Zookeeper集群搭建
Zookeeper集群搭建
由于公司缓存方案改进,准备采用codis集群作为主要的缓存解决方案(codis:国内豌豆荚开发的redis集群解决方案,已开源,github地址:https://github.com/CodisLabs/codis),codis集群依赖于zookeeper集群,本文介绍zookeeper集群的实现。
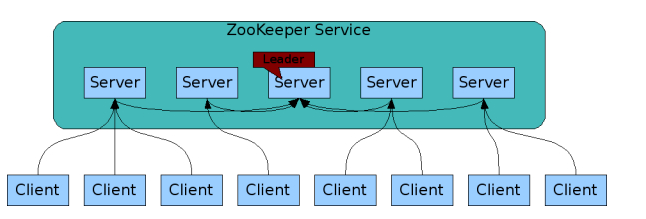
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
- 最终一致性:client不论连接到那个Server,展示给它的都是同一个视图。
- 可靠性:具有简单、健壮、良好的性能、如果消息m被到一台服务器接收,那么消息m将被所有服务器接收。
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
- 原子性:更新只能成功或者失败,没有中间状态。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
1、在zookeeper的集群中,各个节点共有下面3种角色和4种状态:
角色:leader,follower,observer
状态:leading,following,observing,looking
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议(ZooKeeper Atomic Broadcast protocol)。Zab协议有两种模式,它们分别是恢复模式(Recovery选主)和广播模式(Broadcast同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有4种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻。
LEADING:当前Server即为选举出来的leader。
FOLLOWING:leader已经选举出来,当前Server与之同步。
OBSERVING:observer的行为在大多数情况下与follower完全一致,但是他们不参加选举和投票,而仅仅接受(observing)选举和投票的结果。
- Zookeeper节点部署越多,服务的可靠性越高,建议部署奇数个节点,因为zookeeper集群是以宕机个数过半才会让整个集群宕机的。
- 需要给每个zookeeper 1G左右的内存,如果可能的话,最好有独立的磁盘,因为独立磁盘可以确保zookeeper是高性能的。如果你的集群负载很重,不要把zookeeper和RegionServer运行在同一台机器上面,就像DataNodes和TaskTrackers一样。
| 主机名 | 系统 | IP地址 |
| linux-node1 | CentOS 6.8 版 | 192.168.1.148 |
| linux-node2 | CentOS 6.8 版 | 192.168.1.149 |
| linux-node2 | CentOS 6.8 版 | 192.168.1.150 |
