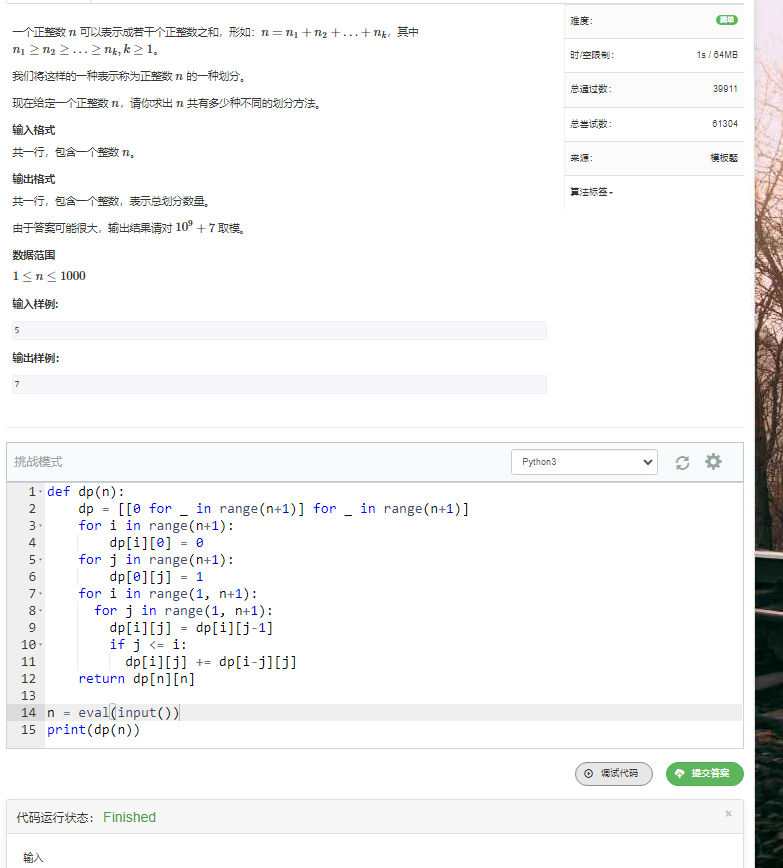
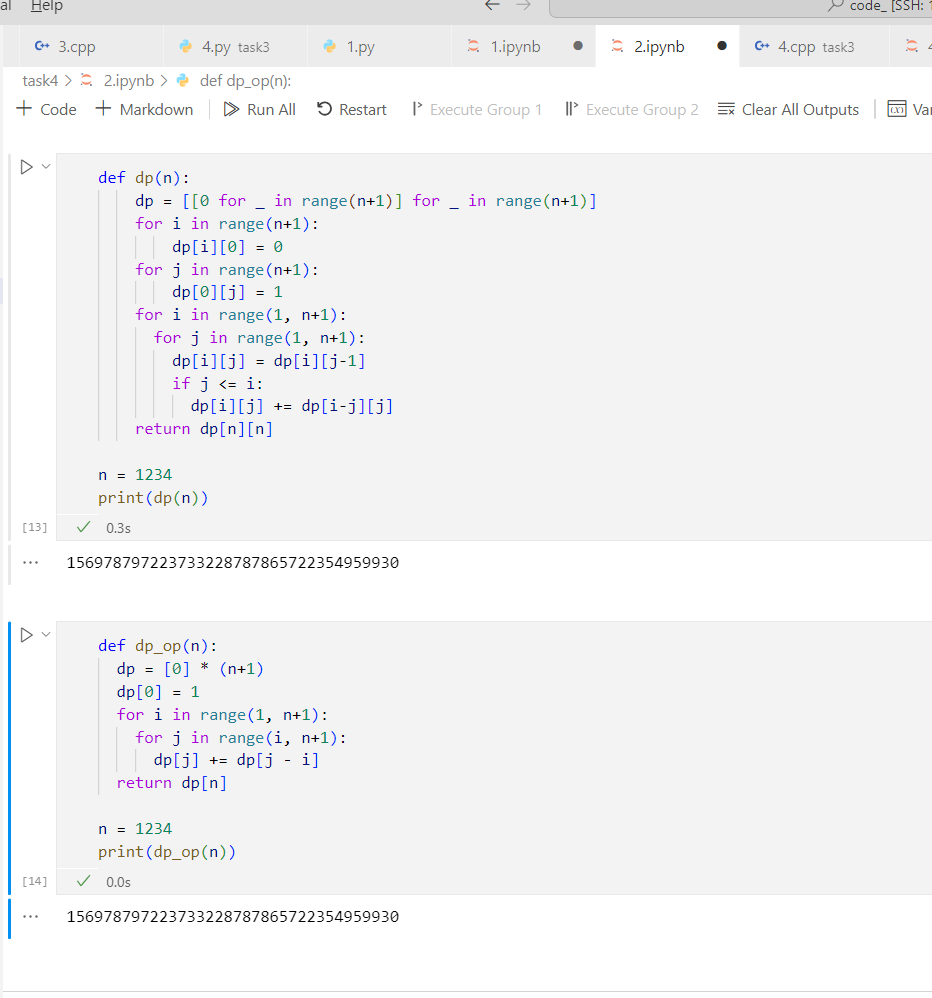
def dp_op(n):
dp = [0] * (n+1)
dp[0] = 1
for i in range(1, n+1):
for j in range(i, n+1):
dp[j] += dp[j - i]
return dp[n]
n = 1234
print(dp_op(n))
时间复杂度
- 外层循环从 i = 1 到 n,共执行 n 次。
- 内层循环从 j = i 到 n,平均情况下执行 n/2 次。
总的时间复杂度为 \(O(n * n/2)\),即 \(O(n^2)\)。
3. 0-1背包问题
0-1背包已经有了
完全背包
之前的实验里有啦,这里写下完全背包。
在 01 背包的基础上,小兔子有 \(n\) 种胡萝卜和一个容量为 \(V\) 的背包,每种胡萝卜都有无限件可用。第 \(i\) 种物品的体积是 \(c_i\),价值是 \(w_i\)。
问:应该如何选择装入背包的物品,使得背包中的总价值最大,同时不超过背包的容量。
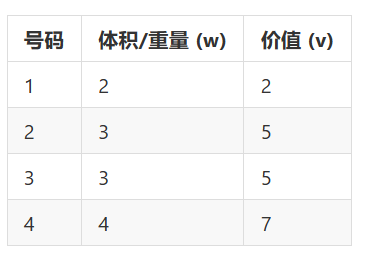
假设现在的胡萝卜有这几种:
| 号码 | 体积/重量 (w) | 价值 (v) |
|---|---|---|
| 1 | 2 | 2 |
| 2 | 3 | 5 |
| 3 | 3 | 5 |
| 4 | 4 | 7 |
集合表示
-
设
g[i][j]表示从前i种胡萝卜中进行选择,选择的胡萝卜的总体积不超过j的各种选法的集合(这里是集合,不是最大值也不是方案数)- 那么对于
g[2][5]来说,我可以选:- 1号胡萝卜0个 2号胡萝卜0个 价值 \(0\)
- 1号胡萝卜1个 2号胡萝卜0个 价值 \(2+0 =2\)
- 1号胡萝卜2个 2号胡萝北0个 价值 \(2*2+0 =2\)
- 1号胡萝卜1个 2号胡萝北1个 价值 \(2+5 =7\)
- 1号胡萝北0个 2号胡萝北1个 价值 \(0+5 =5\)
- 因此对于
g[2][5]来说就这些情况{0,2,2,7,5}
- 那么对于
-
不同的
g[i][j]表示不同的集合,比如g[2][5]来说,就是上述的集合 -
用
f[i][j]来表示g[i][j]这个集合中可以获得的最大值,比如 \(f[2][5]=\max\{g[i][j]\}=\max\{0,2,2,7,5\}=7\) -
