2023数据采集与融合技术实践作业四
作业1:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
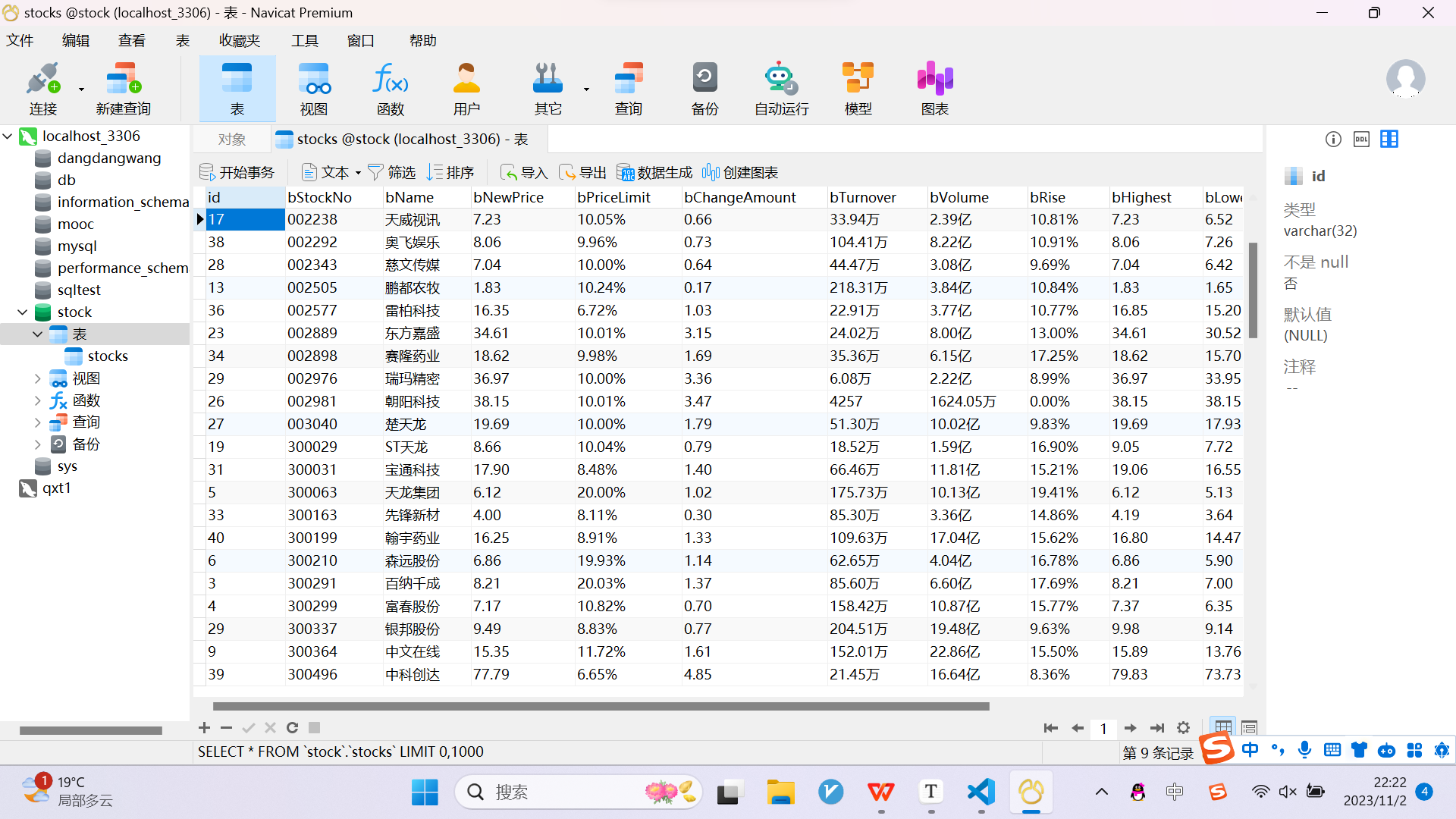
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:

代码:
通过XPATH找元素:
stocks = self.driver.find_elements(By.XPATH, "//div[@class='listview full']//tbody//tr")
for stock in stocks:
code = stock.find_element(By.XPATH, ".//td[position()=2]//a").text
name = stock.find_element(By.XPATH, ".//td[position()=3]//a").text
new_price = stock.find_element(By.XPATH, ".//td[position()=5]//span").text
price_limit = stock.find_element(By.XPATH, ".//td[position()=6]//span").text
change_amount = stock.find_element(By.XPATH, ".//td[position()=7]//span").text
turnover = stock.find_element(By.XPATH, ".//td[position()=8]").text
volume = stock.find_element(By.XPATH, ".//td[position()=9]").text
rise = stock.find_element(By.XPATH, ".//td[position()=10]").text
highest = stock.find_element(By.XPATH, ".//td[position()=11]//span").text
lowest = stock.find_element(By.XPATH, ".//td[position()=12]//span").text