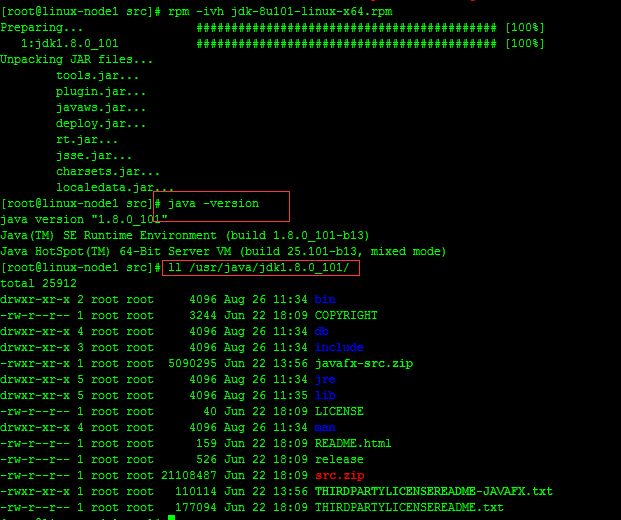
Zookeeper运行需要java环境,需要安装jdk,注:每台服务器上面都需要安装zookeeper、jdk,建议本地下载好需要的安装包然后上传到服务器上面,服务器上面下载速度太慢。
JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
rpm -ivh jdk-8u101-linux-x64.rpm
Zookeeper链接:http://zookeeper.apache.org/
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz -P /usr/local/src/
tar zxvf zookeeper-3.4.8.tar.gz -C /opt
cd /opt && mv zookeeper-3.4.8 zookeeper
cd动物园管理员
cp conf/zoo_sample.cfg conf/zoo.cfg
#把zookeeper加入到环境变量
echo -e "# append zk_env\nexport PATH=$PATH:/opt/zookeeper/bin" >> /etc/profile
注意:搭建zookeeper集群时,一定要先停止已经启动的zookeeper节点。
#修改过后的配置文件zoo.cfg,如下:
egrep -v "^#|^$" zoo.cfg
滴答时间=2000
初始化限制=10
同步限制=5
dataLogDir=/opt/zookeeper/logs
dataDir=/opt/zookeeper/数据
客户端端口=2181
autopurge.snapRetainCount=500
autopurge.purgeInterval=24
服务器.1 = 192.168.1.148:2888:3888
server.2 = 192.168.1.149:2888:3888
server.3 = 192.168.1.150:2888:3888
#创建相关目录,三台节点都需要
mkdir -p /opt/zookeeper/{日志,数据}
#其余zookeeper节点安装完成之后,同步配置文件zoo.cfg。
tickTime这个时间是作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳。
initLimit这个配置项是用来配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20秒。
syncLimit这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
dataDir顾名思义就是zookeeper保存数据的目录,默认情况下zookeeper将写数据的日志文件也保存在这个目录里;
clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
server.A=B:C:D中的A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。
