爬虫入门之爬取网页ppt成品及制作思路随笔
python爬虫入门实现爬取ppt随笔
先上源代码!(使用方法及成品展示在最后哦,请耐心看完)
from selenium import webdriver
import requests
from selenium.webdriver.common.by import By
import os,fitz,pprint
username = ''
password = ''
fpath = 'D:/ppt/高数ppt'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
baseurl = input('输入链接:')
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get(baseurl)
un = driver.find_element(By.CSS_SELECTOR,'#phone')
pwd = driver.find_element(By.CSS_SELECTOR,'#pwd')
lgin = driver.find_element(By.CSS_SELECTOR,'#loginBtn')
un.send_keys(username)
pwd.send_keys(password)
lgin.click()
def eachurl(locurl):
driver.execute_script('window.open("'+locurl+'")')
handles = driver.window_handles
driver.switch_to.window(handles[-1])
fname = driver.find_element(By.CSS_SELECTOR, '#mainid h1').text + '.pdf'
driver.switch_to.frame('iframe')
try:
frame = driver.find_element(By.TAG_NAME, 'iframe')
driver.switch_to.frame(frame)
except:
pass
try:
driver.switch_to.frame('panView')
except:
pass
elems = driver.find_elements(By.CSS_SELECTOR, 'img[src*="http"]')
urls = []
for elem in elems:
urls.append(elem.get_attribute('src'))
pprint.pprint(urls)
if len(urls)==0:
return
os.makedirs(fpath, exist_ok=1)
os.chdir(fpath)
doc = fitz.open()
for i in range(len(urls)):
r = requests.get(urls[i], headers=headers)
with open(str('tmp') + '.png', 'wb') as f:
f.write(r.content)
imgdoc = fitz.open(f)
pdfbytes = imgdoc.convert_to_pdf()
pdf_name = str(i) + '.pdf'
imgpdf = fitz.open(pdf_name, pdfbytes)
doc.insert_pdf(imgpdf)
doc.save(fname)
os.remove(str('tmp') + '.png')
doc.close()
driver.close()
urls.clear()
locelems = driver.find_elements(By.CSS_SELECTOR,'.leveltwo .clearfix a')
def operateurls(locelems):
for locelem in locelems:
newurl = locelem.get_attribute('href')
print(newurl)
eachurl(newurl)
handles = driver.window_handles
driver.switch_to.window(handles[0])
operateurls(locelems)
eachurl(baseurl)
driver.quit()
背景:
高数老师竟然不提前发ppt在qq群里!然而不预习听高数真的是一种煎熬,所以经过百般搜寻,在我们学校的资源平台上找到了高数ppt的资源。BUT!

