

Java 并发编程学习1 可见性、原子性和有序性问题
并发编程的背后
这些年,我们的 CPU、内存、I/O 设备都在不断迭代,不断朝着更快的方向努力。但是,在这个快速发展的过程中,有一个核心矛盾一直存在,就是这三者的速度差异。
为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU 增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
现在我们几乎所有的程序都默默地享受着这些成果,但是天下没有免费的午餐,并发程序很多诡异问题的根源也在这里。
源头之一:缓存导致的可见性问题
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
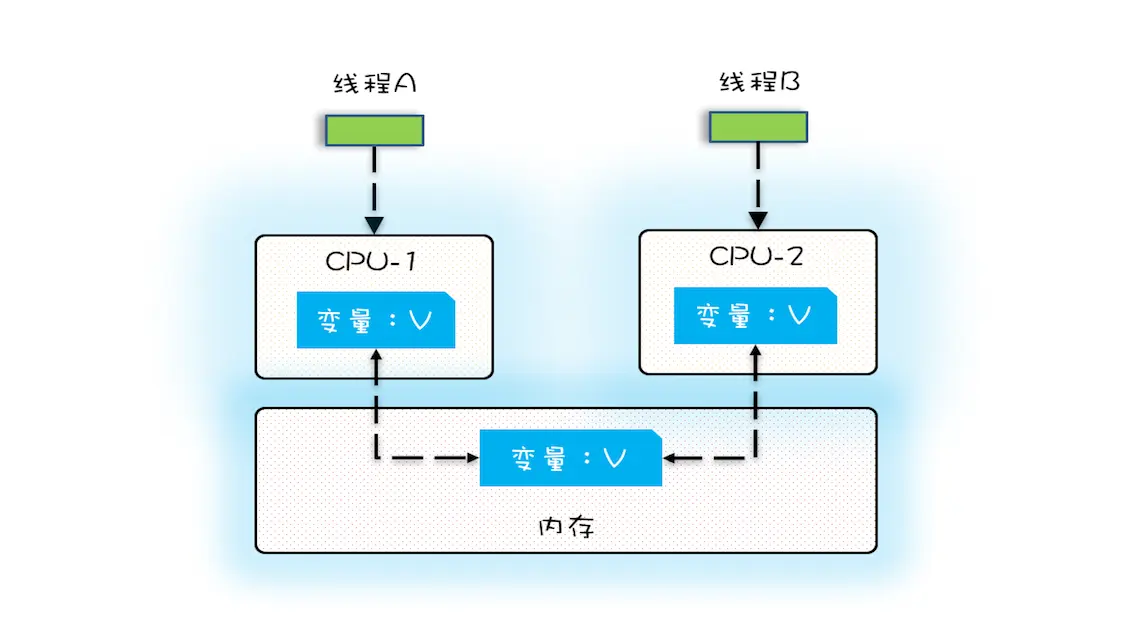
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。
举个栗子:



1 public class Test { 2 private long count = 0; 3 private void add10K() { 4 int idx = 0; 5 while(idx++ < 10000) { 6 count += 1; 7 } 8 } 9 public static long calc() { 10 final Test test = new Test(); 11 // 创建两个线程,执行add()操作 12 Thread th1 = new Thread(()->{ 13 test.add10K(); 14 }); 15 Thread th2 = new Thread(()->{ 16 test.add10K(); 17 }); 18 // 启动两个线程 19 th1.start(); 20 th2.start(); 21 // 等待两个线程执行结束 22 th1.join(); 23 th2.join(); 24 return count; 25 } 26 }
直觉告诉我们应该是 20000,因为在单线程里调用两次 add10K() 方法,count 的值就是 20000,但实际上 calc() 的执行结果是个 10000 到 20000 之间的随机数。为什么呢?
