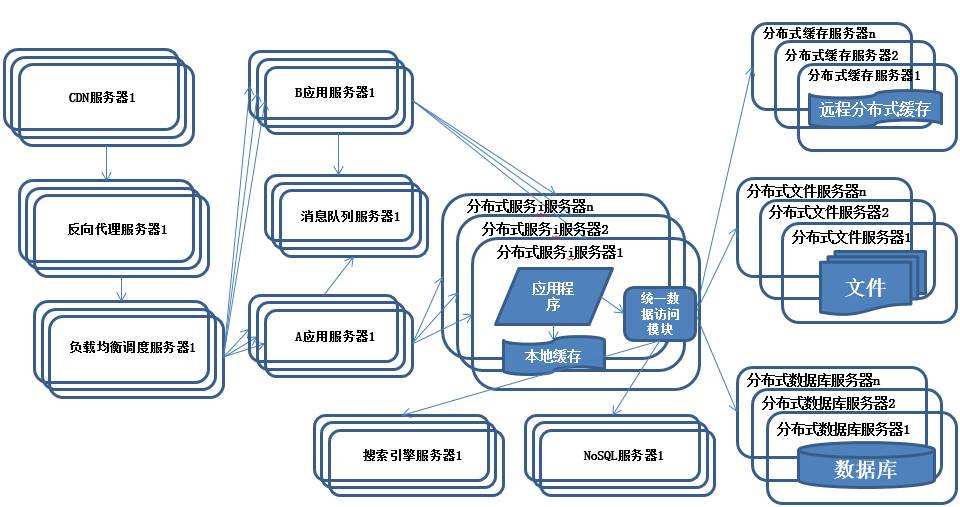
分布式架构的一致性
Paxos
Paxos算法是Leslie Lamport在1990年提出的一种基于消息传递的一致性算法。由于算法难以理解,起初并没有引起大家的重视,Lamport在1998年将论文重新发表到TOCS上,即便如此Paxos算法还是没有得到重视,2001年Lamport用可读性比较强的叙述性语言给出算法描述。
06年Google发布了三篇论文,其中在Chubby锁服务使用Paxos作为Chubby Cell中的一致性算法,Paxos的人气从此一路狂飙。
基于Paxos协议的数据同步与传统主备方式最大的区别在于:Paxos只需超过半数的副本在线且相互通信正常,就可以保证服务的持续可用,且数据不丢失。
Basic-Paxos
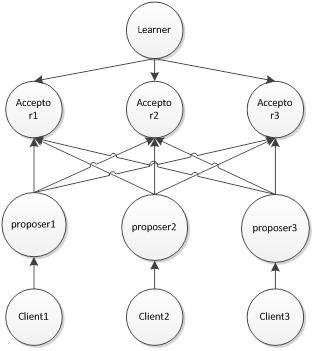
Basic-Paxos解决的问题:在一个分布式系统中,如何就一个提案达成一致。
需要借助两阶段提交实现:
Prepare阶段:
Proposer选择一个提案编号n并将prepare请求发送给 Acceptor。
Acceptor收到prepare消息后,如果提案的编号大于它已经回复的所有prepare消息,则Acceptor将自己上次接受的提案回复给Proposer,并承诺不再回复小于n的提案。
Accept阶段:
当一个Proposer收到了多数Acceptor对prepare的回复后,就进入批准阶段。它要向回复prepare请求的Acceptor发送accept请求,包括编号n和根据prepare阶段决定的value(如果根据prepare没有已经接受的value,那么它可以自由决定value)。
在不违背自己向其他Proposer的承诺的前提下,Acceptor收到accept请求后即接受这个请求。
Mulit-Paxos
Mulit-Paxos解决的问题:在一个分布式系统中,如何就一批提案达成一致。
当存在一批提案时,用Basic-Paxos一个一个决议当然也可以,但是每个提案都经历两阶段提交,显然效率不高。Basic-Paxos协议的执行流程针对每个提案(每条redo log)都至少存在三次网络交互:1. 产生log ID;2. prepare阶段;3. accept阶段。
所以,Mulit-Paxos基于Basic-Paxos做了优化,在Paxos集群中利用Paxos协议选举出唯一的leader,在leader有效期内所有的议案都只能由leader发起。
这里强化了协议的假设:即leader有效期内不会有其他server提出的议案。因此,对于后续的提案,我们可以简化掉产生log ID阶段和Prepare阶段,而是由唯一的leader产生log ID,然后直接执行Accept,得到多数派确认即表示提案达成一致(每条redo log可对应一个提案).
Raft
Raft和Multi-Paxos的区别
Raft是基于对Multi-Paxos的两个限制形成的:
发送的请求的是连续的, 也就是说Raft的append 操作必须是连续的, 而Paxos可以并发 (这里并发只是append log的并发, 应用到状态机还是有序的)。
Raft选主有限制,必须包含最新、最全日志的节点才能被选为leader. 而Multi-Paxos没有这个限制,日志不完备的节点也能成为leader。
Raft可以看成是简化版的Multi-Paxos。
Multi-Paxos允许并发的写log,当leader节点故障后,剩余节点有可能都有日志空洞。所以选出新leader后, 需要将新leader里没有的log补全,在依次应用到状态机里。