对于每个
f[i][j],只需要保存g[i][j]的最大值,具体的集合元素不需要保存。对于末状态f[N][W]则为最后的状态,也就是 \(N\) 种胡萝卜,体积为 \(V\) 可以获得的最大值。
状态计算
-
如何把
f[i][j]计算出来? -
f[i][j]=max{g[i][j]} -
g[i][j]要怎么求? -
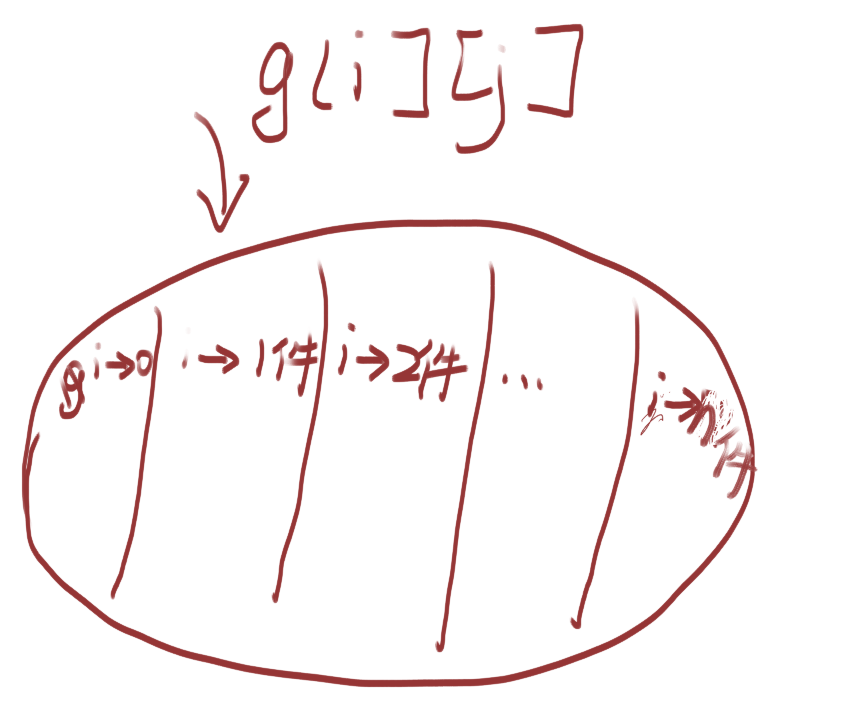
可以把
g[i][j]分为这几个部分:- i选 0 件
- i选 1 件
- i选 2 件
- ...
- i选 n 件
-
虽然胡萝卜的数量是无限的,但是我们的背包的容量大小是有限的。
-
第i种胡萝北进行分情况讨论:
-
第i种胡萝北:选0件, 不会消耗空间,可以放心的直接转移过来
f[i][j]= f[i-1][j] -
选1件:
g[i-1][j]会消耗w[i]*1的空间,得到v[i]的价值。g[i][j]=g[i-1][j-w[i]]中集合的全部元素再加上v[i]g[i-1][j-w[i]]中的全部元素的最大值为:$f[i-1][j-w[i]]- 于是,跟01背包一样,\(f[i][j]=f[i-1][j-v[i]]+w[i]\)
-
选2件:
g[i-1][j]下会消耗w[i]*2的空间,得到v[i]*2的价值g[i-1][j-2*w[i]]全部元素,再加上+2*w[i]
然后求这个集合的最大值,就是f[i][j]选两件的情况。- \(f[i][j]=f[i-1][j-2*v[i]]+w[i]\)
-
选 n 件:
- 虽然我们的胡萝北是无限的,但是我们的背包是有限的,我们背包不是四次元,重量不能是负的。
- 这样n实际上就会有上限
int(j/w[i])就是我们可以求得的上限值。
-
-
可以得到转移方程:
防止方程解析不出来:
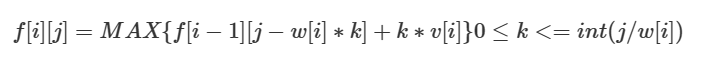
初始状态
f[i][0] = 0 : 什么都不选获得的价值 \(0\)
最终状态
f[N][W]
题目
https://www.acwing.com/problem/content/description/3/
代码
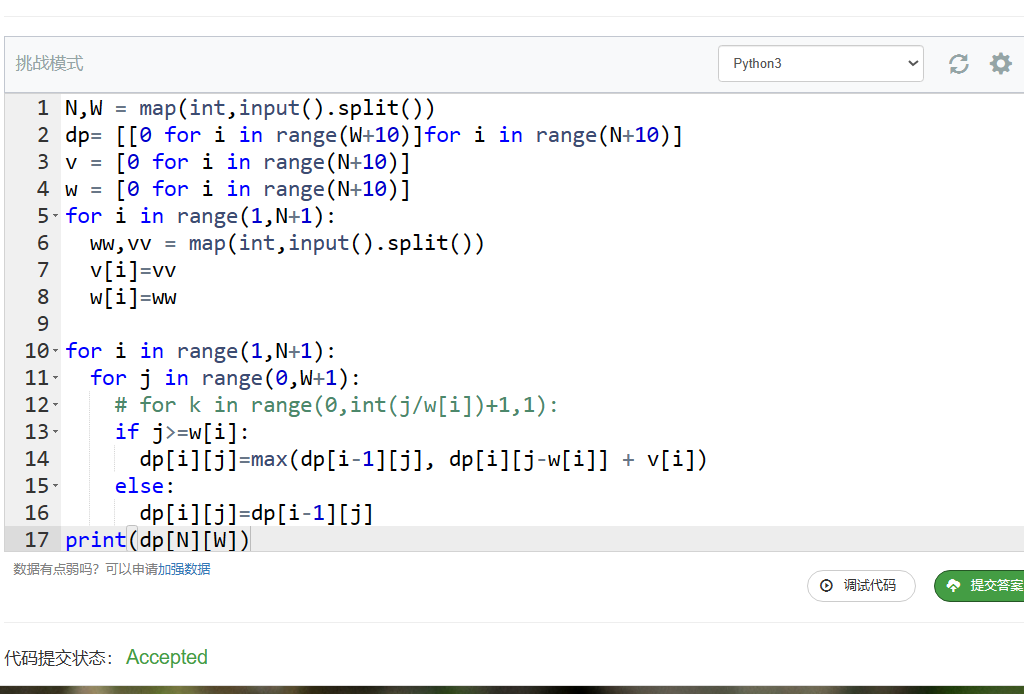
N,W = map(int,input().split())
dp= [[0 for i in range(W+10)]for i in range(N+10)]
