js cookie 反爬
理论基础
取自《Python-3反爬虫原理与绕过实战》
Cookie不仅可以用于Web服务器的用户身份信息存储或状态保持,还能够用于反爬虫。大部分的爬虫程序在默认情况下只请求HTML文本资源,这意味着它们并不会主动完成浏览器保存Cookie的操作。Cookie反爬虫指的是服务器端通过校验请求头中的Cookie值来区分正常用户和爬虫程序的手段,这种手段被广泛应用在Web应用中,例如浏览器会自动检查响应头中是否存在Set-Cookie头域,如果存在,则将值保存在本地,而且往后的每次请求都会自动携带对应的Cookie值,这时候只要服务器端对请求头中的Cookie值进行校验即可。服务器会校验每个请求头中的Cookie值是否符合规则,如果通过校验,则返回正常资源,否则将请求重定向到首页,同时在响应头中添加Set-Cookie头域和Cookie值。
实战
观察
打开开发者工具,切换页面,看一看我们要爬取的目标的接口url是哪个

发现目标就是一串类似uuid的url,再看看html,那么其实这一串uuid组成的url我们是可以通过a标签获得的,现在只要爬取我们的目标的具体信息即可
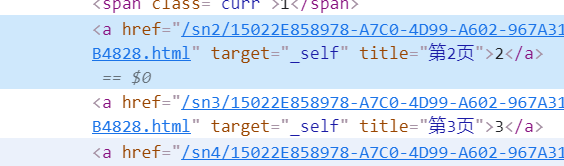
看一下我们的具体信息在html中是何种表现形式

可以看到也是一个a标签的形式,那么我们的思路就明确了
随便找一个uuid的url=>
通过详细信息的a标签中的链接爬取所有的详细信息=>
通过下一页的a标签中的链接访问下一页的url=>
一直循环直到页空的尽头
那我们写一个简单的爬虫看看能不能爬取到,直接用网站
import requests
cookies = {
'Hm_lvt_9511d505b6dfa0c133ef4f9b744a16da': '1631673117',
'ASP.NET_SessionId': 'xel3j5xxd5fxgu5rgv0cf2ms',
'spvrscode': 'abdc551c0bd7f81cca4e2804c23afe646e1a1904a5570f1e626ce42731a8b2bb7e2ac5430a0b4c2671adf2973523fe3be72a87e6e56c76657e1ac381a254570e7ac433db747372123549b582c4dfa98f60816aca302433f60fddfbff563c19556c1cb013f26eadbd5d81d8ffc0a22fae8275c1fd42b386c2ef1d085048ae3a9a544793a7c2307dd2',
'Hm_lpvt_9511d505b6dfa0c133ef4f9b744a16da': '1631685108',
}
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '"Microsoft Edge";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
response = requests.get('https://www.***.***/15022E858978-A7C0-4D99-A602-967A31FB4828.html', headers=headers, cookies=cookies)
print(response.text)

可恶世上果然没有简单的事情,我们遇到了高手,可以和学员说这个是个高手耶稣来了也救不了。。。。。。那是不可能的,继承自肉丝老师服务第一的传统,有困难就要解决,解决不了也要硬解决,还是拿起我的水壶边喝水边分析吧。拿出我多年未见的老朋友burpsuit(上次一别以是一年),一点一点的试一下,发送到repeater,一个一个的删除参数,最后终于定位到了是cookie中的spvrscode=,当它为空的时候会返回一串js代码,当cookie过期的时候他就会返回非授权访问,那么现在就用之前的cookie通杀脚本来进行定位cookie是如何生成的。
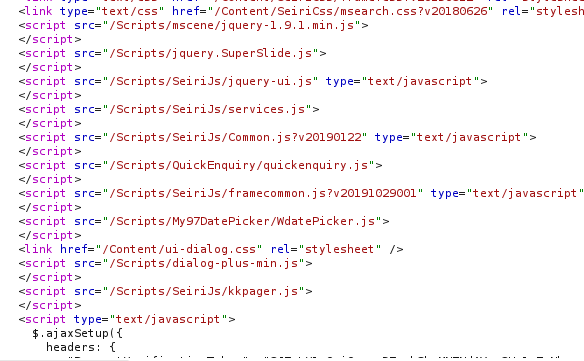
var cookie = document.cookie;
document = Object.defineProperty(document, 'cookie', {
get: function () {
console.log('getter: ' + cookie);
return cookie;
},
set: function (value) {
console.log('setter: ' + value);
cookie = value
}
});
先把数据和cookie都清一清,然后注意这里他会网页重定向刷新一次网页,这时候如果我们在script上下断点执行一次hook直接放开的话,重定向就会把我们的hook给刷新掉,所以可以使用油猴脚本hook或者在每个断点都运行一下hook脚本
最终定位到了这里
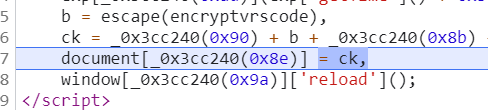
就是一个查看一下ck的值,看看是不是我们想要的结果

