

缓存穿透、缓存击穿、缓存雪崩,以及这些问题的常用解决方法。
在介绍这三大问题之前,我们需要先了解Redis作为一个缓存中间件,在项目中是如何工作的。首先看一下在没有缓存中间件的时候的系统数据访问的架构图:
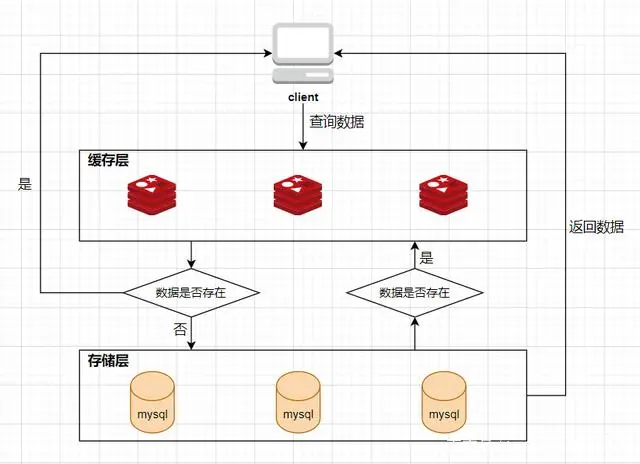
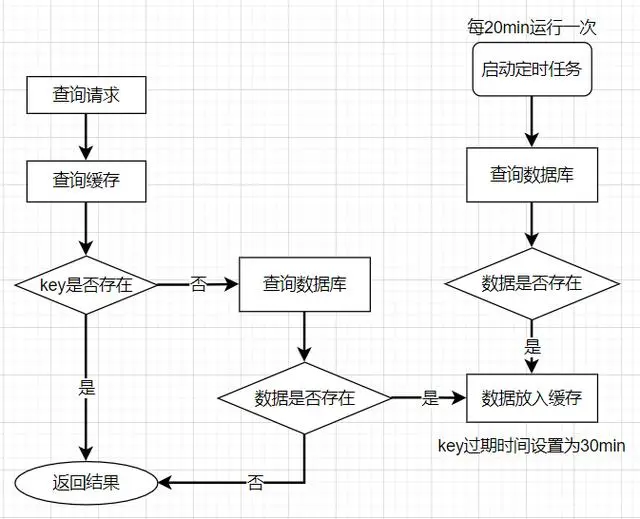
客户端发起一个查询请求的时候,首先去缓存中查询,如果数据在缓存中存在,则直接将缓存中的数据返回给客户端;如果数据在缓存中不存在,则继续查询数据库,如果数据在数据库中存在,则将该数据放入缓存中,并返回给客户端,如果数据在数据库中也不存在,则直接返回null给客户端。
什么是缓存穿透
缓存穿透是指查询一个缓存中和数据库中都不存在的数据,导致每次查询这条数据都会透过缓存,直接查库,最后返回空。当用户使用这条不存在的数据疯狂发起查询请求的时候,对数据库造成的压力就非常大,甚至可能直接挂掉。这种情况的流程就变成下图这样了:
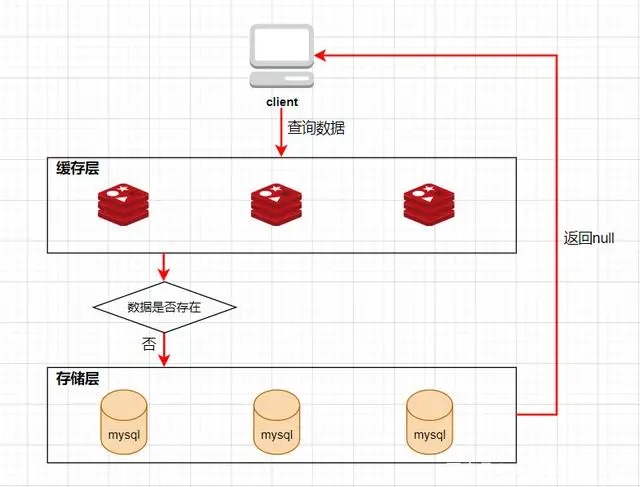
缓存穿透解决方案
解决缓存穿透的方法一般有两种,第一种是缓存空对象,第二种是使用布隆过滤器。
第一种方法比较好理解,就是当数据库中查不到数据的时候,我缓存一个空对象,然后给这个空对象的缓存设置一个过期时间,这样下次再查询该数据的时候,就可以直接从缓存中拿到,从而达到了减小数据库压力的目的。但这种解决方式有两个缺点:(1)需要缓存层提供更多的内存空间来缓存这些空对象,当这种空对象很多的时候,就会浪费更多的内存;(2)会导致缓存层和存储层的数据不一致,即使在缓存空对象时给它设置了一个很短的过期时间,那也会导致这一段时间内的数据不一致问题。
第二种方案是使用布隆过滤器,这是比较推荐的方法。所谓布隆过滤器,就是一种数据结构,它是由一个长度为m bit的位数组与n个hash函数组成的数据结构,位数组中每个元素的初始值都是0。在初始化布隆过滤器时,会先将所有key进行n次hash运算,这样就可以得到n个位置,然后将这n个位置上的元素改为1。这样,就相当于把所有的key保存到了布隆过滤器中了。
