Java爬虫工具Jsoup使用Demo
导入依赖
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.12</version>
</dependency>
</dependencies>
简单入门
工具方法,获取解析后的html文本
/**
* 输入一个网址返回这个网址的html文本字符串
*/
public static String getHtml(String str) {
CloseableHttpResponse response = null; // 执行get请求
String content = null;
try {
CloseableHttpClient httpclient = HttpClients.createDefault(); // 创建httpclient实例
HttpGet httpget = new HttpGet(str); // 创建httpget实例
response = httpclient.execute(httpget);
HttpEntity entity = response.getEntity(); // 获取返回实体
content = EntityUtils.toString(entity, "utf-8");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
response.close(); // 关闭流和释放系统资源
} catch (IOException e) {
e.printStackTrace();
}
}
return content;
}
具体使用
public static void main(String[] args) {
//获取博客园首页html
String html = getHtml("https://www.cnblogs.com/");
Document doc = Jsoup.parse(html);
//使用选择器语法查询id为post_list下 class为post-item-text下所有a标签的内容
Elements select = doc.select("#post_list .post-item .post-item-body .post-item-text a");
for (Element element : select) {
String text = element.text().trim();
if (StringUtils.isNotBlank(text)) {
//获取a标签里的文本
System.out.println("博客标题:" + text);
}
}
}
控制台输出
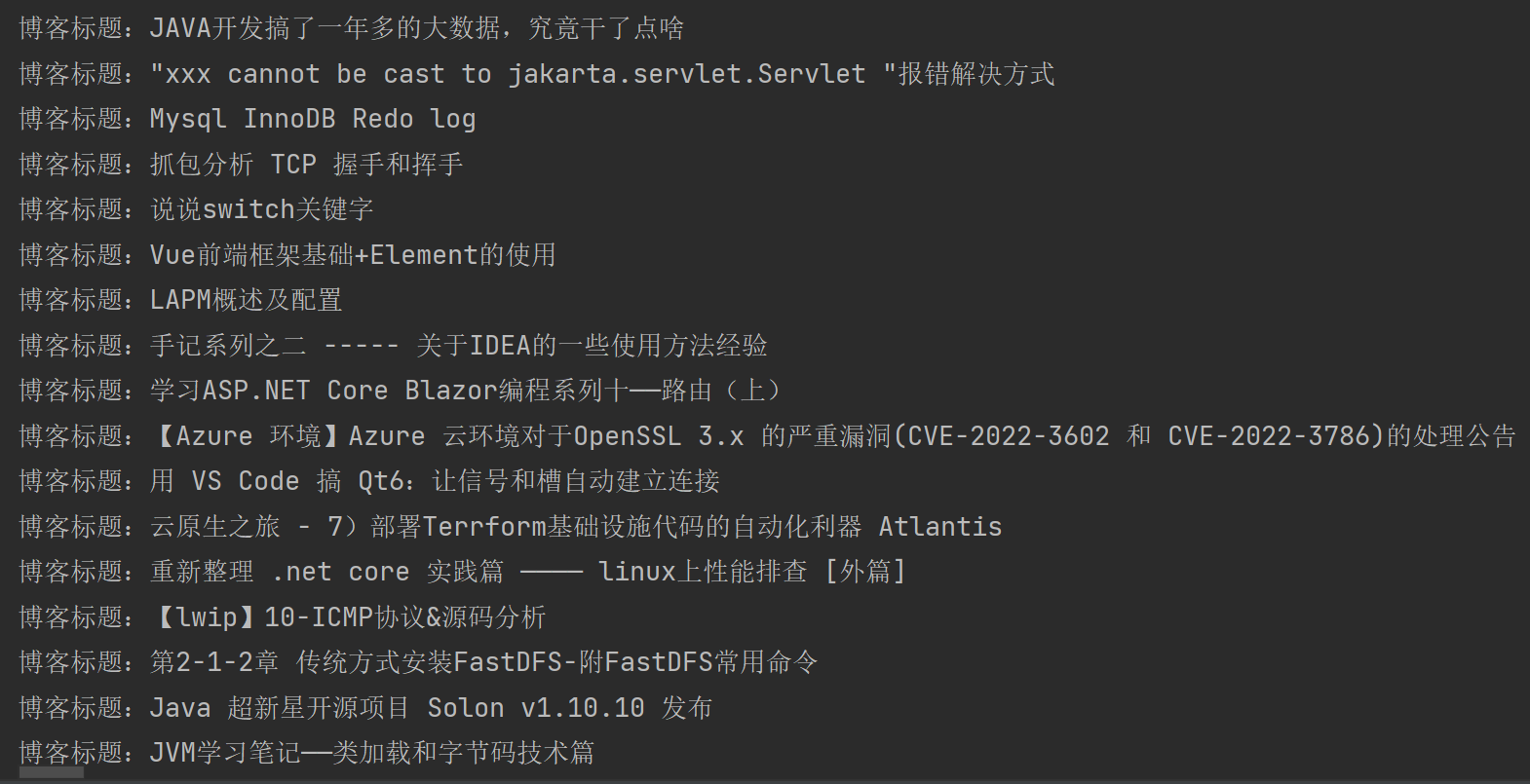
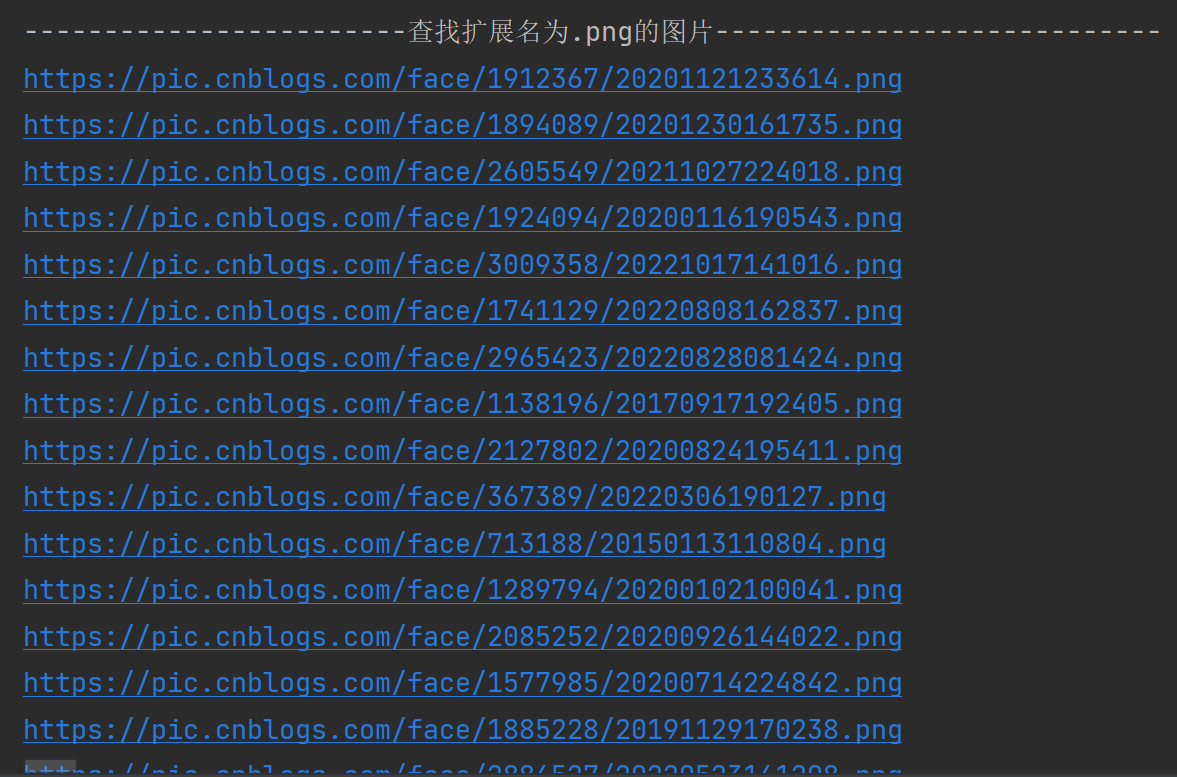
获取所有扩展名为.png并且带有src属性的图片DOM节点
String html = getHtml("https://www.cnblogs.com/");
Document doc = Jsoup.parse(html);
