
提取猫眼电影正在热映电影以及评分
1.使用urllib爬取百度搜索html2.urllib.request.Request对象封装请求3.urllib发送get请求_中文传参问题4.urllib发送post请求获取html源代码5.获取动态页面html6.忽略SSL证书验证7.使用fake-useragent库伪装请求头8.urllib自定义opener对象设置代理IP9.爬虫cookie的使用10.保存与读取cookie11.使用urllib.error进行请求异常处理12.使用requests库发送get和post请求13.使用Request伪装User-Agent和IP地址14.requests设置超时时间/requests.Session自动保存cookie/verify忽略ssl证书15.re模块的正则表达式规则16.使用re的正则表达式提取腾讯体育新闻摘要17.BeautifulSoup4解析数据18.bs4.find_all()搜索文档树和css选择器提取解析后的html数据19.bs4解析并提取人民网新闻标题数据20.xpath解析数据21.谷歌浏览器的xpath插件安装22.使用re和lxml的xpath功能提取纵横中文网小说推荐榜前3页标题23.JSON数据24.使用jsonpath快速提取json的数据
25.提取猫眼电影正在热映电影以及评分
26.单线程与多线程爬虫目标:提取热映电影的名称和评分
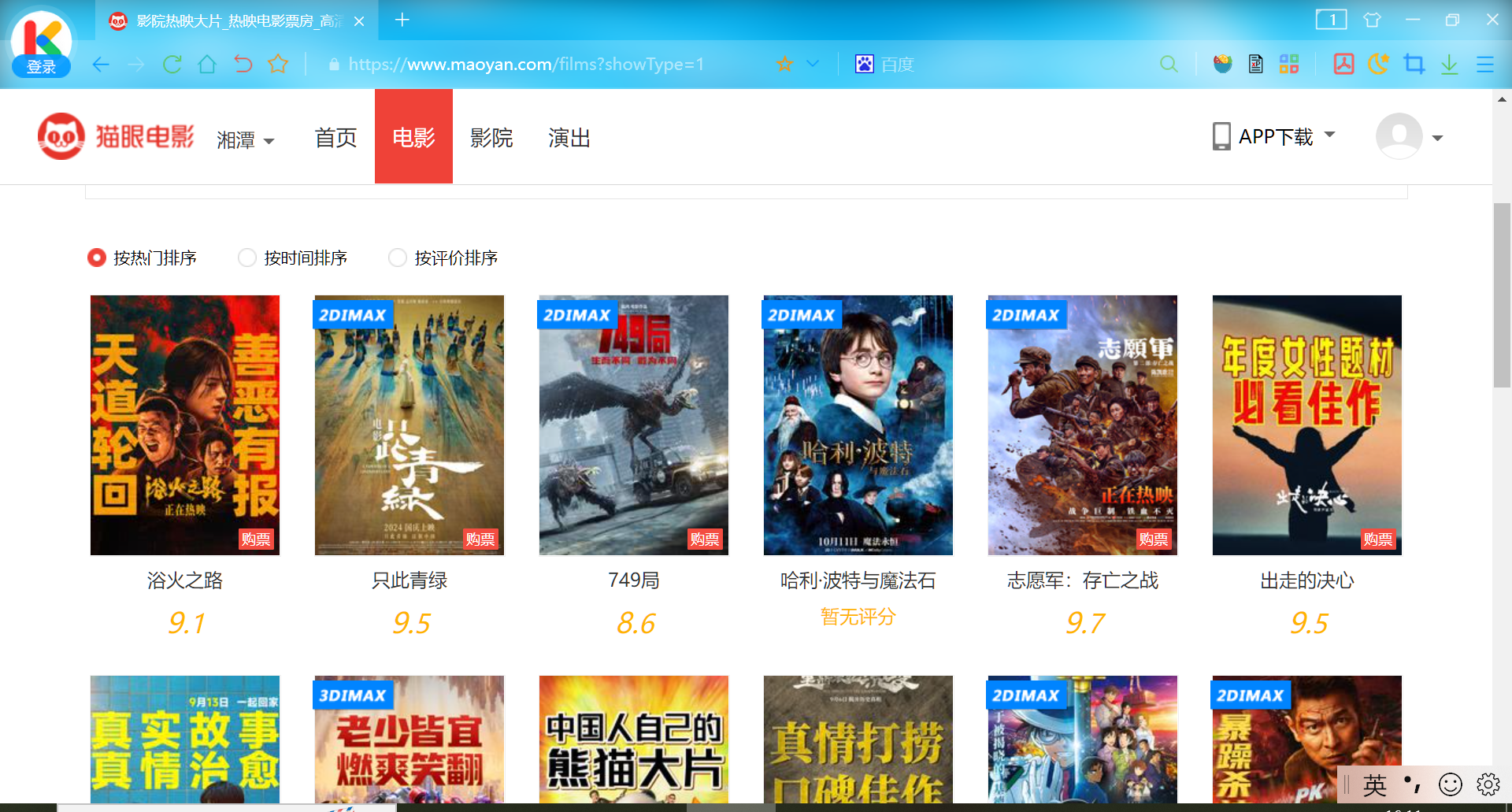
首先获取响应内容
from fake_useragent import UserAgent
import requests
# url地址
url = 'https://www.maoyan.com/films?showType=1'
# 设置请求头
headers = {'User-Agent': UserAgent().chrome}
# 发送请求
resp = requests.get(url, headers=headers)
# 将响应内容写入maoyan.txt
with open('maoyan1.txt', 'w') as f:
f.write(resp.text)运行代码
bs4的css选择器提取
from bs4 import BeautifulSoup
def bs_extract():
# 读取maoyan.txt
with open('maoyan.txt', 'r') as f:
resp = f.read()
# bs4解析响应
soup = BeautifulSoup(resp, 'lxml')
# 提取名称
names = [div.text for div in soup.select('div[class="channel-detail movie-item-title"]>a')]
# 提取评分
scores = [div.text for div in soup.select('div[class="channel-detail channel-detail-orange"]')]
# 打印结果
for n,s in zip(names, scores):
print(f'{n}: {s}')
if __name__ == '__main__':
bs_extract()pyquery提取
from pyquery import PyQuery as pq
def pyquery_extract():
# 读取maoyan.txt中的响应结果
with open('maoyan1.txt', 'r')as f:
resp = f.read()
# 解析响应
# 构建一个pyquery对象
doc = pq(resp)
name_divs = doc('div.channel-detail.movie-item-title')
