
urllib发送get请求_中文传参问题
1.使用urllib爬取百度搜索html2.urllib.request.Request对象封装请求
3.urllib发送get请求_中文传参问题
4.urllib发送post请求获取html源代码5.获取动态页面html6.忽略SSL证书验证7.使用fake-useragent库伪装请求头8.urllib自定义opener对象设置代理IP9.爬虫cookie的使用10.保存与读取cookie11.使用urllib.error进行请求异常处理12.使用requests库发送get和post请求13.使用Request伪装User-Agent和IP地址14.requests设置超时时间/requests.Session自动保存cookie/verify忽略ssl证书15.re模块的正则表达式规则16.使用re的正则表达式提取腾讯体育新闻摘要17.BeautifulSoup4解析数据18.bs4.find_all()搜索文档树和css选择器提取解析后的html数据19.bs4解析并提取人民网新闻标题数据20.xpath解析数据21.谷歌浏览器的xpath插件安装22.使用re和lxml的xpath功能提取纵横中文网小说推荐榜前3页标题23.JSON数据24.使用jsonpath快速提取json的数据25.提取猫眼电影正在热映电影以及评分26.单线程与多线程爬虫GET请求是HTTP协议中的一种基本方法,当需要在GET请求中传递中文参数时需要额外对中文进行编码(英文不需要),因为url中只能包含ascii字符。
可以使用urllib.parser.urlencode()或urllib.parse.quote()方法对中文转码。
详细查官方文档: https://docs.python.org/3.12/library/urllib.parse.html#module-urllib.parse
查看使用百度搜索“python爬虫”时,url会传递哪些参数
传递参数以“?”开始,由“&”分割。其中“python爬虫”传递给了“wd”。

浏览器将中文转换为url编码
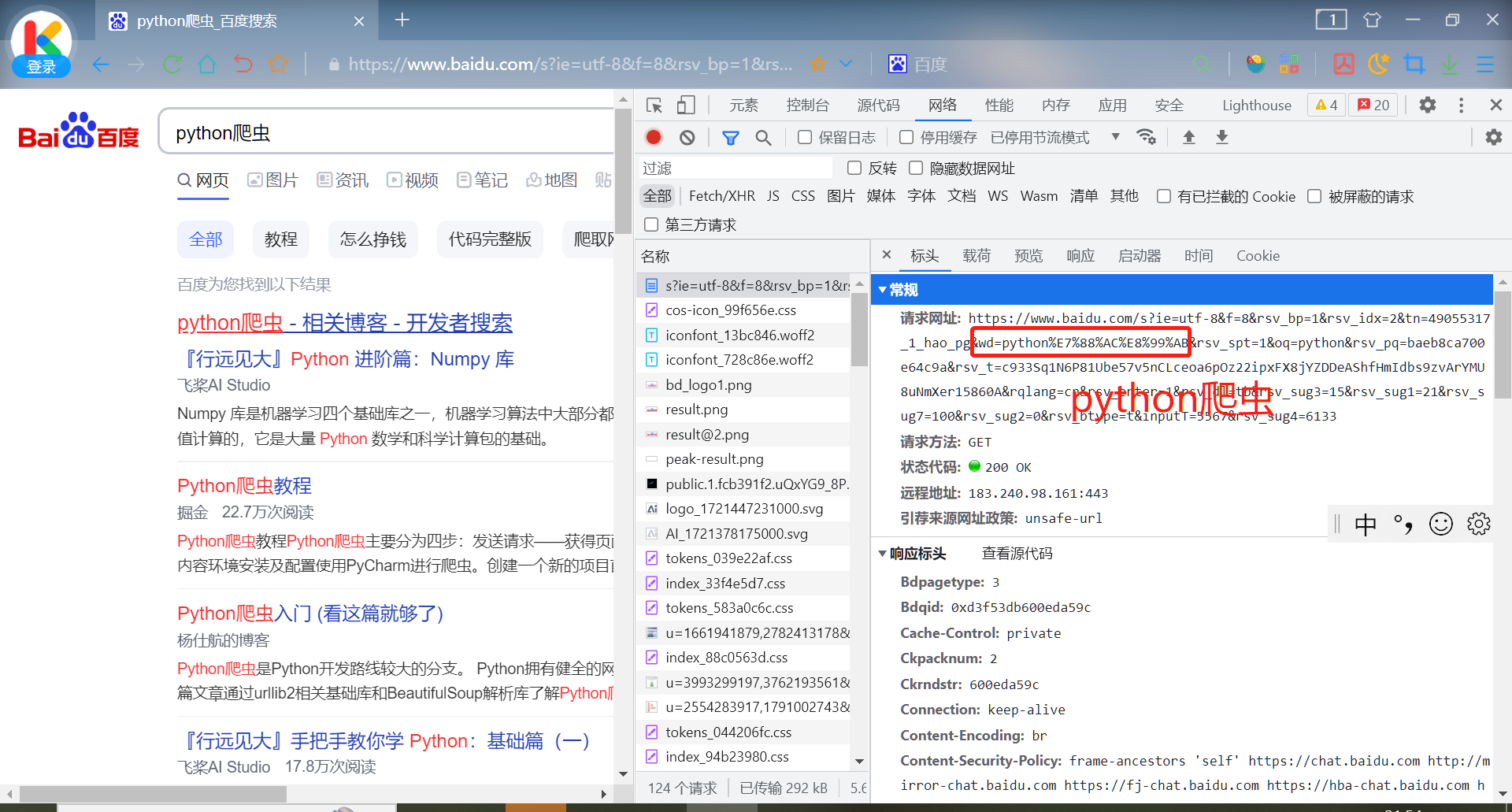
直接使用中文传参会报错
对wd直接传中文参数
from urllib.request import urlopen, Request
# 请求地址
url = 'https://www.baidu.com/s?wd=python爬虫'
# 创建Request对象
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'}
req = Request(url, headers=headers)
# 发送请求
resp = urlopen(req)
# 读取响应内容
print(resp.read().decode())
# 关闭连接
resp.close()
部分报错信息为:
UnicodeEncodeError: 'ascii' codec can't encode characters修改上述代码url = 'https://www.baidu.com/s?wd=python%E7%88%AC%E8%99%AB'可以执行成功
使用python的urllib库对中文编码
urllib.parse.quote()
from urllib.parse import quote
# urllib.parse.quote()转换一个值
args = 'python爬虫'
print(quote(args))
'''
运行结果:
python%E7%88%AC%E8%99%AB
'''urllib.parse.urlencode()
from urllib.parse import urlencode
# urllib.parse.urlencode() 转换键值对
args = {'wd': 'python爬虫'}
print(urlencode(args))
'''
运行结果:
wd=python%E7%88%AC%E8%99%AB
'''两种方法实现含中文传参的GET请求
from urllib.request import Request, urlopen
from urllib.parse import quote, urlencode
# 请求地址
args1 = 'python爬虫' # 方法一,使用urllib.parse.quote()
# 方法二,使用urllib.parse.urlencode()
# args2 = {'wd': 'python爬虫'}
url = f'https://www.baidu.com/s?wd={quote(args1)}'
# url = f'https://www.baidu.com/s?{urlencode(args2)}'
# 创建Request对象
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'}
req = Request(url, headers=headers)
# 发送请求
resp = urlopen(req)
# 获取响应码
print(resp.getcode())
# 关闭连接
resp.close()响应码为200即请求成功。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?