Python爬虫入门
爬虫概念&理论基础
爬虫:从html里面,用循环,快速获取大量信息;
爬虫爬的都是:非机密信息;只是用循环,批量获取而已;
爬虫三种方式:
1)python爬;全部数据在前端dom里面,扒出来我们需要的信息;【lxml里面的etree解析工具、requests:看文档调函数】
2)nodered爬:比较难用
3)chrome爬:在F12控制台里面,用JS语法(含正则表达式)剥离出数据;
爬虫不一定用Python
用JS、Java等等都可以;
Python的优势在于:第三方库丰富、上手简单
爬虫后的处理: 封装+筛选(用正则表达式)+排序
爬虫攻防战
恶意爬虫:
影响网站正常运营:请求资源过多
反爬虫机制:
就是人机识别(验证码、滑动条、图片验证)+加密解密
爬虫难点:
- 绕过部分反爬虫机制(人机识别+加密解密)
- 编码解码问题(charset / encoding)
- 多重爬取(打开多个子页面,再爬取)
- 复杂正则匹配
- 如果不在前端HTML里面,就要先到Network里面看包的内容
- 开多线程加速爬取
B站资源:
【基础txt】
https://www.bilibili.com/video/BV1ak4y1y7SH?p=1
【图片批量下载】
https://www.bilibili.com/video/BV1YL411J7jB?spm_id_from=333.337.search-card.all.click
【详细 教程+案例】
https://www.bilibili.com/video/BV1i54y1h75W?spm_id_from=333.337.search-card.all.click
python从页面爬取多个URL,并下载图片
python读写文件秘籍:https://blog.csdn.net/weixin_41770169/article/details/82963918
from urllib.request import urlopen import re import requests import numpy url = "https://www.cnblogs.com/qyf2199/p/12620558.html" res = urlopen(url) ##(1)直接打印 html # print(res.read().decode("utf-8")) # print(res.read()) #decode解码 ##(2)将html存储为文件 with open("Data.txt", mode="wb") as f: f.write(res.read()) ##这里是写到文件,所以不用解码,要写进去二进制 html = requests.get(url).text # print(html) urls = re.findall('https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+', html) urls = re.findall('https?://img2020.cnblogs.com/blog/1806053/202004/1806053-\d+-\d+\.png', html) ##正则化匹配寻找【html】中的【图片url】信息 