v = [0 for i in range(N+10)]
w = [0 for i in range(N+10)]
for i in range(1,N+1):
ww,vv = map(int,input().split())
v[i]=vv
w[i]=ww
for i in range(1,N+1):
for j in range(0,W+1):
for k in range(0,int(j/w[i])+1,1):
dp[i][j] = max(dp[i-1][j-k*w[i]]+v[i]*k,dp[i][j])
print(dp[N][W])
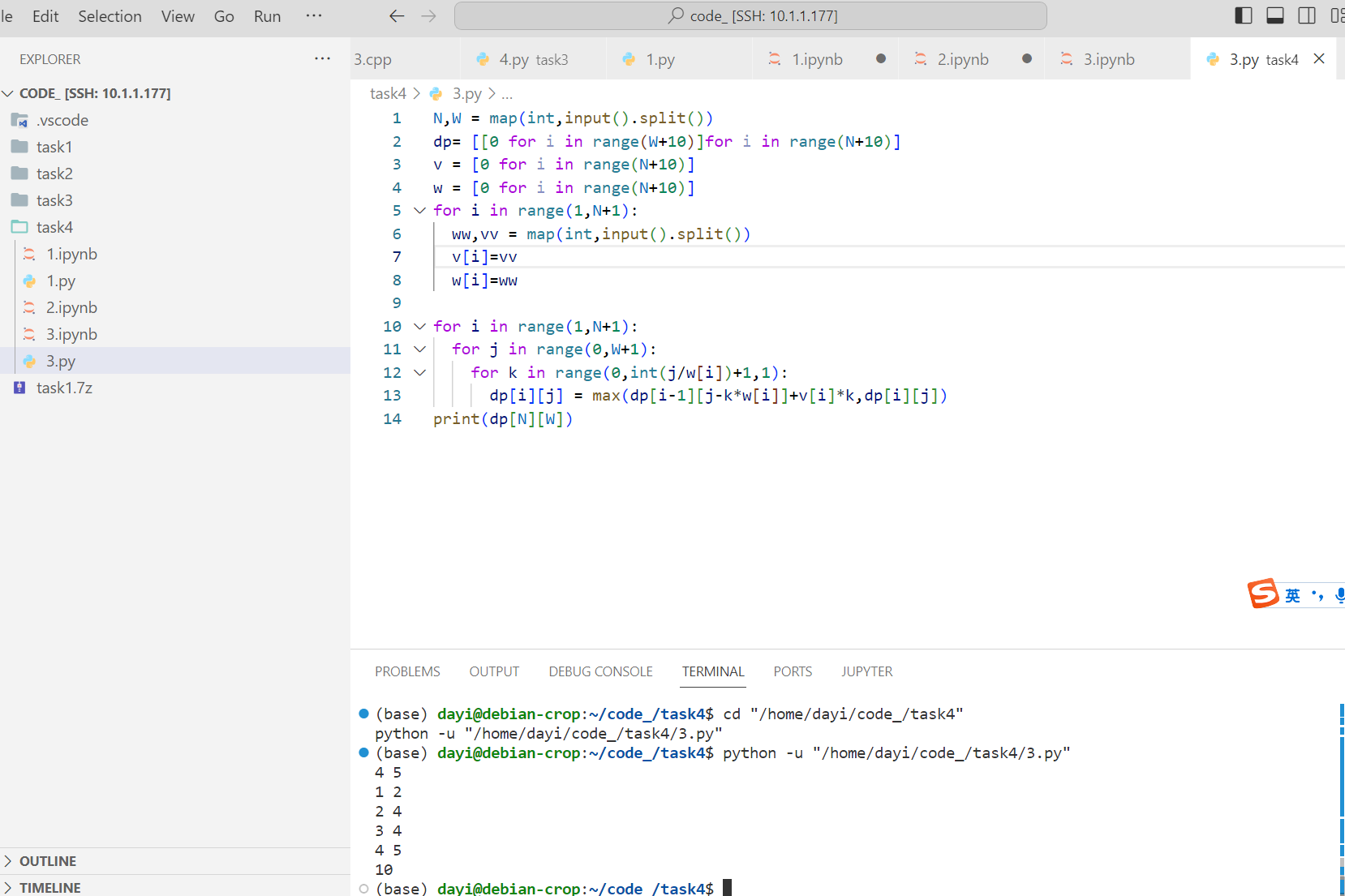
恭喜,在最大点上,TLE:
其实这个状态方程是可以优化的:
对于每个物品 \(i\),我们可以选择它 \(0\) 次、\(1\) 次、\(2\) 次,一直到 \(s_i\) 次(其中 \(s_i\) 是物品 \(i\) 的数量)。因此,对于 \(f[i][j]\),我们有以下的选择:
- 不选择当前物品 \(i\),那么 \(f[i][j] = f[i-1][j]\) 。
- 选择一次物品 \(i\),那么 \(f[i][j] = f[i-1][j - w_i] + v_i\) 。
- 选择两次物品 \(i\),那么 \(f[i][j] = f[i-1][j - 2 \cdot w_i] + 2 \cdot v_i\) 。
- 以此类推,直到物品的数量或背包容量的限制。
\(f[i][j]\) 的递推式为:
\(f[i][j-w_i]\)的递推式:
如果我们将 \(f[i][j - w_i]\)的每一项都加上 \(v_i\),我们得到:
比较 \(f[i][j]\) 和 \(f[i][j - w_i] + v_i\),我们可以看到 \(f[i][j]\)的每一项都在 \(f[i][j - w_i] + v_i\)中有对应的项,除了 \(f[i-1][j]\)。
可得:
\(f[i][j]\)的最优解要么包含了物品 \(i\),要么不包含(即它是 \(f[i-1][j]\)的最优解)。如果它包含了物品 \(i\),那么 \(f[i][j]\)的最优解可以通过在 \(f[i][j - w_i]\)的最优解的基础上加上物品 \(i\)的价值来得到。
写代码:
N,W = map(int,input().split())
