
kvm热迁移
第一部分 SR-IOV简介
https://cloud.tencent.com/developer/article/1087112
1.1 SR-IOV简介
SR-IOV(PCI-SIG Single Root I/O Virtualization and Sharing)是PCI-SIG组织发布的规范。
设计PCI-SIG SR-IOV 规范的目的是:通过为虚拟机提供独立的内存地址、中断和DMA流而避免VMM的介入。SR-IOV允许一个PCI设备提供多个VFs。VMM将一个或者多个 VF 分配给一个虚机。一个VF同时只能被分配一个虚机。而虚拟机感知不到这个网卡是被VF的还是普通的物理网卡。
1.2 SR-IOV引入了两个PCIe的function types
PFs:包括管理SR-IOV功能在内的所有PCIe function。
VFs:一部分轻量级的PCIe function,只能进行必要的数据操作和配置。
1.3 R-IOV工作流程中有三个角色
1.PCIe的SR-IOV机制:提供独立可配置的多个VFs,每一个VFs具有独立的PCIe配置空间。
2.VMM:则把VFs分配给虚拟机。
3.VT-x和VT-d:通过硬件辅助技术提供和虚拟机之间的直接DMA数据映射传输,跳过VMM的干预。
1.4 SR-IOV原理
下面一幅图描述了SR-IOV的原理(来自intel《PCI-SIG SR-IOV Prime》):
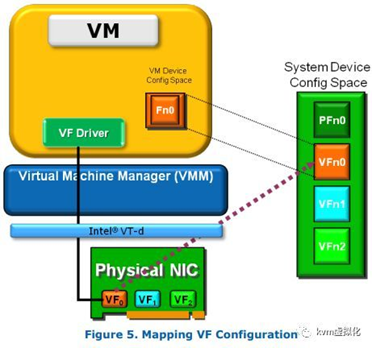
1.5 SR-IOV的优缺点
SR-IOV相对与软件模拟IO虚拟化的优点:
1.降低了IO延迟和对CPU的占用,获得了接近原生的IO性能,因为虚拟机直接使用VFs,没有了VMM的陷入处理。
2.数据更加安全,因为每个VF属于一个IOMMU Group,共享IOMMU Group的设备不能分配给不同的虚拟机,而每个IOMMU Group又有独立的内存。
SR-IOV相对与Device assignment的优点:
没有了一个PCI设备只能给一个虚拟机的尴尬,SR-IOV下多个虚拟机可通过独占VFs的方式共享一个PCI设备。
SR-IOV的缺点:
使用了VFs的虚拟机不能在线迁移。
第二部分 KVM热迁移原理
https://www.ibm.com/developerworks/cn/linux/l-cn-mgrtvm1/index.html 介绍原理
https://www.ibm.com/developerworks/cn/linux/l-cn-mgrtvm2/index.html 实验(操作qemu执行热迁移)
https://developers.redhat.com/blog/2015/03/24/live-migrating-qemu-kvm-virtual-machines/
2.1 概述
迁移的前面阶段,服务在源主机运行,当迁移进行到一定阶段,目的主机已经具备了运行系统的必须资源,经过一个非常短暂的切换,源主机将控制权转移到目的主机,服务在目的主机上继续运行。