这个文件里面有一个数据就是A的值(该A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路径中创建myid文件。
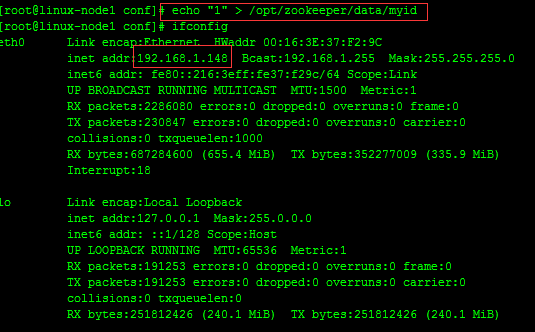
#在192.168.1.148服务器上面创建myid文件,并设置值为1,同时与zoo.cfg文件里面的server.1保持一致,如下
echo "1" > /opt/zookeeper/data/myid
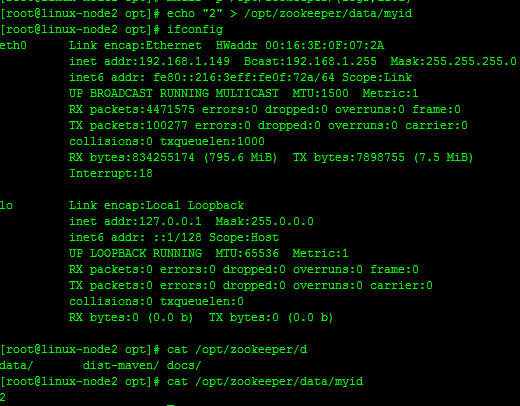
#在192.168.1.149服务器上面创建myid文件,并设置值为1,同时与zoo.cfg文件里面的server.2保持一致,如下
echo "2" > /opt/zookeeper/data/myid
#在192.168.1.150服务器上面创建myid文件,并设置值为1,同时与zoo.cfg文件里面的server.3保持一致,如下
echo "3" > /opt/zookeeper/data/myid
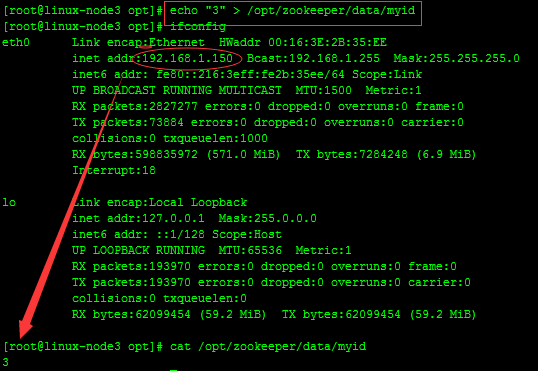
到此,相关配置已完成
#linux-node1、linux-node2、linux-node3
/opt/zookeeper/bin/zkServer.sh 启动
注意:报错排查

Zookeeper节点启动不了可能原因:zoo.cfg配置文件有误、iptables没关。
#linux-node1
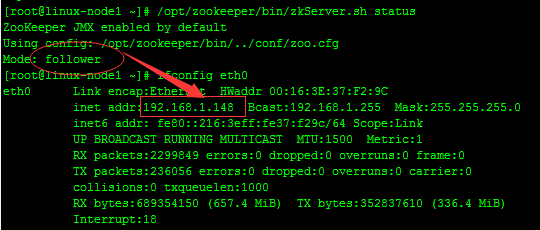
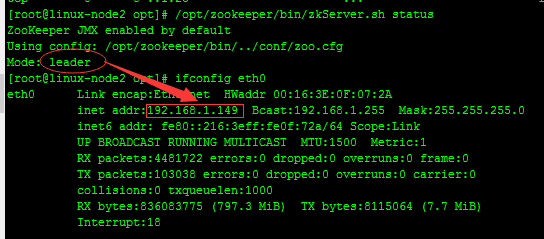
#linux-node2
#linux-node3
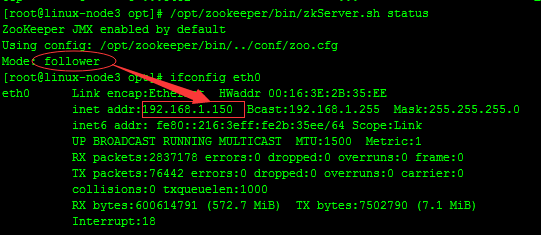
#从上面可以看出,linux-node1,linux-node3两台服务器zookeeper的状态是follow模式,linux-node2这台服务器zookeeper的状态是leader模式。
Zookeeper集群搭建完毕之后,可以通过客户端脚本连接到zookeeper集群上面,对客户端来说,zookeeper集群是一个整体,连接到zookeeper集群实际上感觉在独享整个集群的服务。
#在linux-node1测试
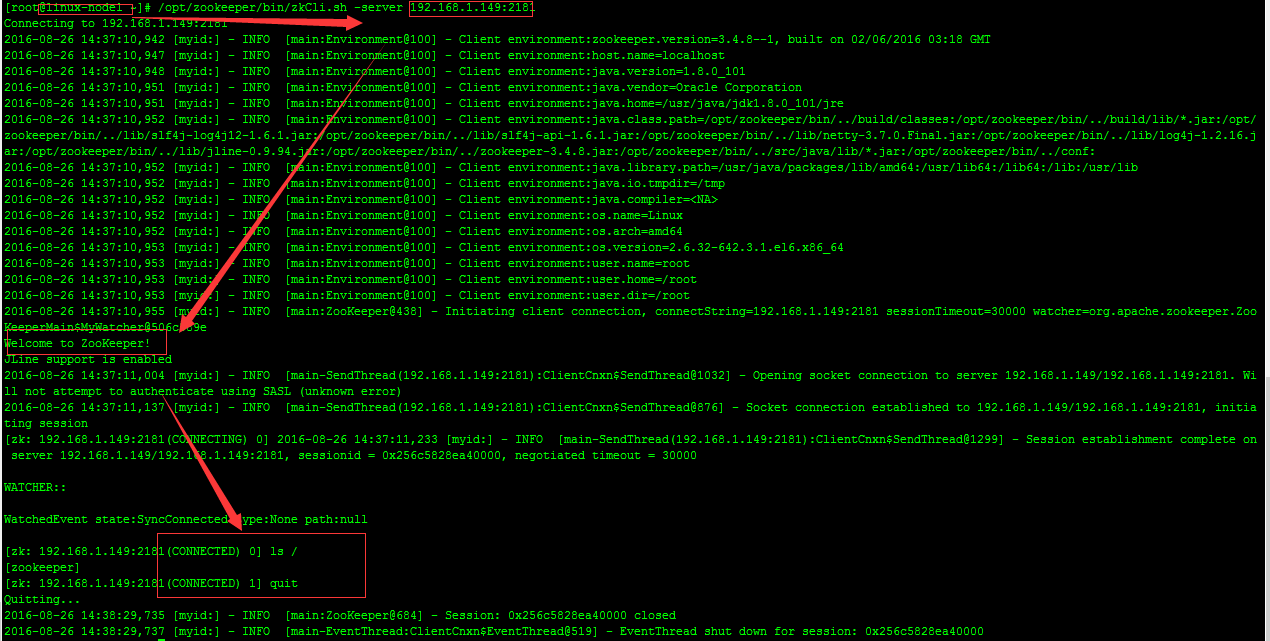
通过上图可以看出整个zookeeper集群已经搭建并测试完成。
#Zookeeper原理:
http://blog.csdn.net/wuliu_forever/article/details/52053557
http://www.cnblogs.com/luxiaoxun/p/4887452.html
本文转载地址:https://www.linuxprobe.com/zookeeper-cluster-deploy.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号