举个例子,比如我们一共有3个key,我们对这3个key分别进行3次hash运算,key1经过三次hash运算后的结果分别为2/6/10,那么就把布隆过滤器中下标为2/6/10的元素值更新为1,然后再分别对key2和key3做同样操作,结果如下图:

这样,当客户端查询时,也对查询的key做3次hash运算得到3个位置,然后看布隆过滤器中对应位置元素的值是否为1,如果所有对应位置元素的值都为1,就证明key在库中存在,则继续向下查询;如果3个位置中有任意一个位置的值不为1,那么就证明key在库中不存在,直接返回客户端空即可。如下图:
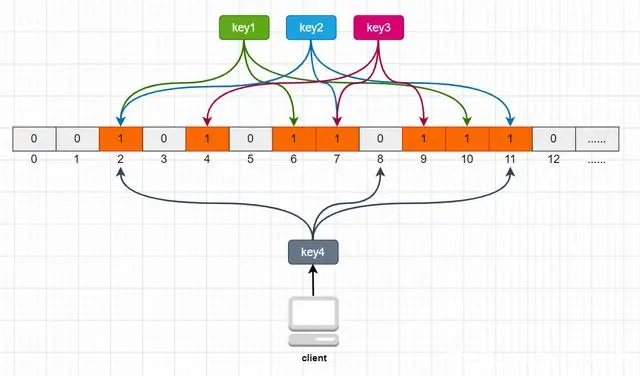
当客户端查询key4时,key4的3次hash运算中,有一个位置8的值为0,就说明key4在库中不存在,直接返回客户端空即可。
所以,布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在。如下图:
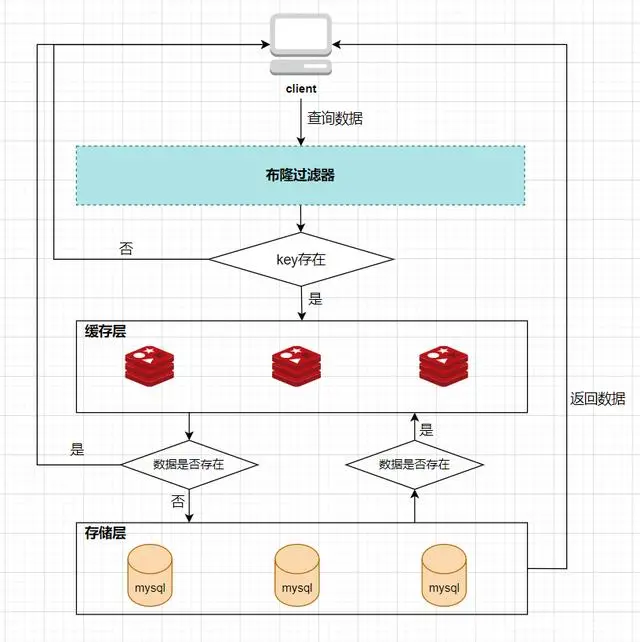
布隆过滤器的好处就是解决了第一种缓存空值的不足,但布隆过滤器也存在缺陷,首先,它有误判的可能,比如在上面客户端查询key4的图中,假如key4经过3次hash运算得到的位置分别是2/4/6,由于这3个位置的值都是1,所以,布隆过滤器就认为key4在库中存在,进而继续向下查询了。所以,布隆过滤器判断存在的key实际上可能是不存在的,但布隆过滤器判断不存在的key是一定不存在的。它的第二个缺点就是删除元素比较难,比如现在要删除key2这个元素,那么需要将2/7/11三个位置的元素值改为0,但这样就会影响到key1和key3的判断。
什么是缓存击穿
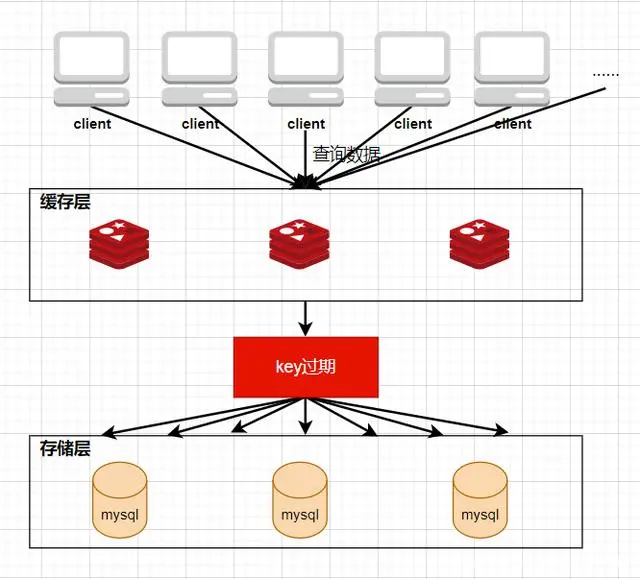
