

mysql学习 实践(3) 字符串字段怎么加索引
总结
对于字符串创建索引的情况,总结如下
1、直接创建完整索引,这样可能会比较占空间
2、船用前缀索引,节省空间,但是会增加扫描次数,并且不能使用前缀索引;
3、倒序存储,再创建前缀索引,用于绕过字符串本身区分度不够的问题;
4、创建哈希字段索引,查询性能稳定,但是要增加字段,有额外的存储和计算消耗,和倒序存储一样,都不支持范围扫描
问答
1、对于用户表
1 mysql> create table SUser( 2 ID bigint unsigned primary key, 3 email varchar(64), 4 ... 5 )engine=innodb;
在email字段上创建索引
mysql> alter table SUser add index index1(email); 或 mysql> alter table SUser add index index2(email(6));
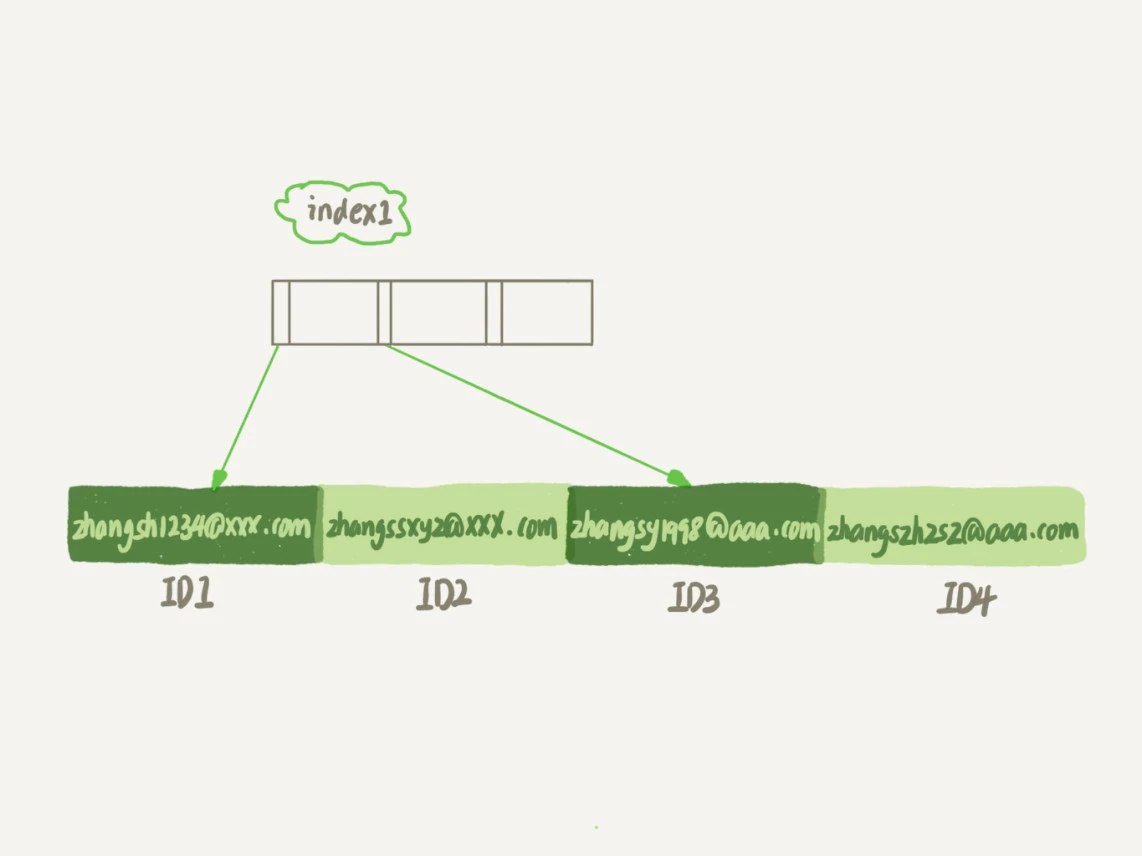
第一个语句创建的 index1 索引里面,包含了每个记录的整个字符串;而第二个语句创建的 index2 索引里面,对于每个记录都是只取前 6 个字节。
索引如图:
执行:
1 select id,name,email from SUser where email='zhangssxyz@xxx.com';
采用整个字符串作为索引。 在查询操作时, 执行顺序是怎样的?
答:
如果使用的是 index1(即 email 整个字符串的索引结构),执行顺序是这样的:
从 index1 索引树找到满足索引值是’zhangssxyz@xxx.com’的这条记录,取得 ID2 的值;
到主键上查到主键值是 ID2 的行,判断 email 的值是正确的,将这行记录加入结果集;
取 index1 索引树上刚刚查到的位置的下一条记录,发现已经不满足 email='zhangssxyz@xxx.com’的条件了,循环结束。
这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
2、如上述定义,采用部分字符串作为索引,执行顺序是?
答:
从 index2 索引树找到满足索引值是’zhangs’的记录,找到的第一个是 ID1;
到主键上查到主键值是 ID1 的行,判断出 email 的值不是’zhangssxyz@xxx.com’,这行记录丢弃;
取 index2 上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出 ID2,再到 ID 索引上取整行然后判断,这次值对了,将这行记录加入结果集;
重复上一步,直到在 idxe2 上取到的值不是’zhangs’时,循环结束。
在这个过程中,要回主键索引取 4 次数据,也就是扫描了 4 行。通过这个对比,你很容易就可以发现,使用前缀索引后,可能会导致查询语句读数据的次数变多。
但是,对于这个查询语句来说,如果你定义的 index2 不是 email(6) 而是 email(7),也就是说取 email 字段的前 7 个字节来构建索引的话,即满足前缀’zhangss’的记录只有一个,也能够直接查到 ID2,只扫描一行就结束了。
也就是说使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
3、使用什么语句可以分析不同长度前缀的索引区分度是多少?
