word2vec原理
word2vec是将词转化为向量的一个强大的工具,它是google在2013年推出的,其特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系。
word2vec一般分为CBOW与Skip-Gram两种模型,下面会分别对两种模型进行具体的介绍。
本文参考的内容会在文章的下方列出。
一. CBOW
CBOW模型是根据中心词周围的n个词来预测中心词。
CBOW的模型结构图如下:

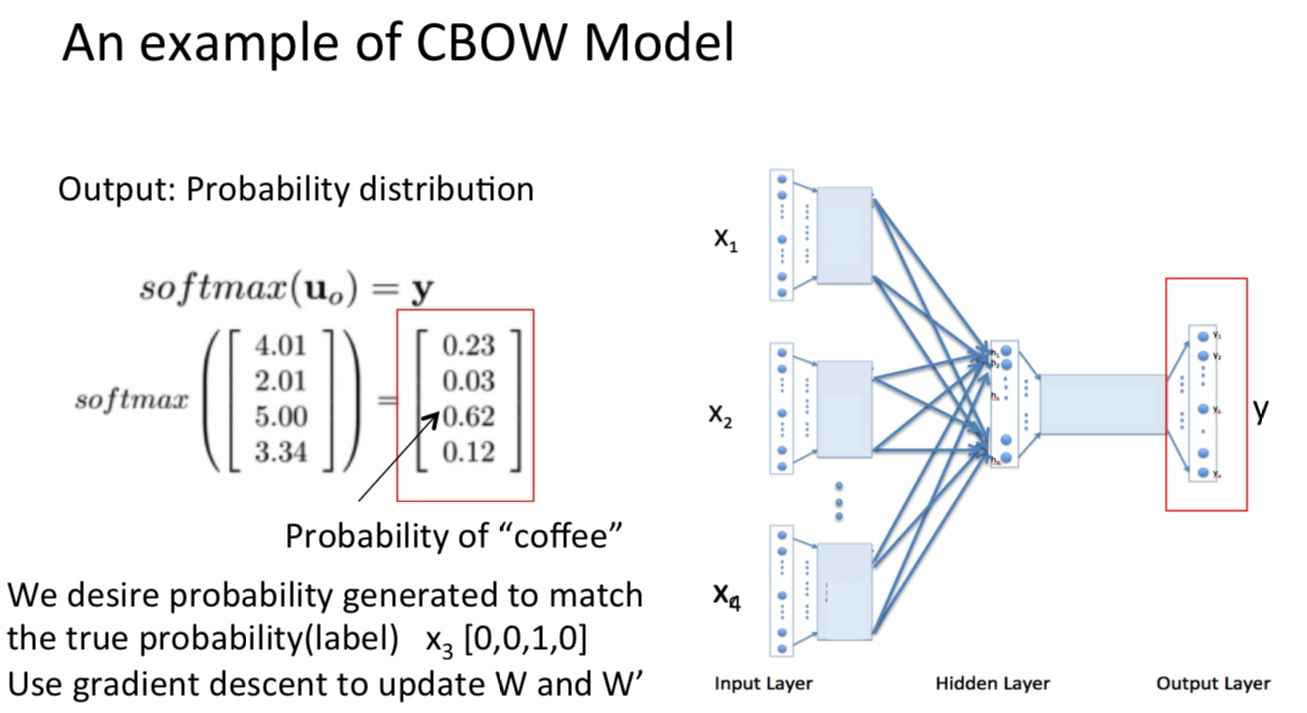
模型由输入层、隐藏层和输出层组成。
模型最终要求出的其实是输入层和隐藏层之间的权重矩阵,下面会详细说明模型的具体步骤:
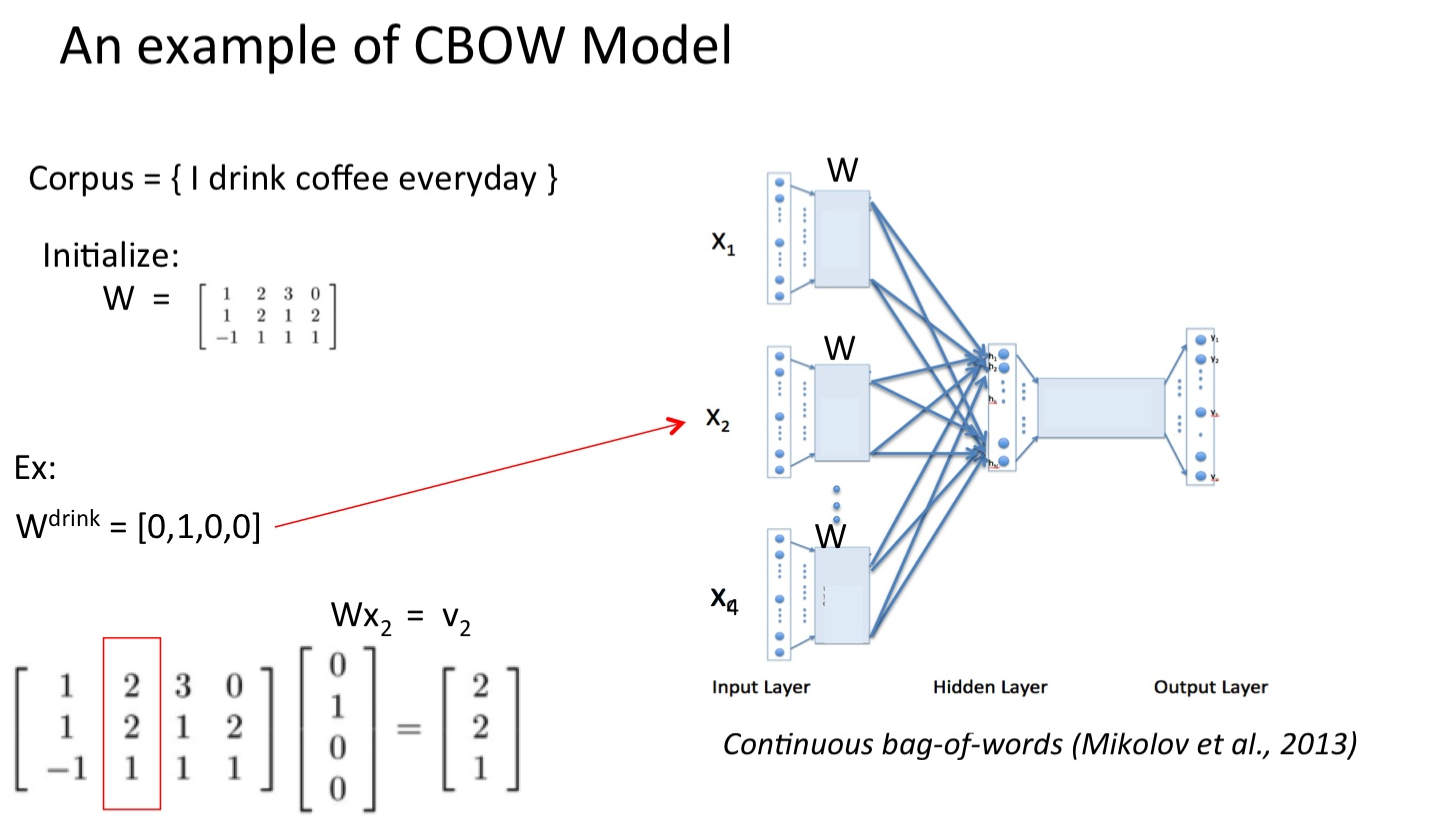
这里假设上下文的单词个数为N,单词向量空间dim为M,也就是词典的大小
- 输入时上下文的one-hot向量
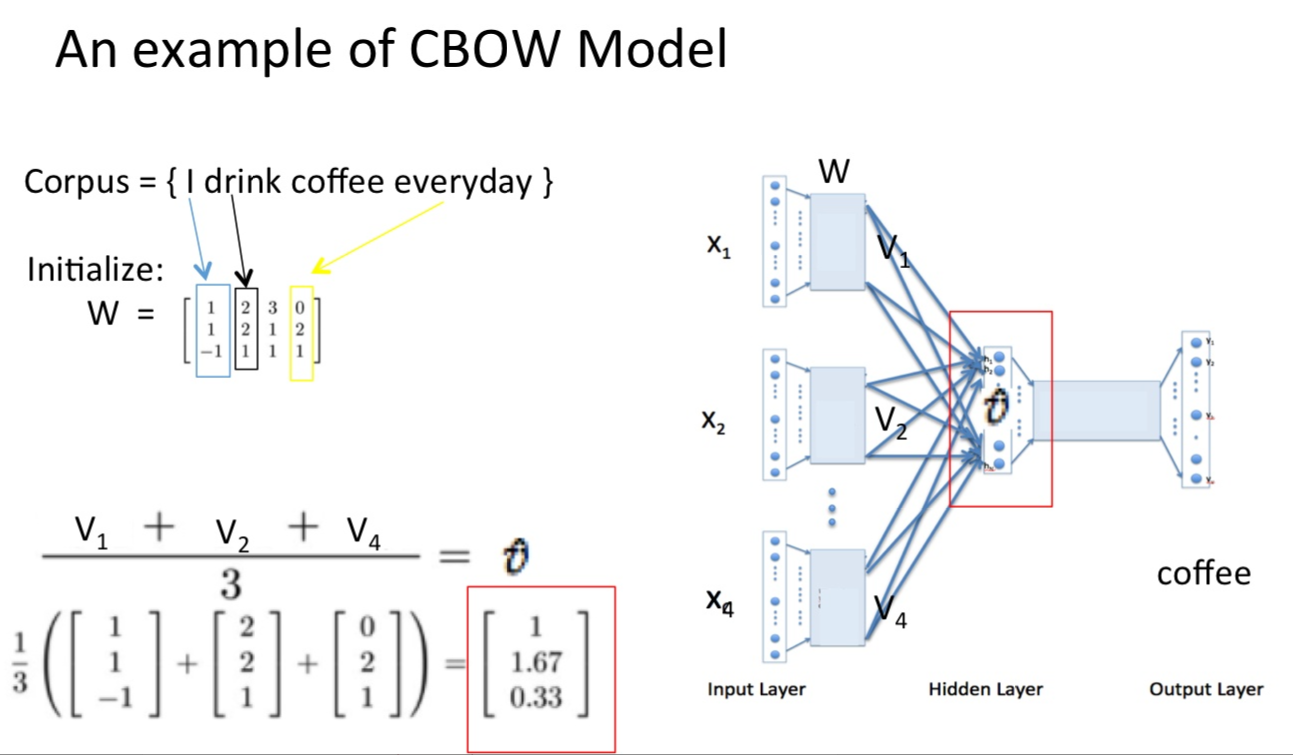