today_open = stock.find_element(By.XPATH, ".//td[position()=13]//span").text
yesterday_receive = stock.find_element(By.XPATH, ".//td[position()=14]").text
self.count += 1
“上证A股”与“深证A股”:
def run(self):
urls = [
"http://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"http://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"http://quote.eastmoney.com/center/gridlist.html#sz_a_board"
]
for url in urls:
self.executeSpider(url)
翻页:
nextPage = self.driver.find_element(By.XPATH,"//a[@class='next paginate_button']")
nextPage.click()
time.sleep(2)
数据库:
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",passwd="123456", db="stock", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
# Check if the table exists, and if not, create it
self.cursor.execute("SHOW TABLES LIKE 'stocks'")
if self.cursor.fetchone() is None:
self.cursor.execute("create table stocks (id varchar(32), bStockNo varchar(32) primary key, bName varchar(32), bNewPrice varchar(32), bPriceLimit varchar(32), bChangeAmount varchar(32), bTurnover varchar(32), bVolume varchar(32), bRise varchar(32), bHighest varchar(32), bLowest varchar(32), bTodayOpen varchar(32), bYesterdayReceive varchar(32))")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def closeUp(self):
try:
if self.opened:
self.con.commit()
self.opened = False
self.driver.close()
except Exception as err:
print(err)
结果:
心得体会:
这道题与上次作业的题目一样,只是换了一种方法完成,通过这次实验,对selenium和mysql有了更进一步的了解。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL模拟登录慕课网,并获取学生自己账户中已学课程的信息保存到MySQL中(课程号、课程名称、授课单位、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。
候选网站:中国mooc网:https://www.icourse163.org
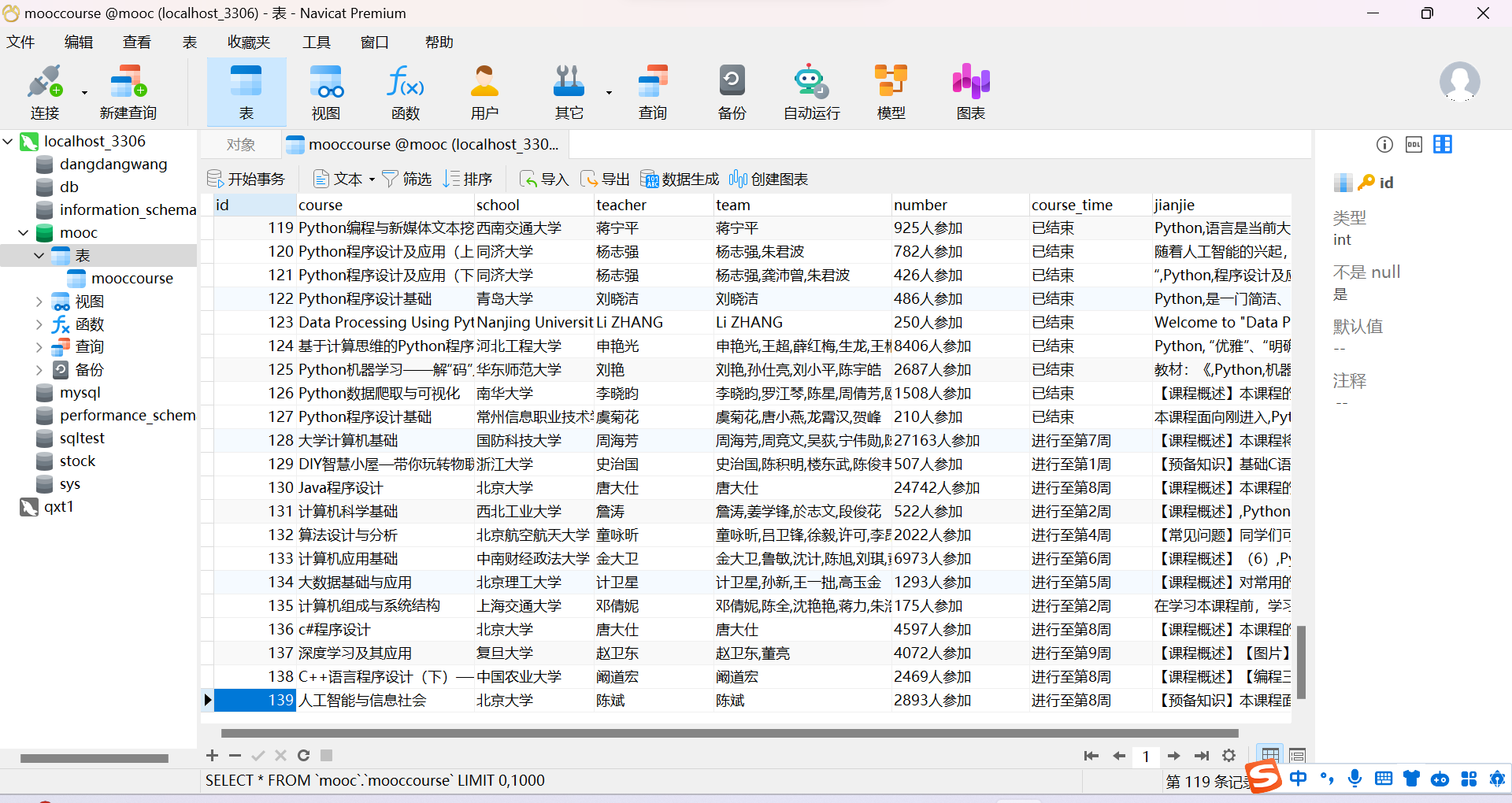
输出信息:MYSQL数据库存储和输出格式
表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义设计表头:
| Id | cCourse | cCollege | cSchedule | cCourseStatus | cImgUrl |
|---|---|---|---|---|---|
| 1 | Python网络爬虫与信息提取 | 北京理工大学 | 已学3/18课时 | 2021年5月18日已结束 | http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg |
| 2...... |
代码:
通过XPATH找元素,和上一题不同,有些值是空的,需要自己赋值:
for _ in range(max_pages):