names = [name_divs.eq(i).text() for i in range(len(name_divs))]
score_divs = doc('div.channel-detail.channel-detail-orange')
scores = [score_divs.eq(i).text() for i in range(len(score_divs))]
# 打印结果
for n, s in zip(names, scores):
print(f'{n}: {s}')
if __name__ == '__main__':
pyquery_extract()xpath提取
from lxml import etree
def xpath_extract():
# 读取maoyan.txt中存放的响应内容
with open('maoyan.txt', 'r')as f:
resp = f.read()
# 解析响应内容
# 创建etree对象
e = etree.HTML(resp)
# 提取名称
names = e.xpath('//dd/div[2]/a')
# 提取评分
scores = [div.xpath('string(.)') for div in e.xpath('//div[@class="channel-detail channel-detail-orange"]')]
# 打印结果
for n, s in zip(names, scores):
print(f'{n.text}: {s}')
if __name__ == '__main__':
xpath_extract()re提取
import re
def re_extract():
with open('maoyan.txt', 'r')as f:
resp = f.read()
names = re.findall('<div class="channel-detail movie-item-title" title="(.+?)">', resp)
scores = re.findall('<div class="channel-detail channel-detail-orange">(.+?)</div>',resp)
num = len(scores)
for i in range(num):
if scores[i] != '暂无评分':
# print(re.findall('<i class="integer">(\\d).</i><i class="fraction">(\\d)</i>', scores[i])) 结果为元组存放在列表中[('9', '1')]
scores[i] = '.'.join(re.findall('<i class="integer">(\\d).</i><i class="fraction">(\\d)</i>', scores[i])[0])
for n, s in zip(names, scores):
print(f'{n}: {s}')
if __name__ == '__main__':
re_extract()运行结果
浴火之路: 9.1
只此青绿: 9.5
749局: 8.6
哈利·波特与魔法石: 暂无评分
志愿军:存亡之战: 9.7
出走的决心: 9.5
野孩子: 9.2
变形金刚:起源: 9.4
熊猫计划: 9.4
里斯本丸沉没: 9.6
名侦探柯南:百万美元的五棱星: 9.1
危机航线: 9.4
异形:夺命舰: 8.7
爆款好人: 9.0
荒野机器人: 9.5
姥姥的外孙: 9.4
哈利·波特与密室: 暂无评分
绑架游戏: 暂无评分
新大头儿子和小头爸爸6:迷你大冒险: 9.3
一雪前耻: 8.8


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?