就是我们想要的cookie的值,那么这里就可以开始逆向工作了,一步一步的回溯ck是怎样生成的
ck=_0x3cc240(0x90) + b + _0x3cc240(0x8b) + exp[_0x3cc240(0x95)]() + ';'
_0x3cc240(0x90)='spvrscode='
b='e73fbff4ed0cd6bdd7a2b41a2b2c915ce7b0b047552752268c1ea11adfc9b5422c33f2ec7cfdc9fe0b7df5ca707503f80b0039c93e8636c6ac1063c135494a1a6254d35b623e2f4803a67ac44ec8c7e99f517d25fbec1f7dfbfb569004d7eef408ad6e675c4562172112e4e1da5f359d25e07e80915b71794669e0f88c6f11b39a0e5d34695d5bc9'//目标
...//剩下作用不大
接着追b
b = escape(encryptvrscode)
encryptvrscode='e73fbff4ed0cd6bdd7a2b41a2b2c915ce7b0b047552752268c1ea11adfc9b5422c33f2ec7cfdc9fe0b7df5ca707503f80b0039c93e8636c6ac1063c135494a1a6254d35b623e2f4803a67ac44ec8c7e99f517d25fbec1f7dfbfb569004d7eef408ad6e675c4562172112e4e1da5f359d25e07e80915b71794669e0f88c6f11b39a0e5d34695d5bc9'//目标
encryptvrscode = encrypted[_0x3cc240(0x97)][_0x3cc240(0x8f)]()
_0x3cc240(0x97)='ciphertext'
_0x3cc240(0x8f)='toString'
那么就继续追踪encrypted,探索一下子是个牛马对象
var keyHex = CryptoJS['enc'][_0x3cc240(0xa3)][_0x3cc240(0xa4)](a)
, encrypted = CryptoJS[_0x3cc240(0xa2)][_0x3cc240(0x8a)](b, keyHex, {
'mode': CryptoJS[_0x3cc240(0xaf)]['ECB'],
'padding': CryptoJS[_0x3cc240(0xa9)][_0x3cc240(0x99)]
})
CryptoJS....,眼前一亮,蓝师傅说过的加密库,翻译一下即可
_0x3cc240(0xa3)='Utf8'
_0x3cc240(0xa4)='parse'
a='eb74960d'
_0x3cc240(0xa2)=`DES`
_0x3cc240(0x8a)='encrypt'
_0x3cc240(0xa9)=`pad`
_0x3cc240(0x99)=`Pkcs7`
b='E04A051E2E4370CE3F2AB90D7ECF6CFAC225C8B8FC6076977E8546DC17C7F890D3D442529EEE9941C3BDE3766931B7C846F43BBB36E02E3ED90B87B40A96AEDF'//此b非彼b所以下面的结果和前面的不一样,下面用新的b开始
翻译一下
var keyHex = CryptoJS['enc']['Utf8']['parse']('eb74960d')
, encrypted = CryptoJS[`DES`]['encrypt'](b, keyHex, {
'mode': CryptoJS[`mode`]['ECB'],
'padding': CryptoJS[`pad`][`Pkcs7`]
})
这时候可以去看一下百度上CryptoJS的使用案例,我们就知道它的加密流程了,官方使用流程大概如下
var CryptoJS = require("crypto-js");
// Encrypt
var ciphertext = CryptoJS.AES.encrypt('my message', 'secret key 123').toString();
// Decrypt
var bytes = CryptoJS.AES.decrypt(ciphertext, 'secret key 123');
var originalText = bytes.toString(CryptoJS.enc.Utf8);
console.log(originalText); // 'my message'
其实这就是一个DES加密的ECB模式,那么我们可以找一个网站试一下(密钥又换了又刷新了一下)
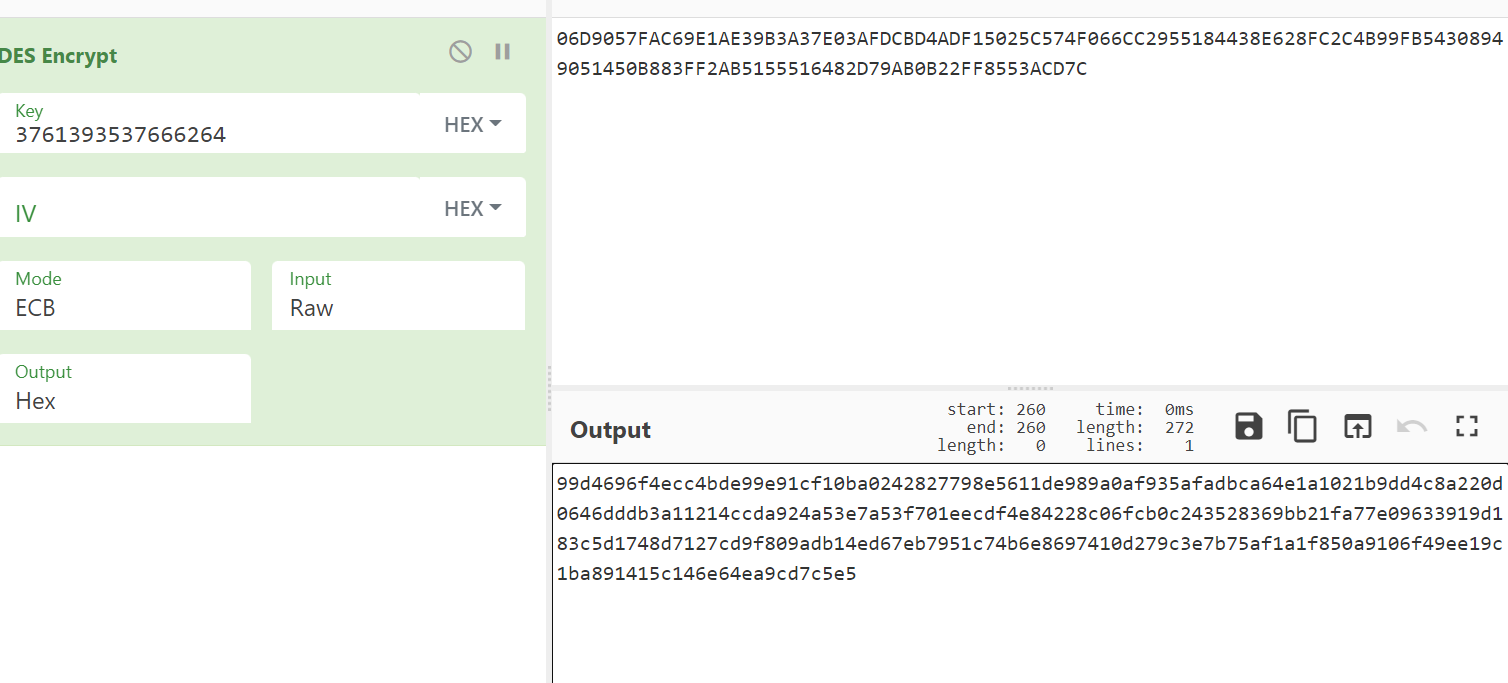