content = browser.page_source
selector = Selector(text=content)
courses = selector.xpath("//div[@class='m-course-list']/div/div")
data = []
for course in courses:
lis = []
try:
kc = course.xpath(".//span[@class=' u-course-name f-thide']//text()").extract()
except NoSuchElementException:
kc= ""
kc_string = "".join(kc)
try:
school = course.xpath(".//a[@class='t21 f-fc9']/text()").extract_first()
except NoSuchElementException:
school = ""
try:
teacher = course.xpath(".//a[@class='f-fc9']//text()").extract_first()
except NoSuchElementException:
teacher = ""
try:
team = course.xpath(".//a[@class='f-fc9']//text()").extract()
except NoSuchElementException:
team = ""
team_string = ",".join(team)
try:
number = course.xpath(".//span[@class='hot']/text()").extract_first()
except NoSuchElementException:
number = ""
try:
course_time = course.xpath(".//span[@class='txt']/text()").extract_first()
except NoSuchElementException:
course_time = ""
try:
jianjie = course.xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']//text()").extract()
except NoSuchElementException:
jianjie = ""
jianjie_string = ",".join(jianjie)
登录与输入关键词:
driver.find_element(By.XPATH,'//div[@class="unlogin"]//a[@class="f-f0 navLoginBtn"]').click() #登录或注册
sleep(2)
driver.switch_to.frame(driver.find_element(By.XPATH,"//div[@class='ux-login-set-container']//iframe"))
driver.find_element(By.XPATH,'//input[@id="phoneipt"]').send_keys("13531163263") #输入账号
sleep(2)
driver.find_element(By.XPATH,'//input[@placeholder="请输入密码"]').send_keys("123456") #输入密码
sleep(2)
driver.find_element(By.XPATH,'//div[@class="j-power-btn f-cb loginbox"]//a[@id="submitBtn"]').click() #点击登录
sleep(5)
driver.find_element(By.XPATH,'//div[@class="u-baseinputui"]/input[@class="j-textarea inputtxt"]').send_keys("python") #输入要找的课程
sleep(2)
driver.find_element(By.XPATH,'//div[@class="u-search-icon"]/span[@class="u-icon-search2 j-searchBtn"]').click() #点击搜索
sleep(2)
翻页:
try:
next_page_button = browser.find_element(By.CLASS_NAME, 'ux-pager_btn__next')
if next_page_button.is_enabled():
next_page_button.click()