对于 VM 的内存状态的迁移,XEN 和 KVM 都采用了主流的的预拷贝(pre-copy)的策略。迁移开始之后,源主机 VM 仍在运行,目的主机 VM 尚未启动。迁移通过一个循环,将源主机 VM 的内存数据发送至目的主机 VM。循环第一轮发送所有内存页数据,接下来的每一轮循环发送上一轮预拷贝过程中被 VM 写过的脏页内存 dirty pages。直到时机成熟,预拷贝循环结束,进入停机拷贝阶段,源主机被挂起,不再有内存更新。最后一轮循环中的脏页被传输至目的主机 VM。
预拷贝机制极大的减少了停机拷贝阶段需要传输的内存数据量,从而将停机时间大大缩小。【意思是预拷贝不影响vm的在线运行,减少了停机时间】
最右边部分的图表是QEMU状态,整个状态不涉及迁移过程。但是在迁移开始之前将这个状态设置正确很重要。在源主机和目的主机上的QEMU设置必须相同,这是通过在两个主机上使用一条相似的QEMU命令行来实现的。由于QEMU命令行的多种选择非常难以搞定,我们使用Libvirt替我们选择正确的。Libvirt可以确保QEMU两边程序的迁移设置正确性。
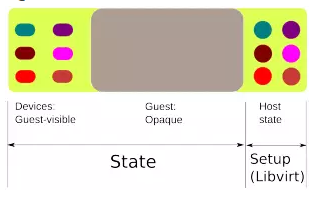
在线迁移分3个阶段:
第一个阶段:将所有RAM都标记脏
第二个阶段:持续不断发送脏RAM,当达到一些低水印或者条件时停止
第三个阶段:停止运行客户机,将剩余脏RAM,设备状态转移过去,在目标主机QEMU上启动虚拟机
在第二阶段代码,我们会在每个迭代来检查有多少页面被客户机标记脏。会检查花费多长时间来转换一个页面,以便来设定一个预估的网络带宽。在这个预估带宽和当前迭代的脏页面数量,我们可以计算出花费多久来转化剩余页面。如果在可接受或者设置的停机时间限制内,我们过渡到第三阶段是没有问题的。否则我们会继续停留在第二阶段。
QEMU中还有更多的与迁移有关的代码:有些代码是用来发送/接受迁移数据:TCP或者UNIX包,本地文件说明符,或者RDMA。也有exec功能,来自QEMU的数据,在被发送到目的地前,会被传输到其他进程。这对于传出数据压缩,加密都很有用。在目的端,也需要进行解压缩或者解加密进程。对于UNIX包,fd或者exec-based协议,需要更高层的程序来管理两端的迁移。Libvirt就是这个程序,我们可以依赖libvirt的能力来控制这个迁移。
2.2 如何判断”时机成熟“
对于更新速度非常快的内存部分,每次循环过程都会变脏,需要重复 pre-copy,同时也导致循环次数非常多,迁移的时间变长。针对这种情况,KVM 虚拟机建立了三个原则:集中原则,一个循环内的 dirty pages 小于等于 50;不扩散原则, 一个循环内传输的 dirty pages 少于新产生的;有限循环原则,循环次数必须少于 30。在实现上,就是采取了以下措施:
- 有限循环:循环次数和效果受到控制,对每轮 pre-copy 的效果进行计算,若 pre-copy 对于减少不一致内存数量的效果不显著,或者循环次数超过了上限,循环将中止,进入停机拷贝阶段。
- 在被迁移 VM 的内核设置一个内存访问的监控模块。在内存 pre-copy 过程中,VM 的一个进程在一个被调度运行的期间,被限制最多执行 40 次内存写操作。这个措施直接限制了 pre-copy 过程中内存变脏的速度,其代价是对 VM 上的进程运行进行了一定的限制。【这个模块是要改guest OS吗?】
2.3 迁移过程详解
(1)系统验证目标服务器的存储器和网络设置是否正确,并预保留目标服务器虚拟机的资源。
图 1. 源服务器和目标服务器简图