如图所示,这个ppt被放在一个iframe框架里,并且没有下载的入口,而我并不想每次看ppt都要打开网页!于是我用浏览器自带的开发工具检查页面源代码,发现他放的都是ppt内容的png格式文件!
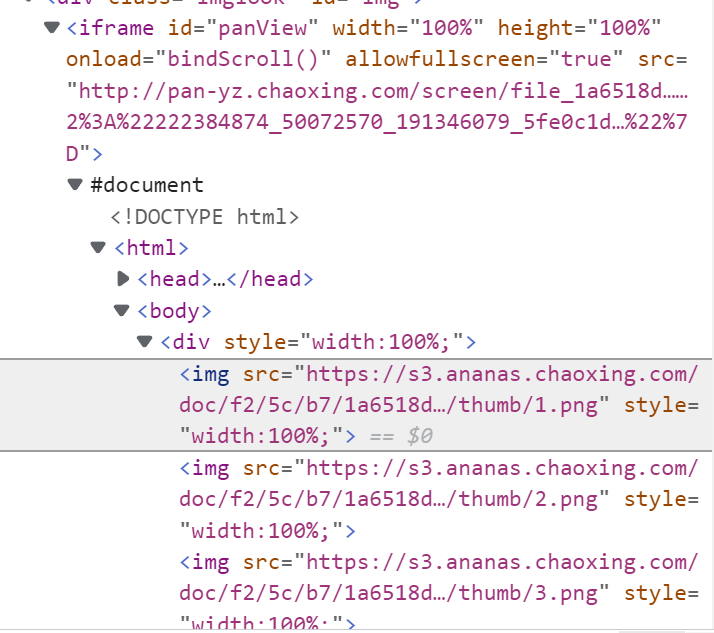
不过经过万能的bing搜索,发现python有fitz库,可以将png图片转化为pdf格式,这太方便啦!
所以理论上我们可以通过简单的爬虫来实现爬ppt这个功能,理论可行,实践开始!
爬取单个页面实现思路
导入如下模块:
from selenium import webdriver#自动化操纵浏览器
from selenium.webdriver.common.by import By#路径选择器会用到
import requests#用于下载图片
import os#用于设定文件存放路径
import fitz#将png转化为pdf
import pprint#为了打印出来漂亮,输出哪些url被下载了
我们先得设置一下headers,避免网站把我们当作自动化机器人
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
我们现在创建一个webdriver对象,我这里用的是火狐
#实例化出来webdriver对象
driver = webdriver.Firefox()
#设置最大等待时间,就是要是浏览器没反应最多10s就停止了
driver.implicitly_wait(10)
#进入url
driver.get(baseurl)
我们首先需要用webdriver进入该节ppt的网页查看链接,但是我们用自动化方式操作浏览器时先要进行登录,界面如下:
我们用find_element方法找到输入口和登录按钮,并且将设置好的用户名和密码用send_keys方法输进去,并且用click模拟点击登录按钮
un = driver.find_element(By.CSS_SELECTOR,'#phone')
pwd = driver.find_element(By.CSS_SELECTOR,'#pwd')
lgin = driver.find_element(By.CSS_SELECTOR,'#loginBtn')
un.send_keys(username)
pwd.send_keys(password)
lgin.click()
现在我们就进入了有该节ppt的网站了
由于ppt在iframe框架中,且经过检查有的不止一层,最多两层,所以用try-except结构来进入ppt所在的最里层
driver.switch_to.frame('iframe')
try:
frame = driver.find_element(By.TAG_NAME, 'iframe')
driver.switch_to.frame(frame)
except:
pass
try:
driver.switch_to.frame('panView')
except:
pass
再找到存放png的所有网址存起来,并将含有链接的标签存起来,再用get_attribute方法获取src里的链接放进url中
elems = driver.find_elements(By.CSS_SELECTOR, 'img[src*="http"]')
urls = []
for elem in elems:
urls.append(elem.get_attribute('src'))
用fitz库转换png并且把转换的同一节pdf连一块,文件取名从网页的标题里可以找到
fname = driver.find_element(By.CSS_SELECTOR, '#mainid h1').text + '.pdf'
#fpath是保存pdf的路径是自己设置的
os.makedirs(fpath, exist_ok=1)
os.chdir(fpath)
doc = fitz.open()
for i in range(len(urls)):
#用request方法获取url,再用二进制的方式将url里的图片内容写入临时文件
r = requests.get(urls[i], headers=headers)
with open(str('tmp') + '.png', 'wb') as f:
f.write(r.content)
imgdoc = fitz.open(f)
#转成pdf
pdfbytes = imgdoc.convert_to_pdf()
pdf_name = str(i) + '.pdf'
imgpdf = fitz.open(pdf_name, pdfbytes)
#插入pdf
doc.insert_pdf(imgpdf)
doc.save(fname)
#将进行中转的临时文件删除
os.remove(str('tmp') + '.png')
doc.close()
#再关闭当前页面
driver。close()
爬取多个页面思路
我们发现高数的ppt在一个资源列表里,

经过检查浏览器元素,找到了列表的元素里的href链接

于是我们就可以将单个页面的思路进行扩充,即每次爬完列表中的一个链接,用seenium中操作窗口的手柄window_handles的switch_to.window()返回上一个窗口,继续进入列表的下一个链接,调用爬取单个页面的函数eachurl()爬取下一节课的ppt
#找到该页面列表中所有的url,再通过爬取单个页面的方式处理每个列表中的url
locelems = driver.find_elements(By.CSS_SELECTOR,'.leveltwo .clearfix a')
def operateurls(locelems):
for locelem in locelems:
newurl = locelem.get_attribute('href')
print(newurl)
eachurl(newurl)
handles = driver.window_handles
driver.switch_to.window(handles[0])
使用方法及成品展示
我们先要设置源码里的username和password,注意是超星课堂的,一般username是手机号
然后设置你要保存ppt的路径,源码里是d盘ppt里的高数ppt,可以自己改
我们只要将有章节列表的页面的网址完全复制下来,然后运行我们的python程序,按照提示粘贴刚刚复制的链接就可以啦