- 输入层和隐藏层之间的权重为W(M*N,N为自己设定的个数)对权重初始化,所得的向量进行相加求平均操作,size为1*N
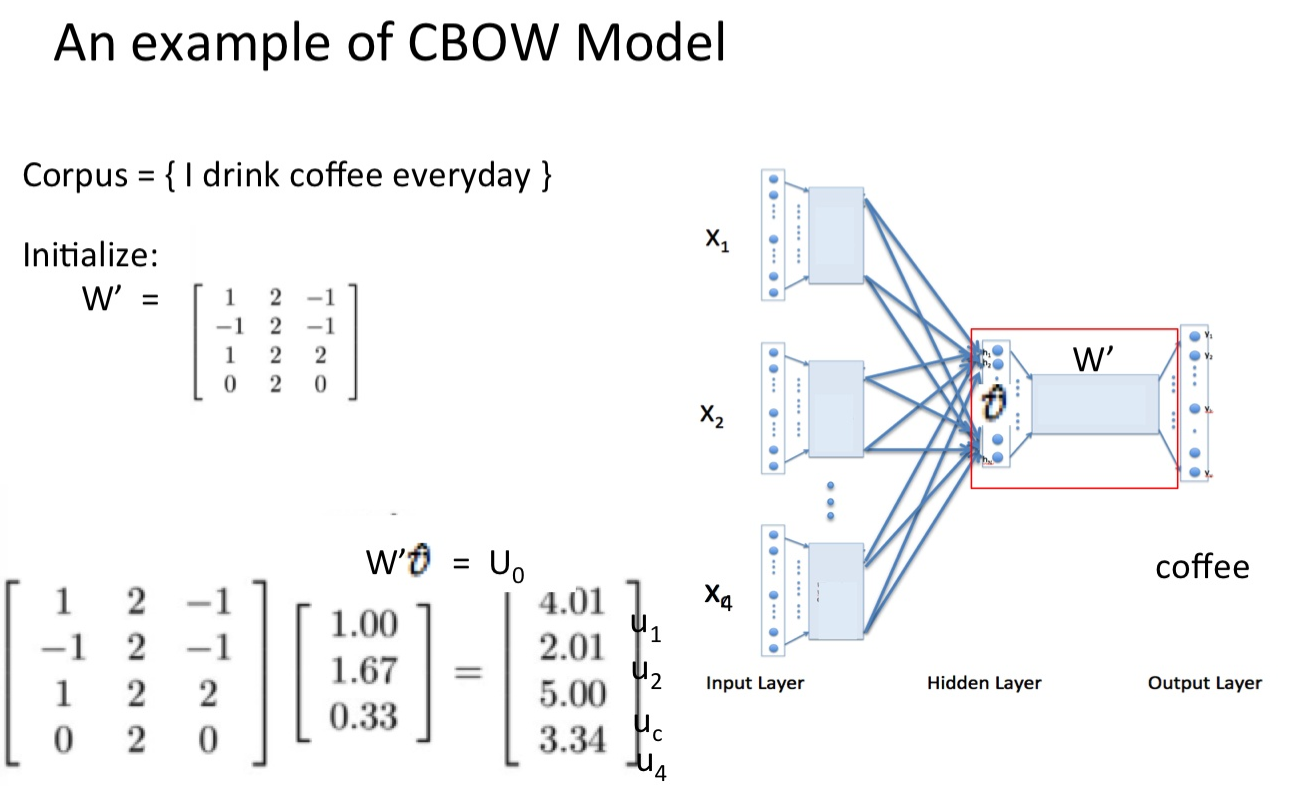
- 隐藏层和输出层的权重为W‘(N*M),2得到的结果乗W‘,得到1*M的向量
- 得到的向量与true label的one-hot做比较,误差越小越好
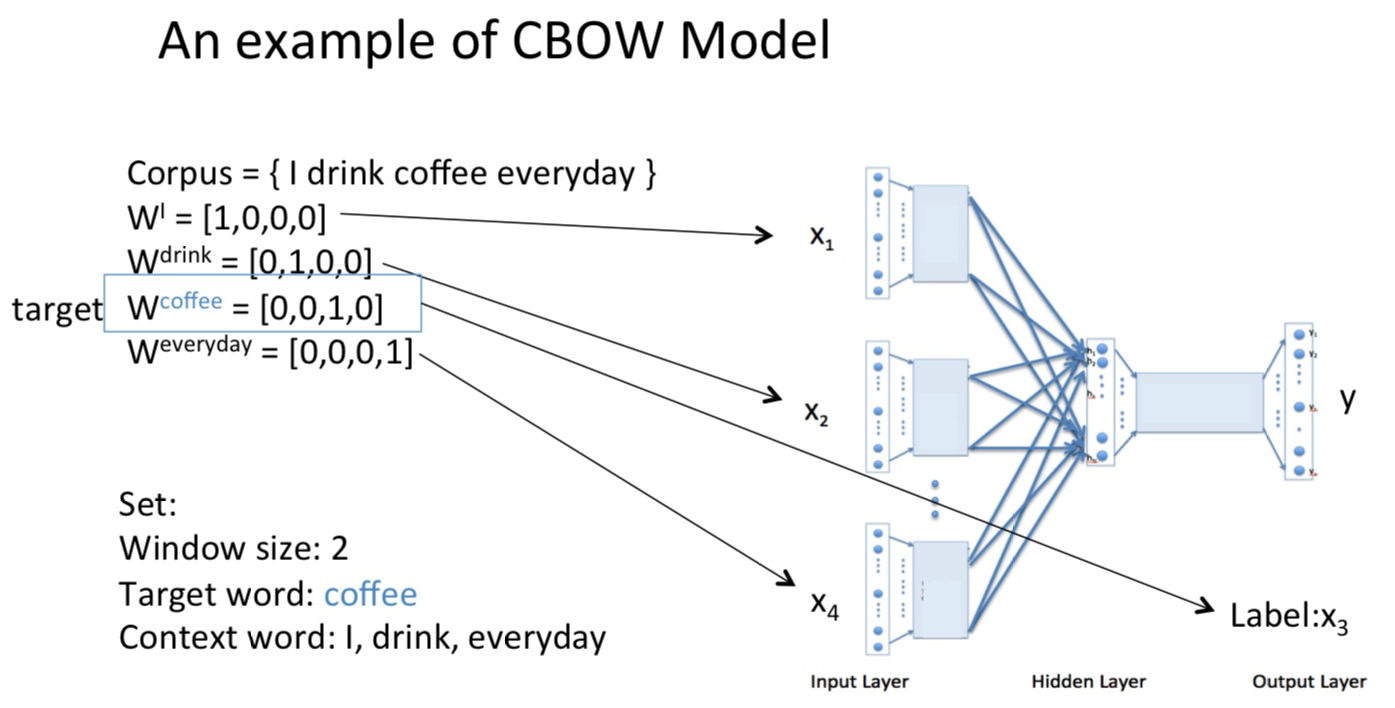
流程举例:
现在有一句话:I drink coffee everyday