dp= [[0 for i in range(W+10)]for i in range(N+10)]
v = [0 for i in range(N+10)]
w = [0 for i in range(N+10)]
for i in range(1,N+1):
ww,vv = map(int,input().split())
v[i]=vv
w[i]=ww
for i in range(1,N+1):
for j in range(0,W+1):
# for k in range(0,int(j/w[i])+1,1):
if j>=w[i]:
dp[i][j]=max(dp[i-1][j], dp[i][j-w[i]] + v[i])
else:
dp[i][j]=dp[i-1][j]
print(dp[N][W])
时间复杂度
三层循环的嵌套层数。假设有 \(N\) 种物品和背包容量为 \(V\),则算法的时间复杂度可以表示为 \(O(N * V^2)\)。
- 外层循环从
i = 1到N,共执行N次。 - 第二层循环从
j = 0到V,共执行V次。 - 第三层循环从
k = 0到int(j / w[i]),平均情况下执行int(j / w[i]) / 2次(因为 k 的最大值为int(j / w[i]),但平均情况下是一半左右)。
总的时间复杂度为 \(O(N * V * int(j / w[i]) / 2)\)。
递推公式优化后的时间复杂度:
\(O(NW)\)
4.最长公共子序列问题
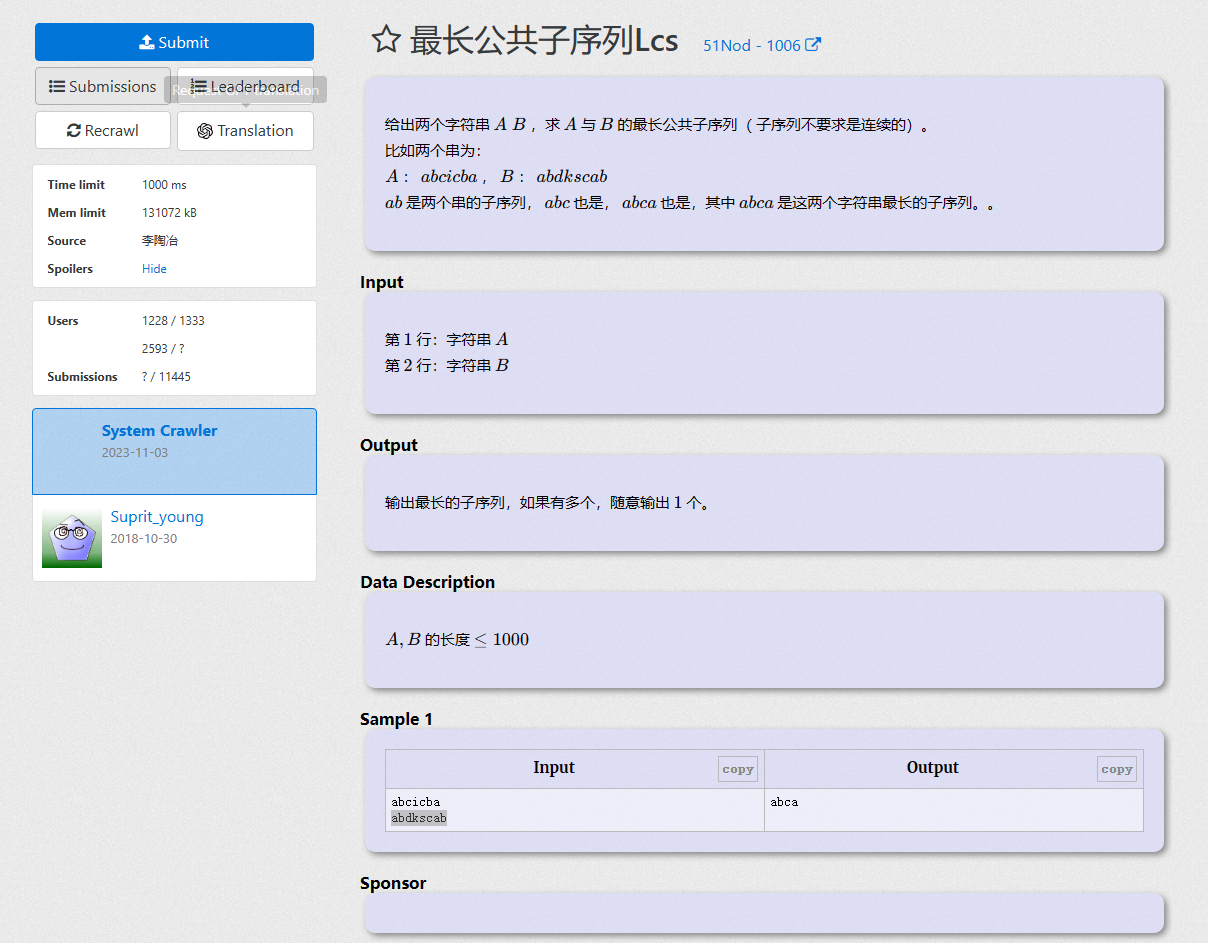
给定两个长度分别为 N 和 M 的字符串 A 和 B ,求既是 A 的子序列又是 B 的子序列的字符串长度最长是多少(寻找一个最长的序列,该序列同时是字符串 A 和 B 的子序列。)
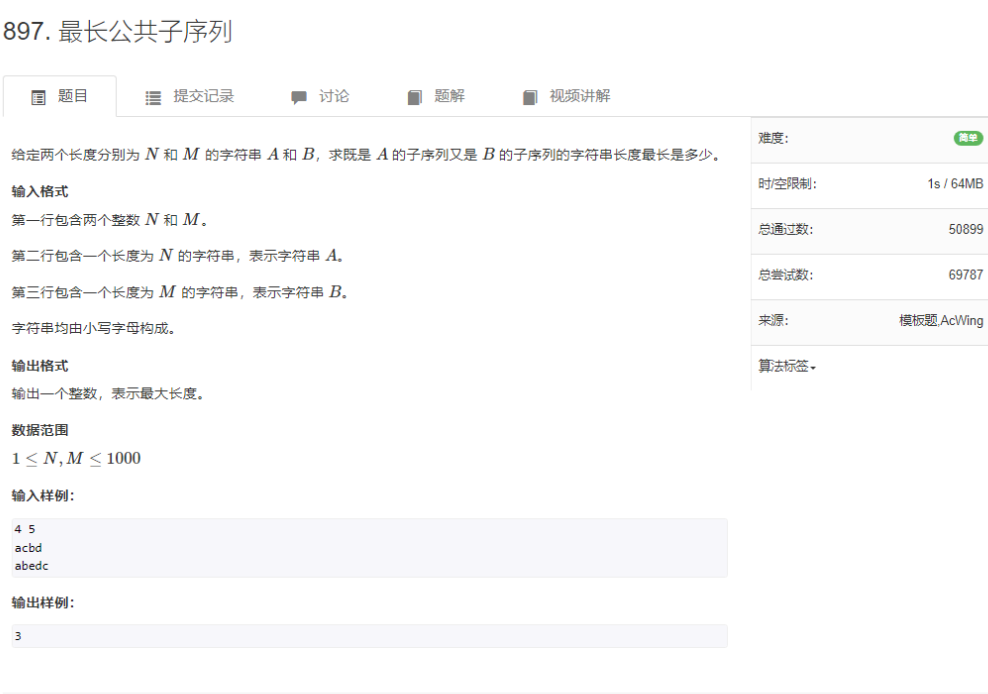
yi:
(1)子串:字符串中任意连续字符组成的序列。
(2)子序列:字符串中任意顺序保持一致的字符序列,可以非连续。
(3)公共子序列:两个序列中都出现的且顺序一致的子序列。
集合表示
- 设
dp[i][j]表示字符串A的前i个字符和字符串B的前j个字符的最长公共子序列的长度。- 例如,如果
A是 "ABCD" 且B是 "AEBD",dp[2][2]将代表 "AB" 和 "AE" 的最长公共子序列的长度。
- 例如,如果