缓存击穿是指当缓存中某个热点数据过期了,在该热点数据重新载入缓存之前,有大量的查询请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉。
缓存击穿解决方案
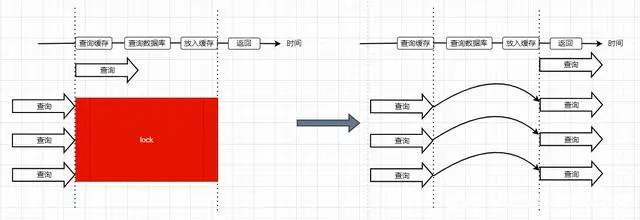
解决缓存击穿的方法也有两种,第一种是设置key永不过期;第二种是使用分布式锁,保证同一时刻只能有一个查询请求重新加载热点数据到缓存中,这样,其他的线程只需等待该线程运行完毕,即可重新从Redis中获取数据。
第一种方式比较简单,在设置热点key的时候,不给key设置过期时间即可。不过还有另外一种方式也可以达到key不过期的目的,就是正常给key设置过期时间,不过在后台同时启一个定时任务去定时地更新这个缓存。
第二种方式使用了加锁的方式,锁的对象就是key,这样,当大量查询同一个key的请求并发进来时,只能有一个请求获取到锁,然后获取到锁的线程查询数据库,然后将结果放入到缓存中,然后释放锁,此时,其他处于锁等待的请求即可继续执行,由于此时缓存中已经有了数据,所以直接从缓存中获取到数据返回,并不会查询数据库。
什么是缓存雪崩
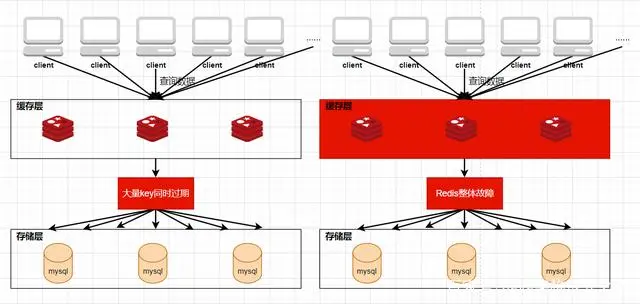
缓存雪崩是指当缓存中有大量的key在同一时刻过期,或者Redis直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉。
缓存雪崩解决方案
针对第一种大量key同时过期的情况,解决起来比较简单,只需要将每个key的过期时间打散即可,使它们的失效点尽可能均匀分布。
针对第二种redis发生故障的情况,部署redis时可以使用redis的几种高可用方案部署,部署方法可以参考我之前的文章Redis高可用方案—主从(masterslave)架构、Redis高可用架构—哨兵(sentinel)机制详细介绍、Redis高可用架构—Redis集群(Redis Cluster)详细介绍。
除了上面两种解决方式,还可以使用其他策略,比如设置key永不过期、加分布式锁等。

