KMP算法与字符串匹配问题
3. KMP算法
3.1 定义
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
下面为KMP的算法流程假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的3.3.3节中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1。
很快,你也会意识到next 数组各值的含义:代表当前字符之前的字符串中,有多大长度的相同前缀后缀。例如如果next [j] = k,代表j 之前的字符串中有最大长度为k 的相同前缀后缀。
此也意味着在某个字符失配时,该字符对应的next 值会告诉你下一步匹配中,模式串应该跳到哪个位置(跳到next [j] 的位置)。如果next [j] 等于0或-1,则跳到模式串的开头字符,若next [j] = k 且 k > 0,代表下次匹配跳到j 之前的某个字符,而不是跳到开头,且具体跳过了k 个字符。
3.2 步骤
①寻找前缀后缀最长公共元素长度
对于P = p0 p1 ...pj-1 pj,寻找模式串P中长度最大且相等的前缀和后缀。如果存在p0 p1 ...pk-1 pk = pj- k pj-k+1...pj-1 pj,那么在包含pj的模式串中有最大长度为k+1的相同前缀后缀。举个例子,如果给定的模式串为“abab”,那么它的各个子串的前缀后缀的公共元素的最大长度如下表格所示:

比如对于字符串aba来说,它有长度为1的相同前缀后缀a;而对于字符串abab来说,它有长度为2的相同前缀后缀ab(相同前缀后缀的长度为k + 1,k + 1 = 2)。
②求next数组
next 数组考虑的是除当前字符外的最长相同前缀后缀,所以通过第①步骤求得各个前缀后缀的公共元素的最大长度后,只要稍作变形即可:将第①步骤中求得的值整体右移一位,然后初值赋为-1,如下表格所示:

比如对于aba来说,第3个字符a之前的字符串ab中有长度为0的相同前缀后缀,所以第3个字符a对应的next值为0;而对于abab来说,第4个字符b之前的字符串aba中有长度为1的相同前缀后缀a,所以第4个字符b对应的next值为1(相同前缀后缀的长度为k,k = 1)。
③根据next数组进行匹配
匹配失配,j = next [j],模式串向右移动的位数为:j - next[j]。换言之,当模式串的后缀pj-k pj-k+1, ..., pj-1 跟文本串si-k si-k+1, ..., si-1匹配成功,但pj 跟si匹配失败时,因为next[j] = k,相当于在不包含pj的模式串中有最大长度为k 的相同前缀后缀,即p0 p1 ...pk-1 = pj-k pj-k+1...pj-1,故令j = next[j],从而让模式串右移j - next[j] 位,使得模式串的前缀p0 p1, ..., pk-1对应着文本串 si-k si-k+1, ..., si-1,而后让pk 跟si 继续匹配。如下图所示:
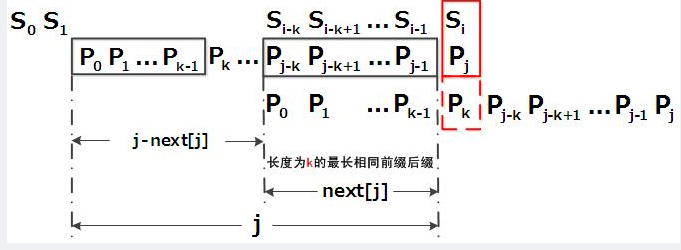
综上,KMP的next 数组相当于告诉我们:当模式串中的某个字符跟文本串中的某个字符匹配失配时,模式串下一步应该跳到哪个位置。如模式串中在j 处的字符跟文本串在i 处的字符匹配失配时,下一步用next [j] 处的字符继续跟文本串i 处的字符匹配,相当于模式串向右移动 j - next[j] 位。
3.3.2 基于《最大长度表》匹配
因为模式串中首尾可能会有重复的字符,故可得出下述结论:
失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
下面,咱们就结合之前的《最大长度表》和上述结论,进行字符串的匹配。如果给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:

1. 因为模式串中的字符A跟文本串中的字符B、B、C、空格一开始就不匹配,所以不必考虑结论,直接将模式串不断的右移一位即可,直到模式串中的字符A跟文本串的第5个字符A匹配成功:

2. 继续往后匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据《最大长度表》可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。

3. 模式串向右移动4位后,发现C处再度失配,因为此时已经匹配了2个字符(AB),且上一位字符B对应的最大长度值为0,所以向右移动:2 - 0 =2 位。

4. A与空格失配,向右移动1 位。

5. 继续比较,发现D与C 失配,故向右移动的位数为:已匹配的字符数6减去上一位字符B对应的最大长度2,即向右移动6 - 2 = 4 位。

6. 经历第5步后,发现匹配成功,过程结束。

子串的最大长度表如下:

子串的next数组如下:

重点:
- 根据最大长度表,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
- 而根据next 数组,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值
因此两个表向右移动的位数是一样的
通过上述匹配过程可以看出,问题的关键就是寻找模式串中最大长度的相同前缀和后缀,找到了模式串中每个字符之前的前缀和后缀公共部分的最大长度后,便可基于此匹配。而这个最大长度便正是next 数组要表达的含义。
import java.util.Arrays; /** * KMP算法 * @author * */ public class KMPAlgorithm { public static void main(String[] args) { String str1="ABADWDQDQDC"; String str2="DQDC"; int[]next=kmpNext(str2); int index=kmpSearch(str1, str2, next); System.out.println(index); } //获取到一个字符串(子串)的部分匹配值表 public static int[] kmpNext(String dest) { //创建一个next数组保存部分匹配值 int[] next=new int[dest.length()]; next[0]=0;//如果字符串长度为1,其部分匹配值就是0 for(int i=1,j=0;i<dest.length();i++) { while(j>0&&dest.charAt(i)!=dest.charAt(j)) { j=next[j-1]; } //当这个条件满足时,部分匹配值就是+1 if(dest.charAt(i)==dest.charAt(j)) { j++; } next[i]=j; } return next; } //KMP搜索算法 /** * * @param str1 源字符串 * @param str2 子串 * @param next 子串对应的部分匹配表 * @return 如果-1就代表没匹配到,否则返回第一个匹配的位置 */ public static int kmpSearch(String str1,String str2,int[] next) { //遍历 for(int i=0,j=0;i<str1.length();i++) { while(j > 0 && str1.charAt(i)!=str2.charAt(j)) { //j=next[j-1]; System.out.println(next[j-1]); // i=i-next[j-1]; // j=0; } if(str1.charAt(i)==str2.charAt(j)) { j++; } if(j==str2.length()) { //找到了 return i-j+1; } } return -1; } }