集合的角度去描述 dp[i][j],可以看作是所有可能的公共子序列长度值的集合,其中包括了所有对于 A[1...i] 和 B[1...j](字符串 A 的前 i 个字符和字符串 B 的前 j 个字符)可能形成的公共子序列的长度。dp[i][j] 则是这个集合中的最大值。
假设 A = "ABCBDAB" 和 B = "BDCAB":
-
dp[2][3]代表 "AB" 和 "BDC" 的所有可能公共子序列长度的集合。这个集合包括长度为 0 的序列(如果没有公共元素),长度为 1 的序列(如果某个字符在两者中都出现),可能还有长度为 2 的序列(如果两个字符都按顺序出现在两者中)。但是在这个例子中,"AB" 和 "BDC" 的最长公共子序列的长度是 1,即集合中的最大值。 -
形象一点
dp[i][j]看作一个容器,其中包含所有从字符串A的前i个字符和字符串B的前j个字符中抽取字符(保持各自的顺序不变)能得到的公共子序列长度。dp[i][j]就是这个容器中的最大值。
状态转移
- 为了求得
dp[i][j],考虑A[i]和B[j]这两个字符的关系:- 如果
A[i]等于B[j],那么这个字符一定在A和B的最长公共子序列中。我们可以在不包含A[i]和B[j]的子序列的基础上增加这个字符,即dp[i][j] = dp[i-1][j-1] + 1。 - 如果
A[i]不等于B[j],那么A[i]和B[j]不可能同时出现在A和B的公共子序列中。此时,需要在两个选择中取最长的那个:- 不包含
A[i]的子序列,即dp[i][j] = dp[i-1][j]。 - 不包含
B[j]的子序列,即dp[i][j] = dp[i][j-1]。
- 不包含
- 如果
因此,状态转移方程为:
dp[i][j] = dp[i-1][j-1] + 1,如果 A[i] 等于 B[j];
dp[i][j] = max(dp[i-1][j], dp[i][j-1]),如果 A[i] 不等于 B[j]。
初始状态
dp[0][j]和dp[i][0]代表其中一个字符串的长度为 0,因此最长公共子序列长度为 0。
最终状态
dp[N][M]是字符串A和B的最长公共子序列的长度。
不是很“难”bia,稍微画画理解一下就可以啦
代码就简单了
# len1,len2 = 4,5
N = input()
str1 = "".join(input().split())
str2 = "".join(input().split())
len1 = len(str1)
len2 = len(str2)