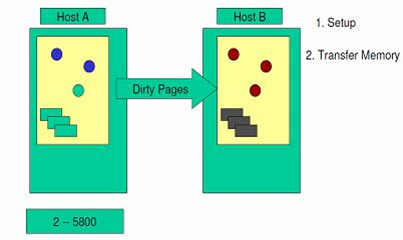
(2)当虚拟机还在源服务器上运转时,第一个循环内将全部内存镜像复制到目标服务器上。在这个过程中,KVM 依然会监视内存的任何变化。
图 2. 内存镜像复制示意图

(3)以后的循环中,检查上一个循环中内存是否发生了变化。 假如发生了变化,那么 VMM 会将发生变化的内存页即 dirty pages 重新复制到目标服务器中,并覆盖掉先前的内存页。在这个阶段,VMM 依然会继续监视内存的变化情况。
图 3. 进行有变化的内存复制
(4)VMM 会持续这样的内存复制循环。随着循环次数的增加,所需要复制的 dirty pages 就会明显减少,而复制所耗费的时间就会逐渐变短,那么内存就有可能没有足够的时间发生变化。最后,当源服务器与目标服务器之间的差异达到一定标准时,内存复制操作才会结束,同时暂停源系统。
图 4. 所需复制的数据在减少

(5)在源系统和目标系统都停机的情况下,将最后一个循环的 dirty-pages 和源系统设备的工作状态复制到目标服务器。
图 5. 状态信息的复制
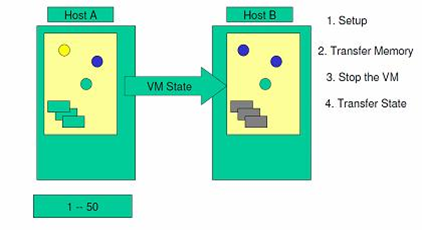
(6)然后,将存储从源系统上解锁,并锁定在目标系统上。启动目标服务器,并与存储资源和网络资源相连接。
图 6. 停止源服务器,启动目标服务器

第三部分 passthrough与SR-IOV区别、vhost和vhost-user等
https://www.cnblogs.com/sammyliu/p/4548194.html
http://virtual.51cto.com/art/201801/563894.htm
https://blog.csdn.net/qq_15437629/article/details/77899905
http://blog.vmsplice.net/2011/09/qemu-internals-vhost-architecture.html
https://spdk.io/doc/vhost_processing.html
3.1 Passthrough
设备直接分配 (Device assignment)也称为 Device Pass-Through。
先简单看看PCI 和 PCI-E 的区别(AMD CPU):
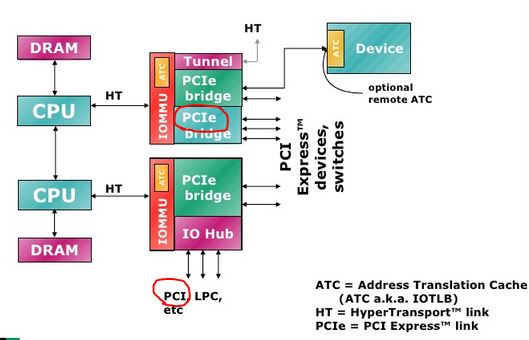

(简单点看,PCI 卡的性能没有 PCI-E 高,因为 PCI-E 是直接连在 IOMMU 上,而 PCI 卡是连在一个 IO Hub 上。)
IOMMU = Input/Output Memory Management Unit
主要的 PCI 设备类型:
- Network cards (wired or wireless)
- SCSI adapters
- Bus controllers: USB, PCMCIA, I2C, FireWire, IDE
- Graphics and video cards
- Sound cards
- 好处:在执行 I/O 操作时大量减少甚至避免 VM-Exit 陷入到 Hypervisor 中,极大地提高了性能,可以达到几乎和原生系统一样的性能。VT-d 克服了 virtio 兼容性不好和 CPU 使用频率较高的问题。
- 不足:(1)一台服务器主板上的空间比较有限,因此允许添加的 PCI 和 PCI-E 设备是有限的。大量使用 VT-d 独立分配设备给客户机,让硬件设备数量增加,这会增加硬件投资成本。(2)对于使用 VT-d 直接分配了设备的客户机,其动态迁移功能将受限,不过也可以使用热插拔或者libvirt 工具等方式来缓解这个问题。
- 不足的解决方案:(1)在一台物理宿主机上,仅少数 I/O 如网络性能要求较高的客户机使用 VT-d直接分配设备,其他的使用纯模拟或者 virtio 已达到多个客户机共享同一个设备的目的 (2)对于网络I/O的解决办法,可以选择 SR-IOV 是一个网卡产生多个独立的虚拟网卡,将每个虚拟网卡分配个一个客户机使用。
硬盘直接分配:
- 一般 SATA 或者 SAS 等类型的硬盘的控制器都是直接接入到 PCI 或者 PCI-E 总线的,所以也可以将硬盘作为普通的PCI设备直接分配个客户机。需要注意的是,当分配硬盘时,实际上将其控制器作为一个整体分配到客户机中,因此需要在硬件平台上至少有另两个或者多个SATA或者 SAS控制器。
3.2 Passthrough分配示例:
准备工作:
(1)在 BIOS 中打开 Intel VT-d
(2)在 Linux 内核中启用 PCI Pass-through
添加 intel_iommu=on 到 /boot/grub/grub.conf 文件中。(在我的 RedHat Linux 6上,该文件是 /boot/grub.conf)
(3)重启系统,使得配置生效
实际分配:
(1)使用 lspci -nn 命令找到待分配的 PCI 设备。这里以一个 FC 卡为例:

使用 lspci 命令得到的 PCI 数字的含义,以后使用 libvirt API 分配设备时会用到:

(2)使用 virsh nodedev-list 命令找到该设备的 PCI 编号
(3)将设备从主机上解除

(4)使用 virt-manager 将设备直接分配给一个启动了的虚拟机
3.3 各种设备虚拟化方式的比较【注意:什么是vhost???】


3.4 IO设备的虚拟化方式
3.4.1 全虚拟化下vm的IO路径
(1)当虚拟机进行I/O操作时,根据《也谈Intel的cpu虚拟化》我们知道,虚拟机通过VM exit将cpu控制权返回给VMM,从而陷入到root模式下的ring0内的VMM,进行”陷入模拟“。
(2)将本次I/O请求的信息存放到IO共享页,QEMU从IO共享页读取信息后由硬件模拟代码来模拟出本次的IO操作,并调用内核中的硬件驱动把IO请求发送到物理硬件,完成之后将结果放回到IO共享页。
(3)KVM模块中的捕获代码读取IO共享页中的结果,把结果返回到guest。
(4)通过VM entry,guest再次获得cpu控制权,根据IO返回的结果进行处理。
说明:VMM和guest的IO信息共享不光IO共享页一种,还可以使用DMA。QEMU不把IO结果放到IO共享页中,而是通过DMA将结果直接写到guest的内存中去,然后通过KVM模块告诉客户机DMA操作已经完成。

3.4.2 半虚拟化virtio
guest和host使用使用virtio前后端的技术减少了guest IO时的VM Exit(guest和host的上下文切换)并且使guest和host能并行处理IO来提高throughput和减少latency。但是IO的路径并没有比全虚拟化技术减少。下面是virtio的IO路径:
guest在IO请求时,首先guest需要切换到host kernel,然后host kernel会切换到hyperisor来处理guest的请求,hypervisor通过系统调用将数据包发送到外部网络后切换回host kernel,然后再切换回guest。这个长IO路径和全虚拟化时相同的,只是减少了VM exit和VM entry。
IBM在2005年提出了virtio, 虚拟机中的半虚拟化前端驱动和主机上的后端服务简单的使用virtqueue共享队列交换数据,大幅的减少了e1000模拟时复杂的io操作,从而可以较大程度的提升虚拟网络性能。

guest使用virtio driver将请求发送给virtio-backend。
图中描述了virtio的io路径: guest发出中断信号退出kvm,从kvm退出到用户空间的qemu进程。然后由qemu开始对tap设备进行读写。 可以看到这里从用户态进入内核,再从内核切换到用户态,进行了2次切换。
virtio的io路径:guest设置好tx→kick host→guest陷出到kvm→kvm从内核切换到用户态的qemu进程→qemu将tx数据投递到tap设备
3.4.3 vhost和vhost-user
为了解决virio的IO路径太长的问题,vhost产生了。它是位于host kernel的一个模块,用于和guest直接通信,所以数据交换就在guest和host kernel间进行,减少了上下文的切换。
vhost相对与virto架构,把virtio驱动后端驱动从用户态放到了内核态中(vhost的内核模块充当virtiO后端驱动),在内核中加入了vhost-net.ko模块,使得对网络数据可以在内核态得到处理。