我们假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。
循环 10000 次 count+=1 操作如果改为循环 1 亿次,你会发现效果更明显,最终 count 的值接近 1 亿,而不是 2 亿。如果循环 10000 次,count 的值接近 20000,原因是两个线程不是同时启动的,有一个时差。
源头之二:线程切换带来的原子性问题
由于 IO 太慢,早期的操作系统就发明了多进程,即便在单核的 CPU 上我们也可以一边听着歌,一边写 Bug,这个就是多进程的功劳。
操作系统允许某个进程执行一小段时间,例如 50 毫秒,过了 50 毫秒操作系统就会重新选择一个进程来执行(我们称为“任务切换”),这个 50 毫秒称为“时间片”。
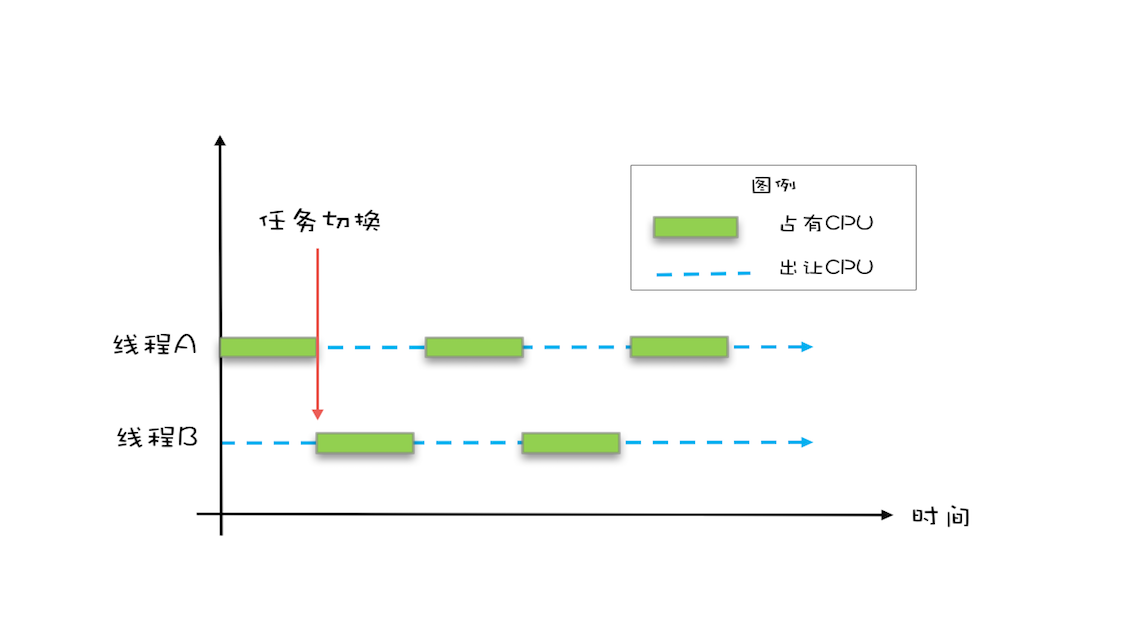
早期的操作系统基于进程来调度 CPU,不同进程间是不共享内存空间的,所以进程要做任务切换就要切换内存映射地址,而一个进程创建的所有线程,都是共享一个内存空间的,所以线程做任务切换成本就很低了。现代的操作系统都基于更轻量的线程来调度,现在我们提到的“任务切换”都是指“线程切换”。
Java 并发程序都是基于多线程的,自然也会涉及到任务切换,也许你想不到,任务切换竟然也是并发编程里诡异 Bug 的源头之一。任务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条 CPU 指令完成,例如上面代码中的count += 1,至少需要三条 CPU 指令。
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条 CPU 指令执行完,是的,是 CPU 指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设 count=0,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。
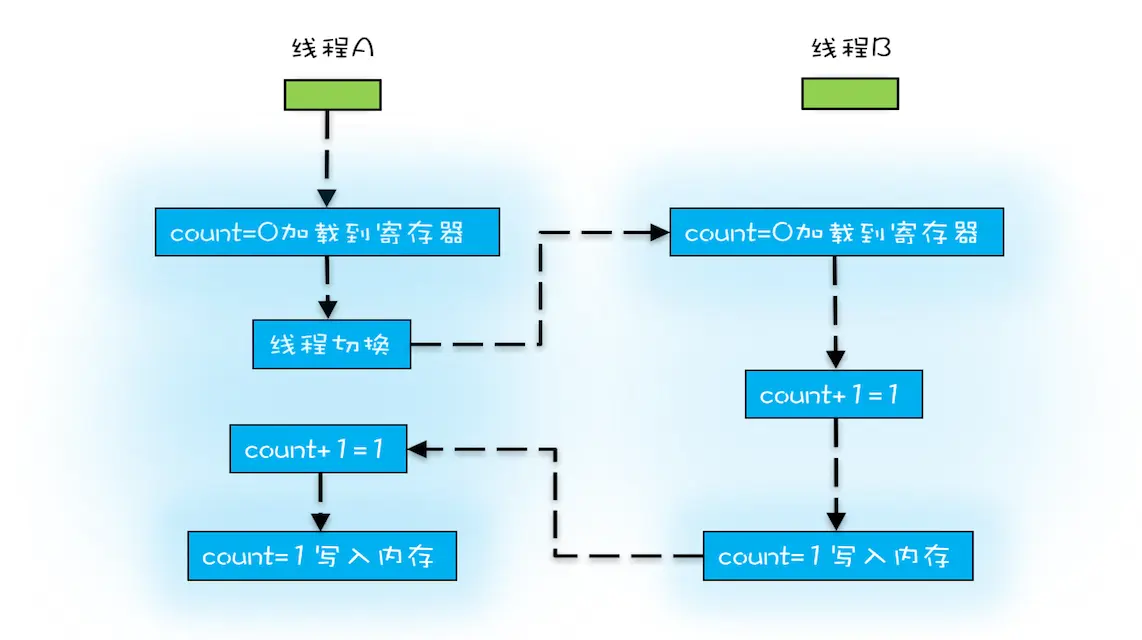
我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在 count+=1 之前,也可以发生在 count+=1 之后,但就是不会发生在中间。我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。CPU 能保证的原子操作是 CPU 指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