答:实际上,我们在建立索引时关注的是区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。因此,我们可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。
首先,你可以使用下面这个语句,算出这个列上有多少个不同的值:
1 mysql> select count(distinct email) as L from SUser;
然后,依次选取不同长度的前缀来看这个值,比如我们要看一下 4~7 个字节的前缀索引,可以用这个语句:
1 mysql> select 2 count(distinct left(email,4))as L4, 3 count(distinct left(email,5))as L5, 4 count(distinct left(email,6))as L6, 5 count(distinct left(email,7))as L7, 6 from SUser;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如 5%。然后,在返回的 L4~L7 中,找出不小于 L * 95% 的值,假设这里 L6、L7 都满足,你就可以选择前缀长度为 6。
4、前缀索引相比较整个字段做索引有什么优势和劣势?
答:
好处:
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
坏处:
- 使用前缀索引,可能会增加扫描行数,这会影响到性能。
- 使用前缀索引就用不上覆盖索引对查询性能的优化
如下场景:
select id,email from SUser where email='zhangssxyz@xxx.com';
与前面例子中的 SQL 语句:
select id,name,email from SUser where email='zhangssxyz@xxx.com';
相比,这个语句只要求返回 id 和 email 字段。
所以,如果使用 index1(即 email 整个字符串的索引结构)的话,可以利用覆盖索引,从 index1 查到结果后直接就返回了,不需要回到 ID 索引再去查一次。
而如果使用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。即使你将 index2 的定义修改为 email(18) 的前缀索引,这时候虽然 index2 已经包含了所有的信息,但 InnoDB 还是要回到 id 索引再查一下,因为系统并不确定前缀索引的定义是否截断了完整信息。
5、采用反序存储和hash字段作为索引有什么异同点?
答:
相同点:
- 二者可以用来解决字符串前缀的区分度不够好的情况
- 占用空间更小,查询效率更高
- 都不支持范围查询,倒排由于破坏了原始的顺序,因此无法做范围查询,哈希只能做等值查询
区别:
- 从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
- 在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。如果只从这两个函数的计算复杂度来看的话,reverse 函数额外消耗的 CPU 资源会更小些。
- 从查询效率上看,使用 hash 字段方式的查询性能相对更稳定一些。因为 crc32 算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近 1。而倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
思考题
1、如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。系统登录的时候都需要学生输入登录名和密码,验证正确后才能继续使用系统。就只考虑登录验证这个行为的话,你会怎么设计这个登录名的索引呢?
答:
由于这个学号的规则,无论是正向还是反向的前缀索引,重复度都比较高。因为维护的只是一个学校的,因此前面 6 位(其中,前三位是所在城市编号、第四到第六位是学校编号)其实是固定的,邮箱后缀都是 @gamil.com,因此可以只存入学年份加顺序编号,它们的长度是 9 位。
而其实在此基础上,可以用数字类型来存这 9 位数字。比如 201100001,这样只需要占 4 个字节。其实这个就是一种 hash,只是它用了最简单的转换规则:字符串转数字的规则,而刚好我们设定的这个背景,可以保证这个转换后结果的唯一性。
评论区中,也有其他一些很不错的见解。
1)一个学校的总人数这种数据量,50 年才 100 万学生,这个表肯定是小表。为了业务简单,直接存原来的字符串。这个答复里面包含了“优化成本和收益”的思想。
2)思考题的学号比较特殊,15位数字+固定后缀“@gmail.com”这种特殊的情况,由于整个学号的值超过了 int 上限,可以把学号使用bigint存储,占4个字节,比前缀索引空间占用要小。跟hash索引比,也有区间查询的优势
3)只取 四位年份+五位编号 并转化为int类型作为唯一主键
3)可以考虑根据字符串字段业务特性做进制压缩,业务上一般会限制每个字符的范围(如字母数字下划线)。
从信息论的角度看,每个字节并没有存8 bit的信息量。如果单个字符的取值只有n种可能性(把字符转成0到n-1的数字),可以考虑把n进制转为为更高进制存储(ascii可看做是128进制)。
这样既可以减少索引长度,又可以很大程度上兼顾前缀匹配。
这是另外一个极致的方向。如果碰到表数据量特别大的场景,通过这种方式的收益是很不错的。
注意:经评论提醒:
这种思路非常高级,但是会有很多细节,在这里,我尝试帮你解释一下这个过程的大致思路,具体情况还要具体分析。
假设一个学生的学号是 '20200517',这是一个长度为 8 的字符串,以asc编码为例,这个字符串需要占据 8 个字节的空间。
但是,你发现,这个字符串里面所有的内容都是数字,而一个数字有 10 种可能,也就是说,这个长度的学号最多有 10 ^ 8 种可能性,也就是一亿种可能性。
在计算机中,使用 32 位二进制数就可以表示 2 ^ 32 种可能性,这个数字是远远大于一亿的,所以也就是说,你完全可以用 4 字节的内存存下这个学号的所有信息(所以你完全可以使用 int 进行存储)。
所以,正面回答你的问题,在我的例子中,学号只有 一亿 种可能性,你可将它转化成 2^32 进制进行存储。
当然,只是最粗略的方法,你可以设计一种方法,将这种受限的字符串压缩,这样就能减少存储空间的利用了。
但是不建议这样做,这种操作可以将信息压缩到极致(实际上极值情况就和哈希有点像了),但是设计这种方法可能会增加复杂性,在数据规模没有达到极其庞大的底部,它带来的收益其实是有限的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通