dp = [[0 for _ in range(len2+10)]for _ in range(len1+10)]
for i in range(1,len1+1):
for j in range(1,len2+1):
if str2[j-1]==str1[i-1]:
dp[i][j]=dp[i-1][j-1]+1
else:
dp[i][j]=max(dp[i-1][j],dp[i][j-1])
print(dp[len1][len2])

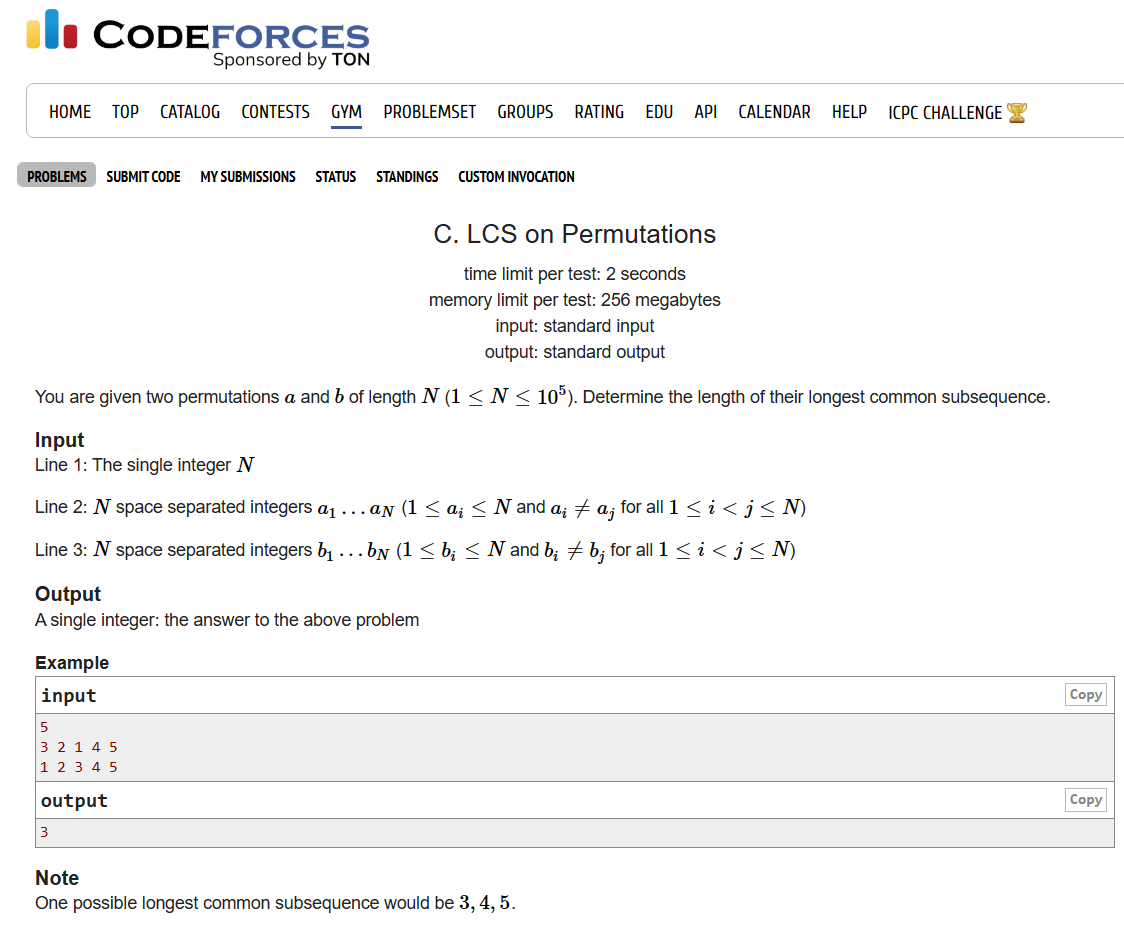
例题:排序的LCS
https://codeforces.com/gym/102951/problem/C
N = int(input().strip())
a = list(map(int, input().split()))
b = list(map(int, input().split()))
index_in_b = {b[i]: i for i in range(N)}
dp = [[0 for i in range(N+1)] for _ in range(N+1)]
for i in range(1, N + 1):
for j in range(1, N + 1):
# 加速索引
if index_in_b[a[i-1]] == j-1:
dp[i][j]=dp[i-1][j-1]+1
else:
dp[i][j]=max(dp[i-1][j],dp[i][j-1])
print(dp[N][N])
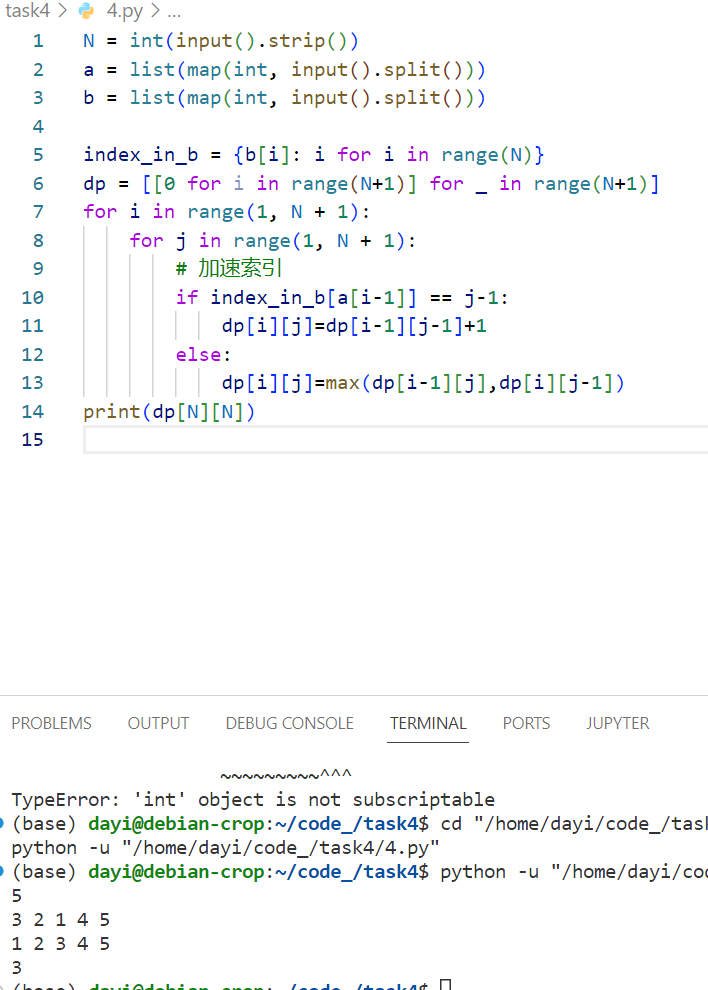
上述代码
PyPy 3-64 Memory limit exceeded on test 52 530 ms 262100 KB
优化下内存:
N = int(input().strip())
a = list(map(int, input().split()))
b = list(map(int, input().split()))
index_in_b = {b[i]: i for i in range(N)}
dp = [0 for i in range(N+1)]
for i in range(1, N + 1):
# 持有上一行的值
pre = 0
for j in range(1, N + 1):
temp = dp[j]
if index_in_b[a[i-1]] == j-1:
dp[j] = pre + 1
else:
dp[j] = max(dp[j], dp[j-1])
pre = temp
print(dp[N])
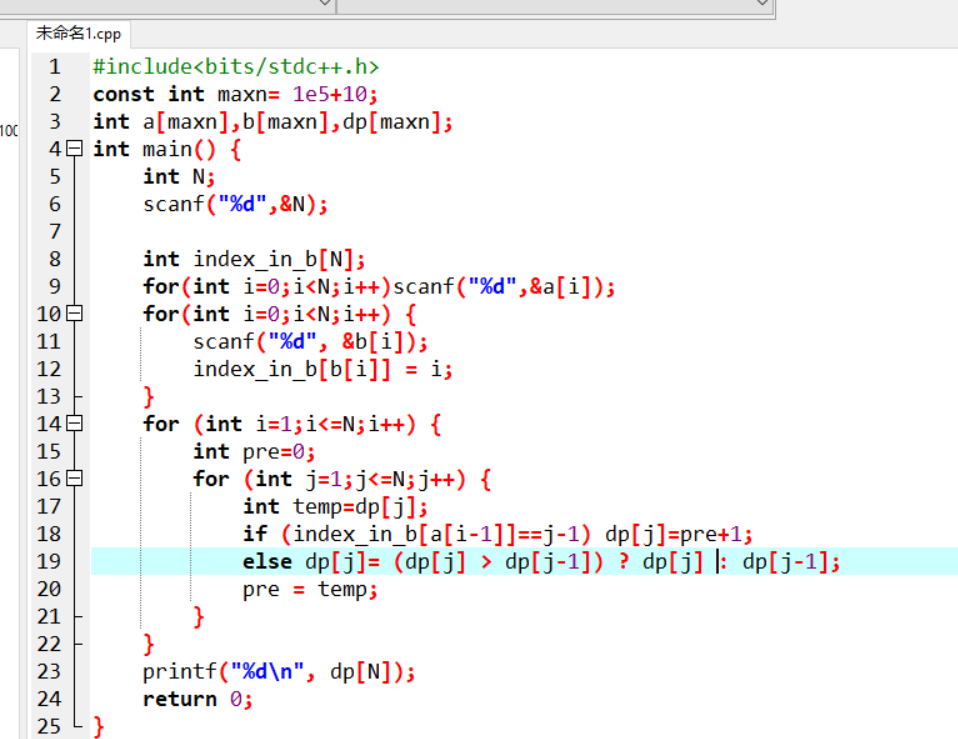
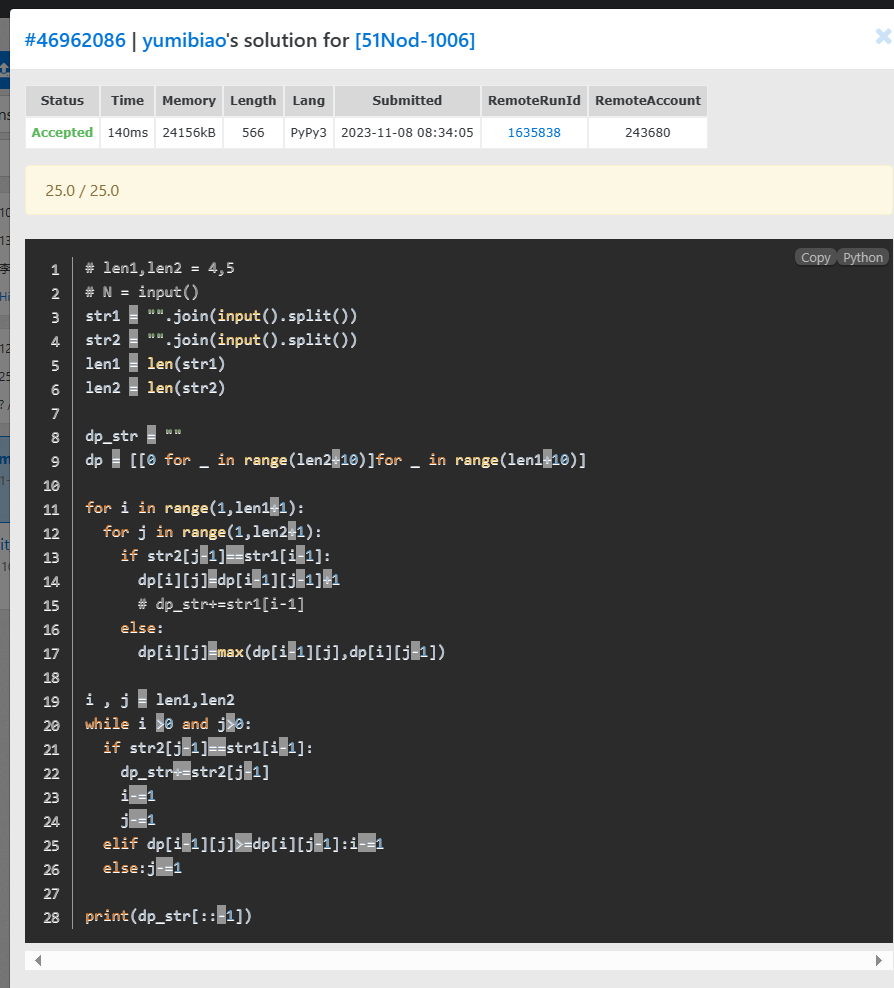
最后改成C语言也还是不行,这个题目估计没这么简单hhh,不过已经算完成了。(能过52个点PVP)
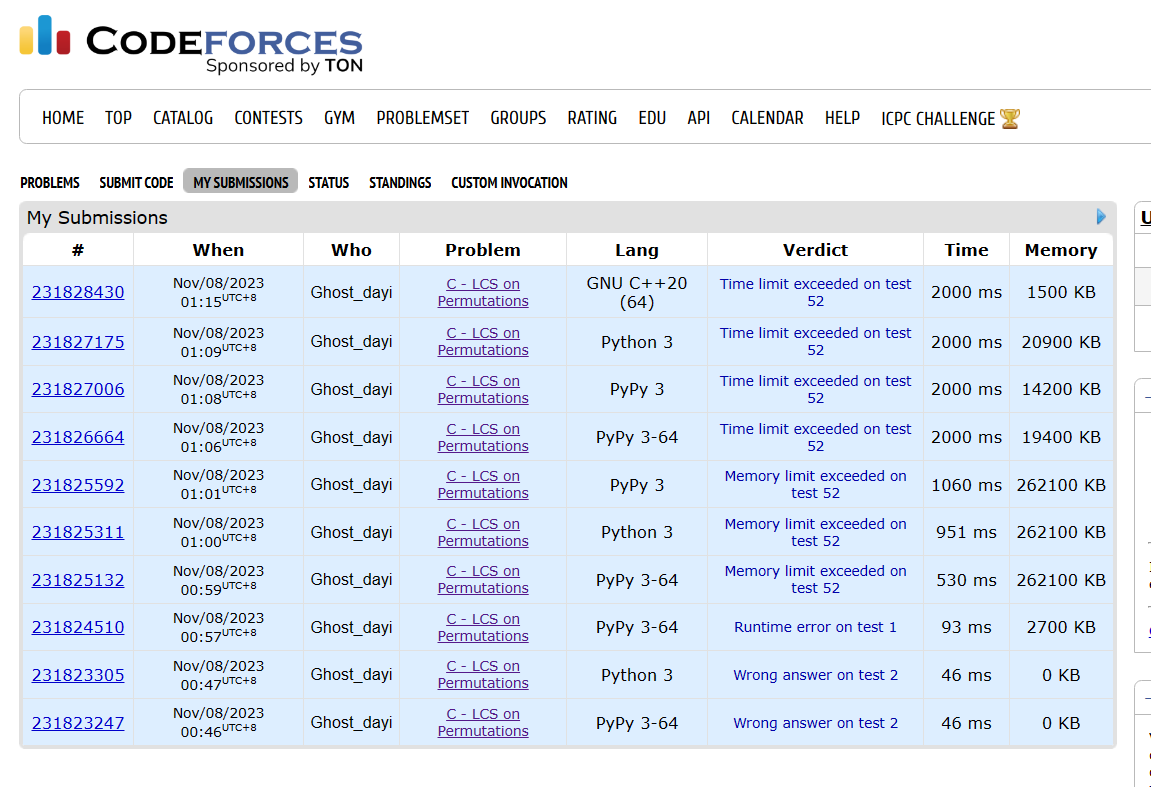
找到另外一个题:
https://vjudge.net/problem/51Nod-1006
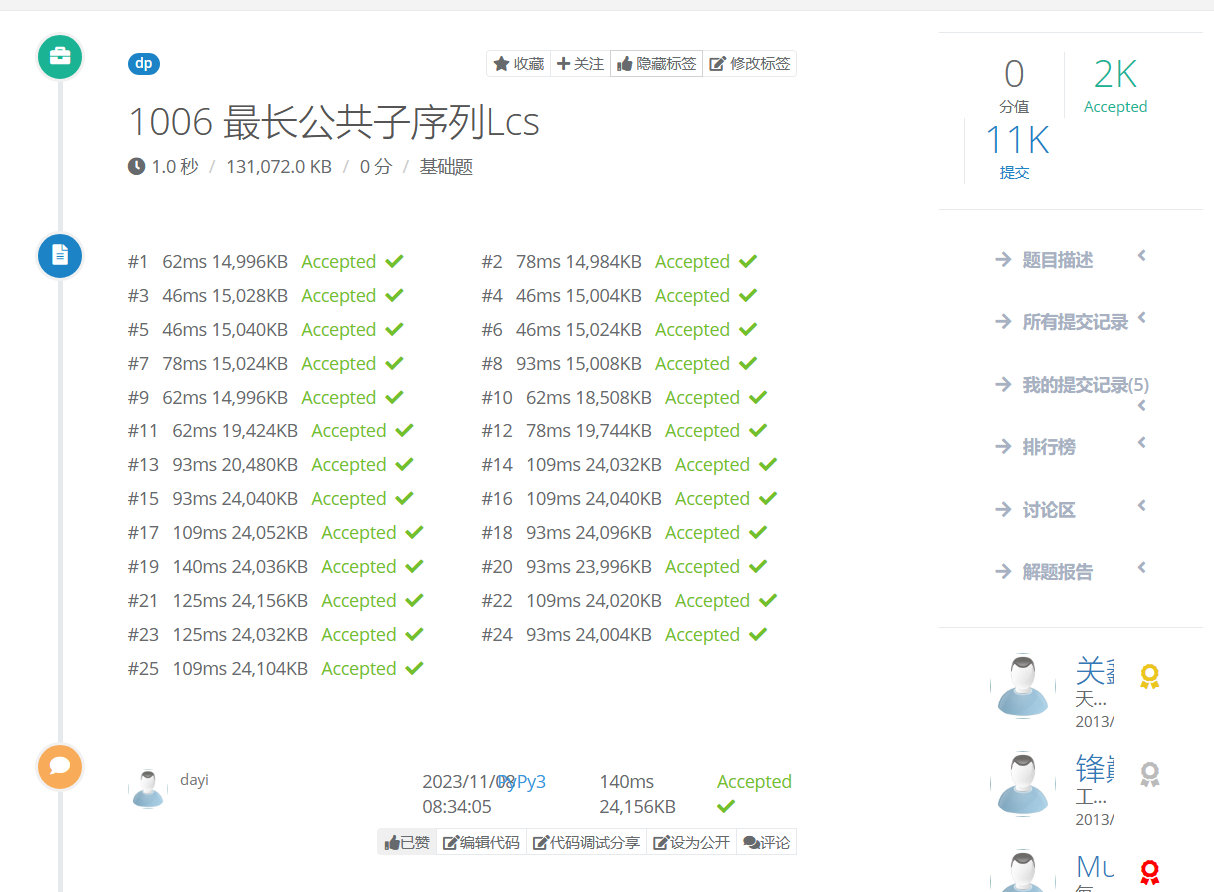
时间复杂度
假设字符串A的长度为N,字符串B的长度为M,则算法的时间复杂度为\(O(N*M)\)。
- 外层循环从i=1到N,共执行N次。
- 内层循环从j=1到M,共执行M次。
因此,总的时间复杂度为\(O(N*M)\)
5.最长递增子序列问题
给定长度为 N 的数组 arr,找到最长的子序列,使得这个子序列中的元素单调递增。
集合表示
- 定义
dp[i]表示以arr[i]结尾的最长递增子序列的长度。- 对于数组
[3, 4, 5, 1],dp[3]表示以元素5结尾的最长递增子序列的长度。
- 对于数组
再者:
dp[i] 表示的是以下集合中最大的长度:
- 以
arr[i]结尾的所有可能递增子序列的长度的集合。
数组arr中的第i个元素arr[i],集合可以表述为所有下标j(j < i)的子序列,使得arr[j] < arr[i]并且j到i之间没有比arr[i]更大的元素。
例如,给定数组(这里数组下标从1开始) arr = [10, 9, 2, 5, 3, 7, 101, 18],考虑计算 dp[5], arr[5](值为 3)结尾的最长递增子序列的长度。集合中包括的是:
[2, 3],以2结尾的递增子序列再加上3,递增子序列长度为2[3],只包含3本身的子序列,递增子序列长度为1
dp[5]将是上述集合中长度最大的值,即2。
状态转移
- 为了计算
dp[i],需要检查在arr[i]之前的所有元素,并找出以这些元素结尾的最长递增子序列,在满足递增条件的前提下,将arr[i]添加到这些子序列中。- 如果
arr[j] < arr[i],其中j < i,则可以将arr[i]添加到以arr[j]结尾的递增子序列中,形成一个新的递增子序列。这意味着dp[i]至少可以是dp[j] + 1。