guest发出中断信号退出kvm,kvm直接和vhost-net.ko通信,然后由vhost-net.ko访问tap设备。 这样网络数据只需要经过从用户态到内核态的一次切换,就可以完成数据的传输。大大提高了虚拟网卡的性能。
路径:guest设置好tx→kick host→guest陷出到kvm→vhost-net将tx数据投递到tap设备
vhost-user和vhost类似,只是使用一个用户态进程vhost-user代替了内核中的vhost模块。
vhost-user进程和Guset之间时通过共享内存的方式进行数据操作。vhost-user相对与vhost架构,把virtio驱动后端驱动从内核态又放回到了用户态中(vhost-user进程充当virtiO后端驱动)。
它将网络数据放入用户态处理将可以得到更灵活的形式:
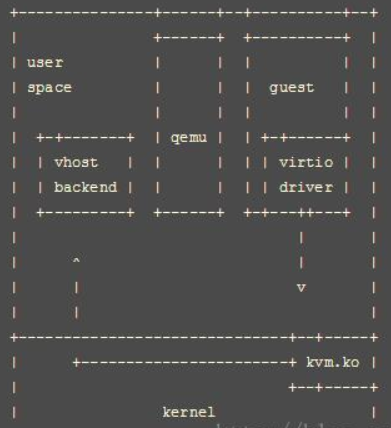
路径:guest设置好tx→kick host→guest陷出到kvm→kvm将通知vhost-backend→vhost-backend将tx数据直接发送到nic设备
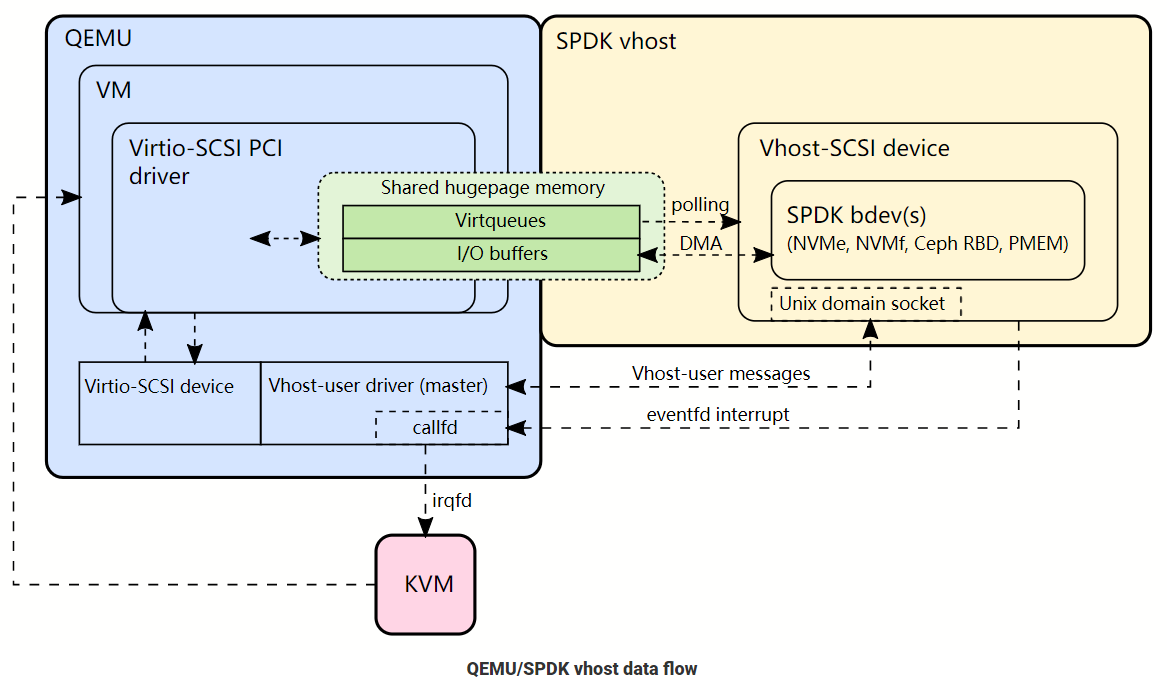
vhost-backend从原来kernel中的vhost-net 变成了用户空间的snabbswitch,snabbswitch直接接管物理网卡的驱动,从而直接控制网络信息的输入输出。snabbswitch主要使用了下面的技术来提高性能:
- 采用了大页来作为host和vm之间通信的内存空间
- 用户态操作网卡,使用类似于netmap的zero copy技术来加速对物理设备的访问
- 使用numa技术,加快中断响应速率
值得一提的是使用snabbswitch后,不用再使用原来的tap设备模拟的网卡。
使用vhost-user技术,从虚拟机到host上实现了数据的zero copy(通过大页共享),host到nic的zero copy(snabbswitch实现的驱动),能进一步加快数据的传输。
DPDK便是一个在用户态可以直接操作物理网卡的库函数,它和vhost-user结合便可以实现类似于snabb switch一样性能强劲的用户态交换机了。
【有了vhost-user,DPDK和SPDK(storage performance xx)等加速框架就得以实现了】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号