AWS事故总结,几招教你规避风险
美国时间 2 月 28 日,亚马逊AWS弗吉尼亚州数据中心出现单点存储区域故障,使得其云存储服务 S3 出现了较高的错误率,造成长达2小时的服务不可用。Netflix、Airbnb 、Slack、Spotify、雅虎网络邮箱等互联网服务受到明显影响。
亚马逊的本次『失误』也在警示业界所有云计算厂商,在云服务日益发展的今天,云存储的数据可靠性和服务可用性应该如何保障。当企业应对人为误操作、软件错误、病毒入侵等“软”性灾害和硬件故障、自然灾害等“硬”性灾害,应该如何实现稳定的容灾?如何实现高效的容灾?如何实现低成本的容灾?
腾讯云对象存储服务基于多年海量数据存储的经验,针对以上一系列问题,提供五个维度的解决方案:跨地域容灾,机房级别容灾,集群级别容灾,服务器级别容灾和磁盘级别容灾。
1.用户如何应对云厂商单点存储区域故障?
跨地域级别容灾:跨地域自动备份
目前腾讯云已经在华北大区,华南大区,华东大区,西南大区和东南亚大区提供了数据存储服务,并且提供『主备数据中心』的解决方案。
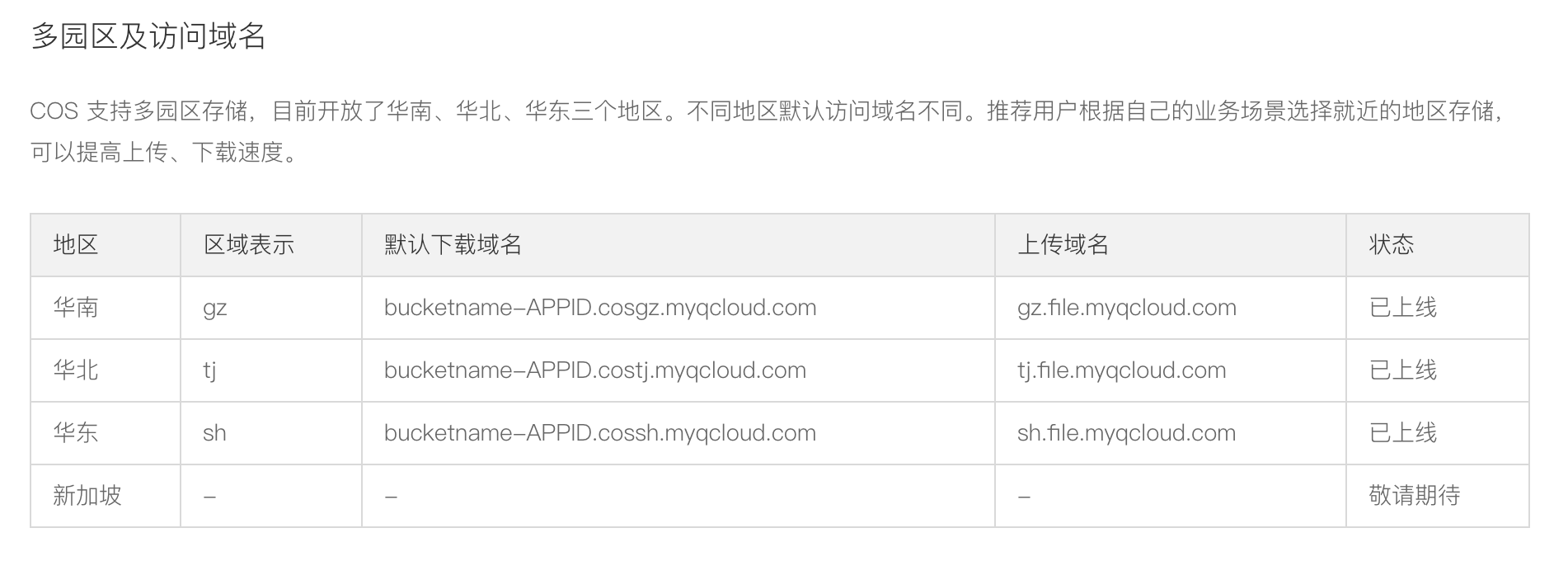
用户可以选择将主站的数据服务保留在某一区域,同时在上千公里之外保留备份数据,腾讯云将代替客户将主数据中心的数据在短时间内自动搬迁到备份数据中心,当发生运营商网络大规模瘫痪或者大面积灾难来临,用户可以将服务指向备份数据中心存储区域,应对异常问题。
2.作为云厂商,腾讯云如何避免单点故障问题?
机房级别容灾:可用区物理隔离
腾讯云目前在每个存储大区配备了多个可用区,每个可用区之内配备多个机房。每个可用区保证一定物理距离,当发生爆炸,洪水等恶劣的物理情况或者小规模运营商网络瘫痪,腾讯云将自动调度数据的写入和读取,暂停灾难受影响区域的机房使用,保留存量数据不改变。在灾难过程中新的数据写入和读取,将迁移到同城的其他机房或者临近城市的机房,整体存储大区的服务不中断。同时腾讯云拥有跨机房跨可用区的数据冗余备份能力。
集群级别容灾:不同集群互为主备
腾讯云在每一个机房中会配备多个集群,每个集群可以提供完整服务,用户的数据块被分布在不同集群的不同服务器中。如果某个特定集群失去服务能力,修复方式如同服务器异常。该集群整体暂停数据的写入和读取,保留异常现场,将数据写入迁移到同机房的其他集群中,集群内部开始自动修复逻辑模块或者存储模块。在修复过程中,用户可以从其他健康集群中持续获取数据,服务持续可用。
服务器级别容灾:条带化打散数据
第一、腾讯云利用『条带化』技术,将多备份的用户数据分解成多个数据块均匀放置在不同服务器之间。第二,集群的中央模块会定时巡检每个服务器的每块磁盘的健康程度。第三,一旦检测出单台服务器出现异常,会停止对整个集群的数据写入,将数据写入迁移到同机房的其他集群中,然后集群内部针对异常服务器启动坏盘修复,如果修复失败,7*24值班的运维人员将人工介入,更换坏盘。在修复过程中,用户可以从异常集群中健康的服务器中持续获取数据,服务持续可用。
磁盘级别容灾:多备份数据冗余
第一,对于保存在腾讯云存储服务中的每个数据块,腾讯云都实现了『RAID备份』,即一份数据会存在多个副本或者校验码。第二,腾讯云利用底层磁盘的接口将其每个磁盘且分为多个扇区。采取『心跳响应』管理的模式统一管理所有扇区。服务器的中央模块会如同如『巡逻员』一般,周期性的巡检每个扇区的状态,保证扇区的健康。第三、一旦检测出部分扇区发生异常,会对停止针对该扇区的写入和读取,然后利用冗余数据对原有的扇区进行修复。在这个修复过程中用户仍然可以读取冗余数据,服务持续可用。
数据持久和服务可用是云服务厂商的生命线,只有完备的预案才能获得用户信赖。腾讯云对象存储服务向客户承诺99.999999999%的数据可靠性和99.95%的服务可用性。基于这五个维度的数据容灾解决方案,腾讯云数据存储已经向GIF快手,芒果TV,CNTV等多家厂商提供可靠稳定的服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号