源头之三:编译优化带来的有序性问题
那并发编程里还有没有其他有违直觉容易导致诡异 Bug 的技术呢?有的,就是有序性。顾名思义,有序性指的是程序按照代码的先后顺序执行。编译器为了优化性能,有时候会改变程序中语句的先后顺序。
在 Java 领域一个经典的案例就是利用双重检查创建单例对象,例如下面的代码:在获取实例 getInstance() 的方法中,我们首先判断 instance 是否为空,如果为空,则锁定 Singleton.class 并再次检查 instance 是否为空,如果还为空则创建 Singleton 的一个实例。
1 public class Singleton { 2 static Singleton instance; 3 static Singleton getInstance(){ 4 if (instance == null) { 5 synchronized(Singleton.class) { 6 if (instance == null) 7 instance = new Singleton(); 8 } 9 } 10 return instance; 11 } 12 }
假设有两个线程 A、B 同时调用 getInstance() 方法,他们会同时发现 instance == null ,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
这看上去一切都很完美,无懈可击,但实际上这个 getInstance() 方法并不完美。问题出在哪里呢?出在 new 操作上,我们以为的 new 操作应该是:
- 分配一块内存 M;
- 在内存 M 上初始化 Singleton 对象;
- 然后 M 的地址赋值给 instance 变量。
但是实际上优化后的执行路径却是这样的:
- 分配一块内存 M;
- 将 M 的地址赋值给 instance 变量;
- 最后在内存 M 上初始化 Singleton 对象。
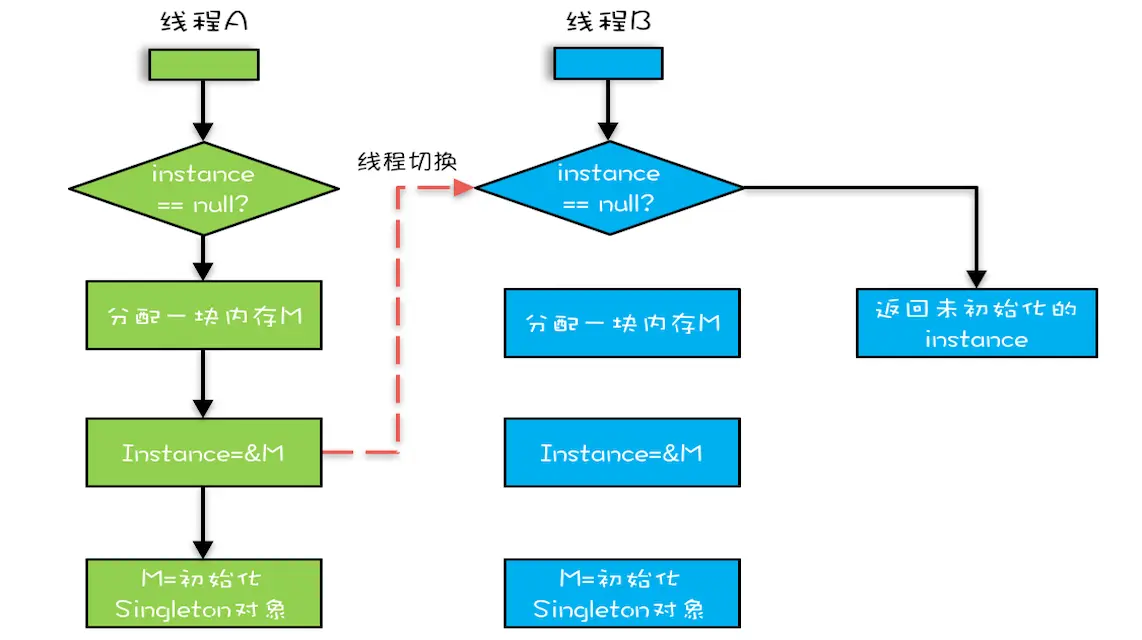
优化后会导致什么问题呢?我们假设线程 A 先执行 getInstance() 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance() 方法,那么线程 B 在执行第一个判断时会发现 instance != null ,所以直接返回 instance,而此时的 instance 是没有初始化的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。
问答