print(urls) ##一次性打印 numpy.save("URLs", urls) ##这里是写数组到文件,而不是普通的写入文件,用到numpy包 ##【从文件里面读取内容】 ##【1】读取txt f = open("Data.txt", "r", encoding="utf-8") # 设置文件对象 str0 = f.read() # 将txt文件的所有内容读入到字符串str中 f.close() # 将文件关闭 # print(str0) ##打印到terminal ##【2】读取npy文件 urls_npy = numpy.load("URLs.npy") print(urls_npy) # 正则获取合适的图片url obj = re.compile(r"https?://img2020.cnblogs.com/blog/1806053/202004/1806053-\d+-\d+\.png") ##正则化匹配有点傻傻的堆砌 ret = obj.finditer(html) i = 0 for r in ret: print(r.group()) ##每个url分别打印 print("第",i,"张图片下载完毕") i = i + 1 pic_name = "C:\\Users\\jinqingyang\\Desktop\\pythonProject\\PythonCrawler\\PNG\\pic_"+str(i)+".png" ##str()用于强制类型转换 ##String之间直接用 +来拼接 # with open(pic_name, mode="wb")as f: ##直接保存到相对路径 with open(pic_name, mode="wb")as f: ##保存到指定路径 f.write(requests.get(r.group()).content) ##.content转换为字节码
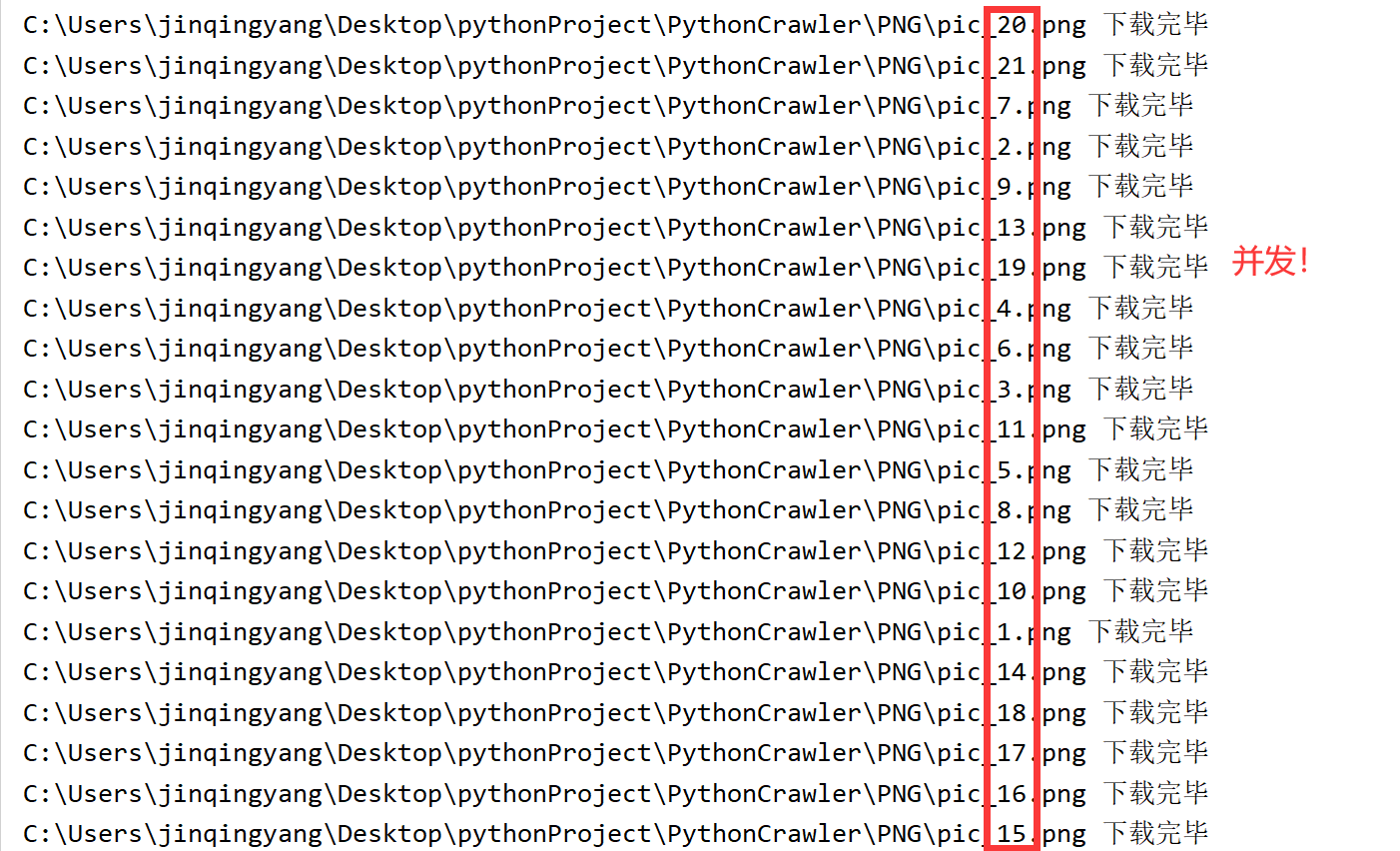
采用python带有的并发机制,来提高下载速度:
将上面代码中的下载部分改为并发机制:
from concurrent.futures import ThreadPoolExecutor ## python的并发 def download_pic(pic_name, r): with open(pic_name, mode="wb")as f: f.write(requests.get(r.group()).content) print(pic_name,"下载完毕") ##控制台打印进度 i = 0 with ThreadPoolExecutor(25) as t: for r in ret: i = i + 1 pic_name = "C:\\Users\\jinqingyang\\Desktop\\pythonProject\\PythonCrawler\\PNG\\pic_" + str(i) + ".png" t.submit(download_pic,pic_name, r)
2秒钟就下载完毕了,所有都在同时下载