可以看到一模一样,那么我们就知道了这是个标准算法,python能够简单的实现,那么现在还有一个问题就是key和b是哪来的,向上追溯可以发现是js中自带的
var a = '7a957fbd';
var b = '06D9057FAC69E1AE39B3A37E03AFDCBD4ADF15025C574F066CC2955184438E628FC2C4B99FB54308949051450B883FF2AB5155516482D79AB0B22FF8553ACD7C';
over,可以开始写程序了
第一次访问随便找一个uuid的url得到js=>
第二次携带cookie访问url得到我们要的html数据=>
通过详细信息的a标签中的链接爬取所有的详细信息=>
通过下一页的a标签中的链接访问下一页的url=>
一直循环直到页空的尽头
这里我选择了,直接调用js代码,也可以写正则匹配拿到message和key,并且补环境也用了之前的代码,跑一遍js还是缺环境了,安装一个CryptoJS
npm install crypto-js
然后导入,发现结果
var CryptoJS = require("crypto-js");
......
console.log(ck)

那么现在就可以写我们的脚本进行爬取了,成功得到cookie的值,期间需要加入一个getcookie函数,和使用execjs这个之前都讲过这里不再赘述了,落地加载js(其实不落地也行)
response = requests.get('https://****.***.***/15022E858978-A7C0-4D99-A602-967A31FB4828.html', headers=headers, cookies=cookies)
pattern = re.compile("<script>(.*)</script>",re.S)
jscode = pattern.findall(response.text)[0]
with open("./MyProxy.js", "r") as f:
envcode = f.read()
getcookie="function getcookie(){return document.cookie;}"
allcode = envcode + jscode+"\n"+getcookie;
with open("./allcode.js", "w") as f:
f.write(allcode)
ctx = execjs.compile(allcode)
spvrscode = ctx.call("getcookie")
print(spvrscode)

但是要注意,这个网址是spvrscode与sessionid一一对应的,所以要定义类来进行统一会话,最终代码如下
class spider:
def __init__(self):
self.session = requests.session()
def getdata(self, url):
headers = {
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
response = self.session.get(url, headers=headers)
html = response.text
if "******" not in response.text:
pattern = re.compile("<script>(.*)</script>",re.S)
jscode = pattern.findall(response.text)[0]
with open("./MyProxy.js", "r") as f:
envcode = f.read()
getcookie = "function getcookie(){return b;}"
allcode = envcode + jscode + "\n" + getcookie;
with open("./allcode.js", "w") as f:
f.write(allcode)
ctx = execjs.compile(allcode)
spvrscode = ctx.call("getcookie")
requests.utils.add_dict_to_cookiejar(self.session.cookies, {"spvrscode": spvrscode})
response = self.session.get('***********', headers=headers)
html = response.text
print(self.session.cookies.values())
if __name__ == '__main__':
s=spider();
s.getdata("https://***********")
得到了html