1、对于双重锁检查那个例子,我有一个疑问,A如果没有完成实例的初始化,锁应该不会释放的,B是拿不到锁的,怎么还会出问题呢?
答:CPU时间片切换后,线程B刚好执行到第一次判断instance==null,此时不为空,不用进入synchronized里,就将还未初始化的instance返回了
线程A进入第二个判空条件,进行初始化时,发生了时间片切换,即使没有释放锁,线程B刚要进入第一个判空条件时,发现条件不成立,直接返回instance引用,不用去获取锁。如果对instance进行volatile语义声明,就可以禁止指令重排序,避免该情况发生。
理解
对于可见性那个例子我们先看下定义:
可见性:一个线程对共享变量的修改,另外一个线程能够立刻看到
并发问题往往都是综合证,这里即使是单核CPU,只要出现线程切换就会有原子性问题。但老师的目的是为了让大家明白什么是可见性
或许我们可以把线程对变量的读可写都看作时原子操作,也就是cpu对变量的操作中间状态不可见,这样就能更加理解什么是可见性了。
------CPU缓存刷新到内存的时机------
cpu将缓存写入内存的时机是不确定的。除非你调用cpu相关指令强刷
------双重锁问题------
如果A线程与B线程如果同时进入第一个分支,那么这个程序就没有问题
如果A线程先获取锁并出现指令重排序时,B线程未进入第一个分支,那么就可能出现空指针问题,这里说可能出现问题是因为当把内存地址赋值给共享变量后,CPU将数据写回缓存的时机是随机的
------ synchronized------
线程在synchronized块中,发生线程切换,锁是不会释放的
------指令优化------
除了编译优化,有一部分可以通过看汇编代码来看,但是CPU和解释器在运行期也会做一部分优化,所以很多时候都是看不到的,也很难重现。
------JMM模型和物理内存、缓存等关系------
内存、cpu缓存是物理存在,jvm内存是软件存在的。
关于线程的工作内存和寄存器、cpu缓存的关系 大家可以参考这篇文章
https://blog.csdn.net/u013851082/article/details/70314778/
------IO操作------
io操作不占用cpu,读文件,是设备驱动干的事,cpu只管发命令。发完命令,就可以干别的事情了。
------寄存器切换------
寄存器是共用的,A线程切换到B线程的时候,寄存器会把操作A的相关内容会保存到内存里,切换回来的时候,会从内存把内容加载到寄存器。可以理解为每个线程有自己的寄存器


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具