System.out.println("------------------------查找扩展名为.png的图片----------------------------");
Elements imgElements = doc.select("img[src$=.png]"); // 查找扩展名为.png的图片DOM节点
for (Element e : imgElements) {
System.out.println(e.attr("src"));
}
控制台输出
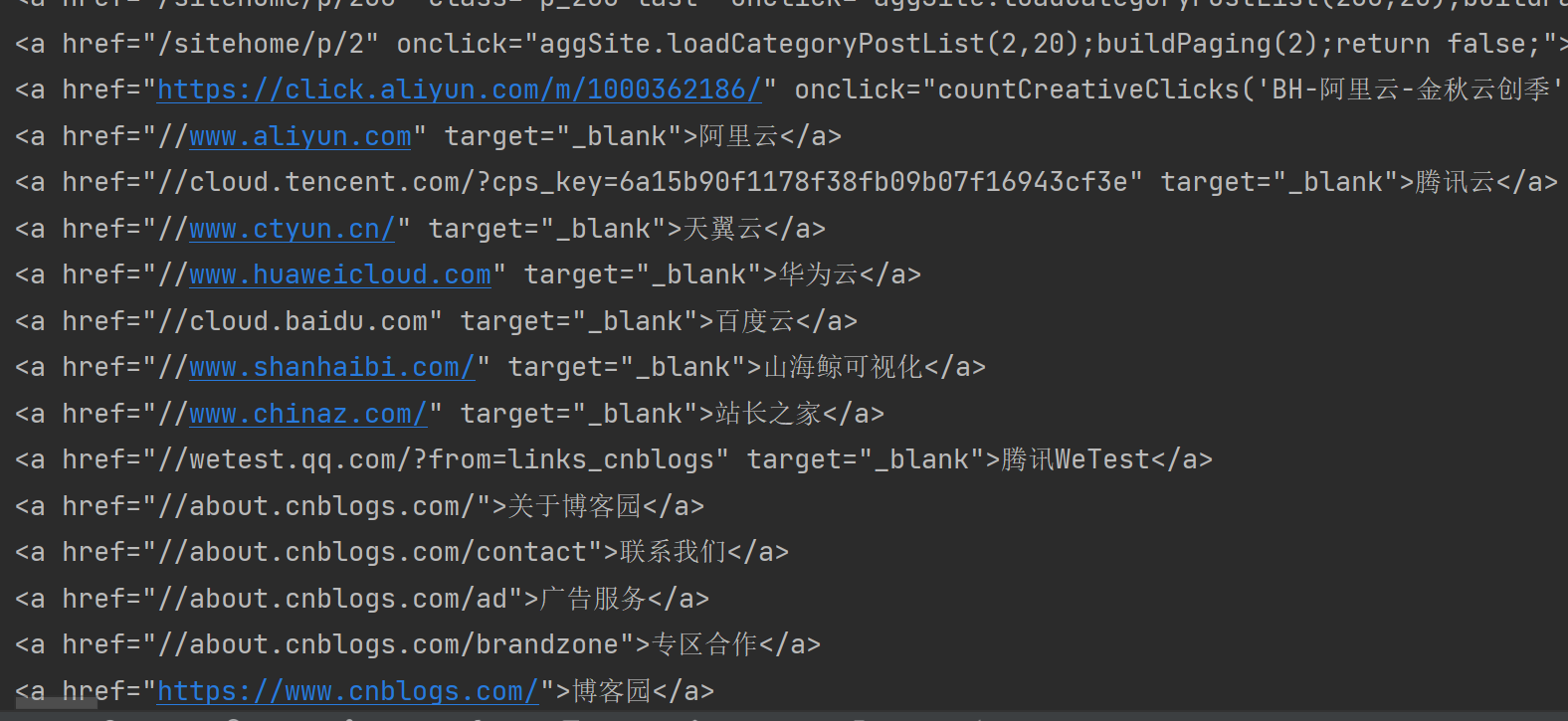
获取所有带有href属性的a元素
String html = getHtml("https://www.cnblogs.com/");
Document doc = Jsoup.parse(html);
System.out.println("--------------------带有href属性的a元素--------------------------------");
Elements hrefElements = doc.select("a[href]"); // 带有href属性的a元素
for (Element e : hrefElements) {
System.out.println(e.toString());
}
控制台输出


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构