要预测coffee这个词的词向量,我们选取的窗口大小为2,也就是根据“I”,“drink”,“everyday”来预测预测一个单词,并且希望最终的结果是“coffee”
二. Skip-Gram
Skip-Gram模型是根据当前词预测上下文。
Skip-Gram的模型结构如下图所示:
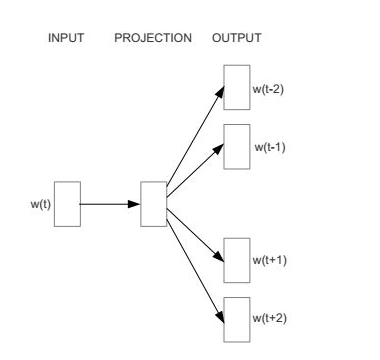
该结构和CBOW模型相反,但是同样都是输入层隐藏层和输出层。
输入层:单词的one-hot向量
隐藏层:对隐藏层权重矩阵的学习,首先初始化权重矩阵,权重矩阵通过梯度下降法来更新。
输出层:实际上是一个概率分布(即一堆浮点数的组合,而不是一个one-hot向量)
总结
以上内容对CBOW和Skip-Grap两个模型的原理进行了介绍,之后会从word2vec的两种改进方法进行讲述,一种是基于Hierarchical Softmax的,另一种是基于Negative Sampling的。
参考内容:
https://www.zhihu.com/question/44832436

 浙公网安备 33010602011771号
浙公网安备 33010602011771号