- 如果
- 因此,状态转移方程为:
dp[i] = max(dp[j] + 1) ,0 <= j < i 且 arr[j] < arr[i]。
初始状态
- 对于任何数组,长度至少为 1 的递增子序列显然包含它自己,因此
dp[i]的初始值都为 1。
最终状态
dp[N]为最大值。
https://www.luogu.com.cn/problem/B3637
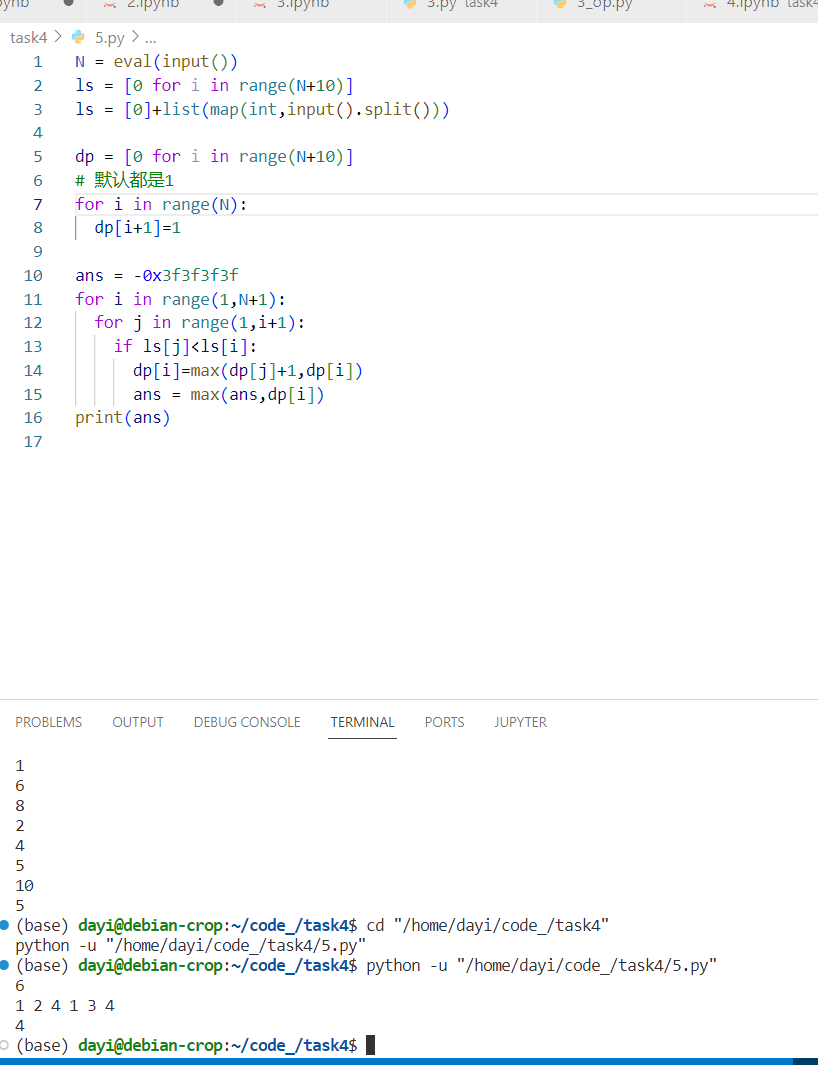
N = eval(input())
ls = [0 for i in range(N+10)]
ls = [0]+list(map(int,input().split()))
dp = [0 for i in range(N+10)]
# 默认都是1
for i in range(N):
dp[i+1]=1
ans = -0x3f3f3f3f
for i in range(1,N+1):
for j in range(1,i+1):
if ls[j]<ls[i]:
dp[i]=max(dp[j]+1,dp[i])
ans = max(ans,dp[i])
print(ans)

时间复杂度 \(O(n^2)\)
这题还可以贪心,能到 \(O(nlog_n)\)
二、总结
1. 爬楼梯问题
问题本质上是斐波那契数列的变种,通过简单的状态转移方程即可求解。对于大数的情况,矩阵快速幂可以有效降低时间复杂度。
2. 整数拆分问题
计数DP,通过二维动态规划表来跟踪每个拆分的情况。
3. 0-1 背包问题
太经典了,这里写了多重背包。
4. 最长公共子序列问题
二维数组来跟踪两个字符串的每个子序列的匹配情况,利用状态转移方程来更新最长公共子序列的长度。
5. 最长递增子序列问题
一维数组来存储以每个元素结尾的最长递增子序列的长度,并通过比较和更新这些长度来找到最长的递增子序列。
DP
- 动态规划的特点:动态规划适合解决具有重叠子问题和最优子结构特性的问题。通过存储中间结果来避免重复计算,可以大幅提高效率。
- 状态定义和转移:在动态规划中,合理定义状态并找到正确的状态转移方程是解决问题的关键。
- 时间复杂度:动态规划通常能将时间复杂度从指数级别降低到多项式级别
都是一些简单滴DP入门题目,很经典但是很有意义啦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号