数据库概念与实现(三)
关系数据库的结构
关系型数据库由表的集合组成,每个表有唯一的名字
一般来说,表中一行代表了一组值之间的一种联系,由于一个表就是这种联系的一种集合,表这个概念与数学上的关系这个概念也是密切相关的,在数学术语中,元组(tuple)只是一组值得序列(或列表),
在n个值之间的一种联系可以在数学上用关于这些值得一个n元祖(n-tuple)来表示。
关系模型中,关系用来代指表,而元组用来指代行,属性指代列
关系实例表示一个关系的特定实例,也就是所包含的一组特定的行
由于关系是元组的集合,所以元组在关系中出现的顺序是不重要的
对于关系中的属性,都会有一个取值的限制范围集合,称为该属性的域
我们要求对所有关系r而言,r的所有属性的域都应该是原子性的,即域中元素被看作是不可再分的单元,则域是原子的。
空值(NULL)是一个很特殊的值,表示值不存在或未知,一般不建议使用null值,因为这会给数据库的访问和更新带来很多麻烦,比如在Oracle中,任何数跟Null操作都是空,所以实际操作中应该尽量避免使用空值
数据库模式
数据库模式:数据库的逻辑设计
数据库实例:给定时刻数据库中数据的一个快照
关系的概念对应于程序设计语言的变量的概念,而关系模式的概念对应于程序设计语言中类型定义的概念
一般地,我们常说关系模式由属性序列和各属性对应的域组成
关系实例的概念对应程序设计语言中变量的值的概念,给定变量的值可能随时间发生变化,当关系被更新时,关系实例的内容也随时间发生了变化,相反的关系模式却是不常变化的
码
超码是一个或多个属性的集合,这些属性的组合可以在关系中唯一地标识一个元组,形式的描述是,设R为关系r模式中的属性集合,如果我们说R的一个子集K是r的一个超码,则限制了关系r中任意两个不同的元组
不会在K(超码)的所有属性上取的完全的相等
如果K是一个超码,那么K的任意超集也是超码,我们一般只探讨一种超码,它们的任意真子集都不能成为超码,这样的最小超码成为候选码
主码(primary key)代表数据库设计者选中的主要用来在一个关系中区分不同元组的候选码,注意:码是整个关系的一种性质,而不是单个元组的性质
主码应该选择那些值从不或极少改变的属性。
外码(foreign key) 一个关系模式如r1可能在它的属性中包含另一个关系模式r2的主码,这个属性在r1上被称作参照r2的外码,关系模式r1也称为外码依赖的参照关系,r2叫做外码的被参照关系
参照完整性约束:参照完整性约束要求在参照关系中任意元组在特定属性的取值必然等于被参照关系中某个元组在特定属性上的取值
关系查询语言
查询语言是用户用来从数据库中请求获取信息的语言
过程化语言: 用户指导系统对数据库执行一系列操作以计算出所需结果
非过程化语言:用户只需描述所需信息,而不用给出获取该信息的具体过程
两者优点 非过程化语言用户体验好,过程化语言运行速度快
关系代数是过程化的,而元祖关系演算和域关系演算是非过程化的
关系代数包括一个运算的集合,这些运算以一个关系或两个关系作为输入,产生一个新的关系作为结果
关系运算使用谓词逻辑来定义所需的结果,但不需给出获取结果的特定代数过程
所有的过程化关系查询语言都提供了一组运算,这些运算要么施加于单个关系上,要么施加于一对关系上,关系查询的结果本身也是关系,所以关系运算可施加到查询结果上。
连接运算可以通过把分别来自两个关系的元组合并成单个元组
自然连接:两个关系上的自然连接运算所匹配的元组在两个关系共有的所有属性上取值相同
笛卡尔积运算从两个关系中合并元组,但不同于连接运算的是,其结果包含来自两个关系元组的所有对,无论它们的属性是否匹配
因为关系是集合,所有我们可以在关系上施加集合运算 合并 相交 差运算
关系可以随新元组的插入,已有元组的删除或更改元组在特定属性上的值而更新,整个关系可被删除,新的关系可被创建
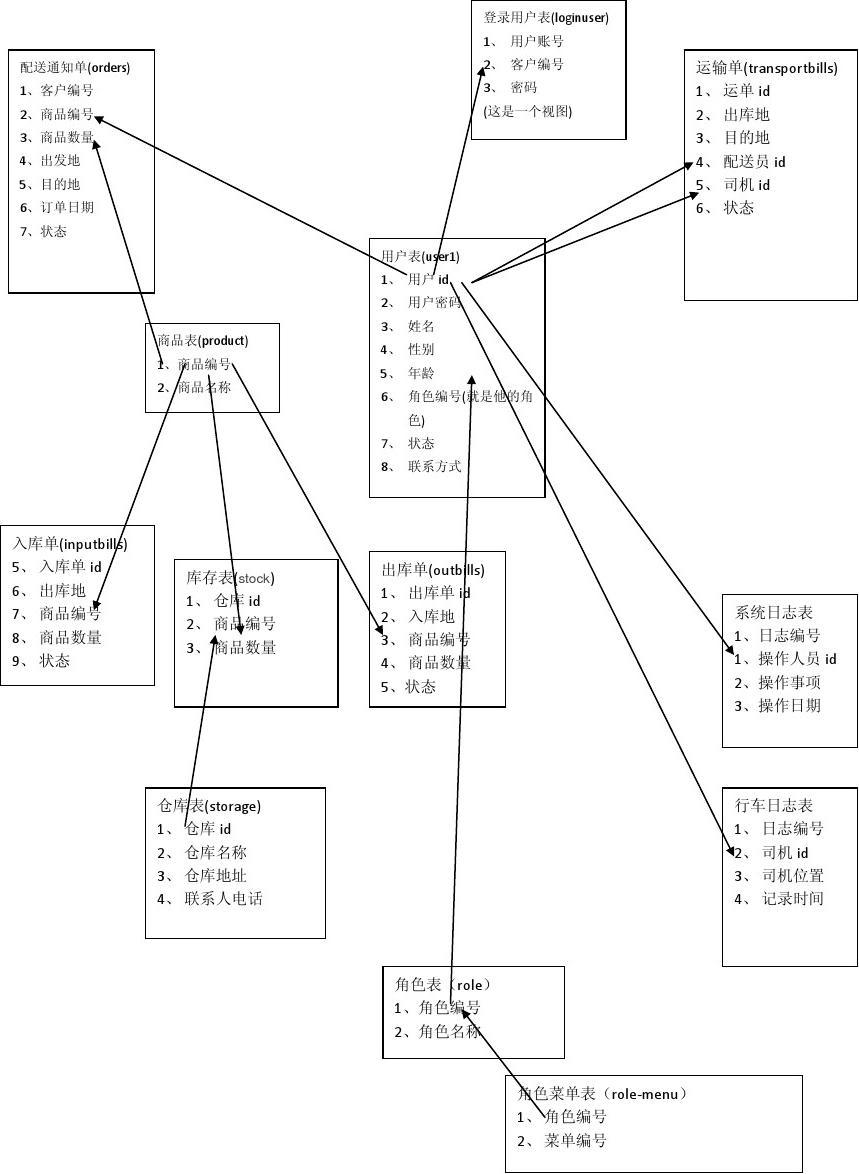
模式图
模式图是数据库中模式的图形化表示,它显示了数据库中的关系、关系的属性、主码和外码。