time.sleep(5)
else:
break
except NoSuchElementException:
break
数据库:
def __init__(self):
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mooc", charset="utf8")
self.cursor = self.con.cursor()
def close_up(self):
try:
self.con.commit()
self.con.close()
except Exception as err:
print(err)
def insert_db(self, data):
try:
sql = "INSERT INTO mooccourse (course, school, teacher, team, number, course_time, jianjie) VALUES (%s, %s, %s, %s, %s, %s, %s)"
self.cursor.executemany(sql, data)
except Exception as err:
print(err)
def run(self):
# 启动浏览器
browser = webdriver.Chrome()
url = 'https://www.icourse163.org/'
browser.get(url)
time.sleep(2)
结果:
心得体会:
本次实验通过模拟登录以及搜索关键词进行mooc网站的爬取,通过此次实验,在最开始设置为扫码登录,但是每次都扫码觉得过于繁琐,后来直接模拟账号密码登录;通过此次实验,加深了对selenium与mysql的认识。
作业3:
要求:掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三:安装Flume客户端
任务四:配置Flume采集数据
任务一:Python脚本生成测试数据
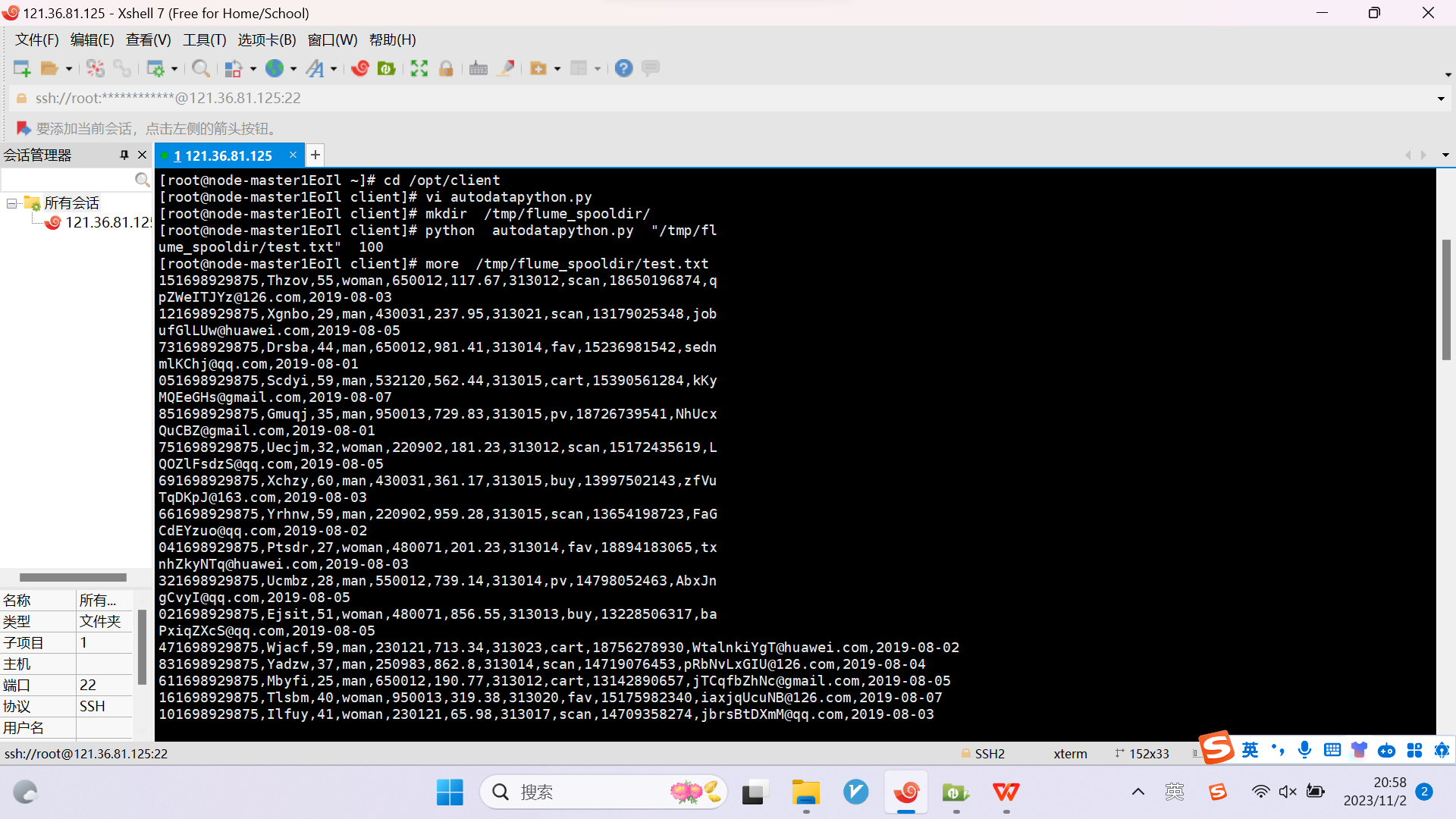
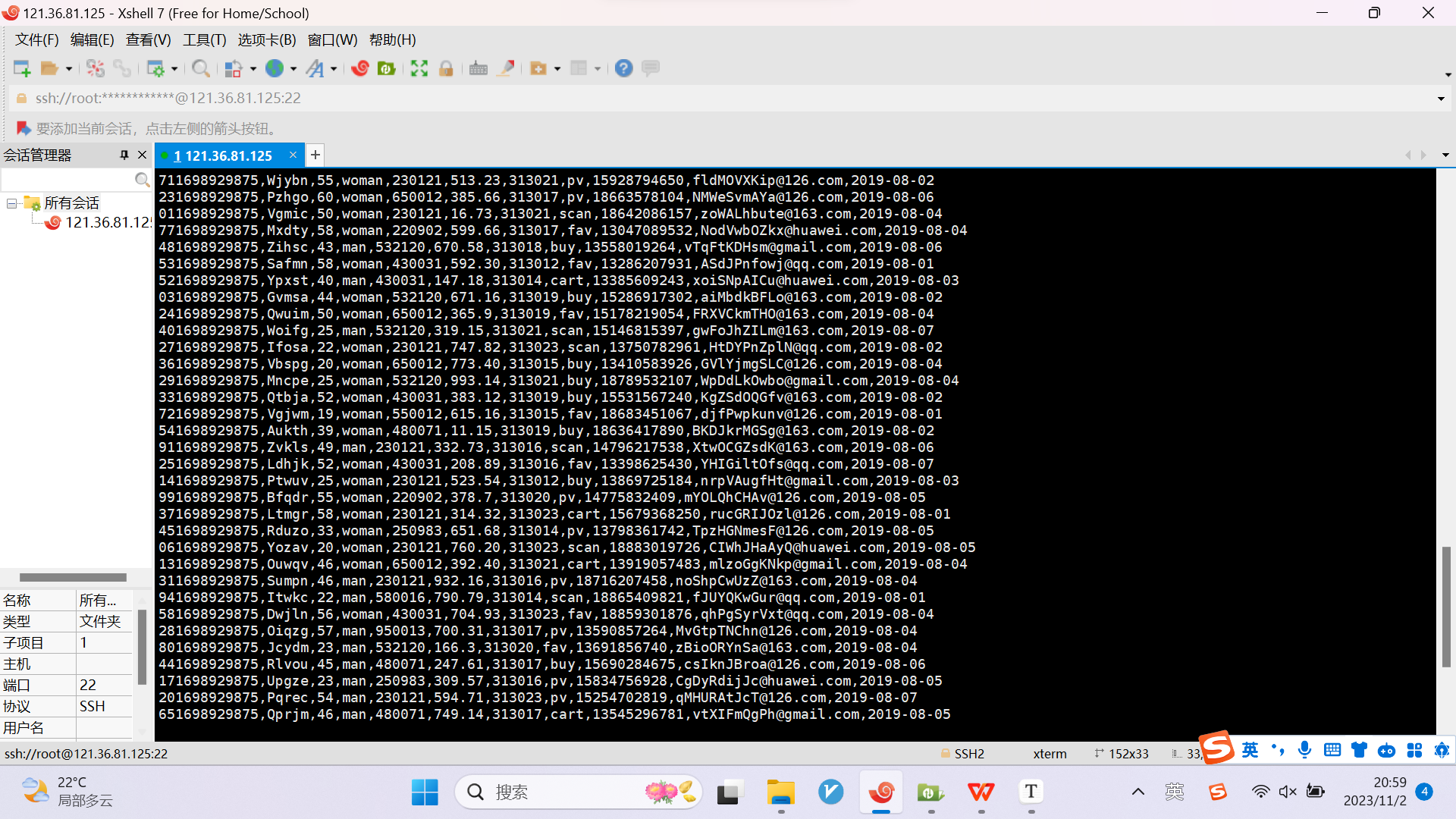
任务二:配置Kafka


任务三:安装Flume客户端
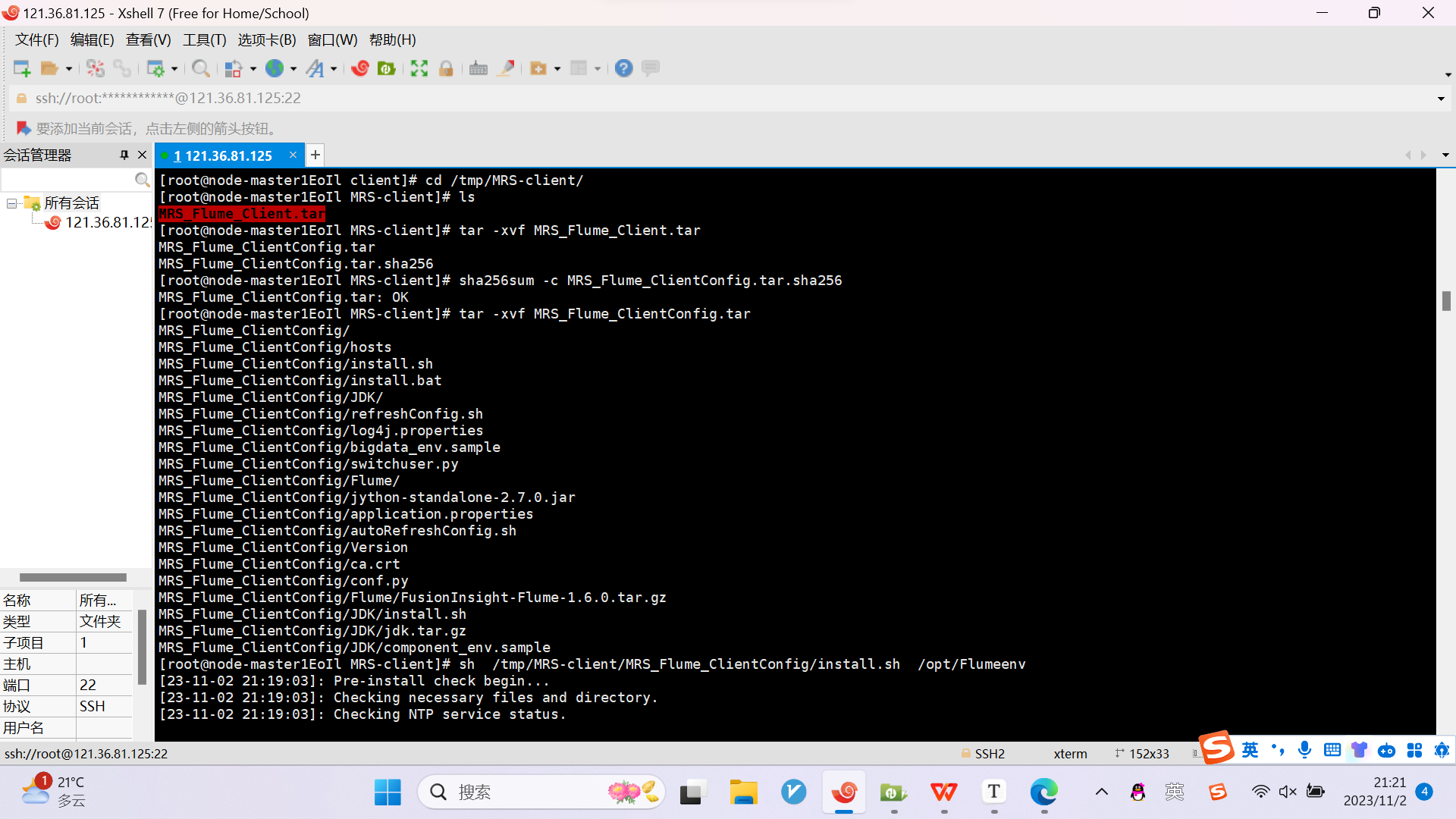
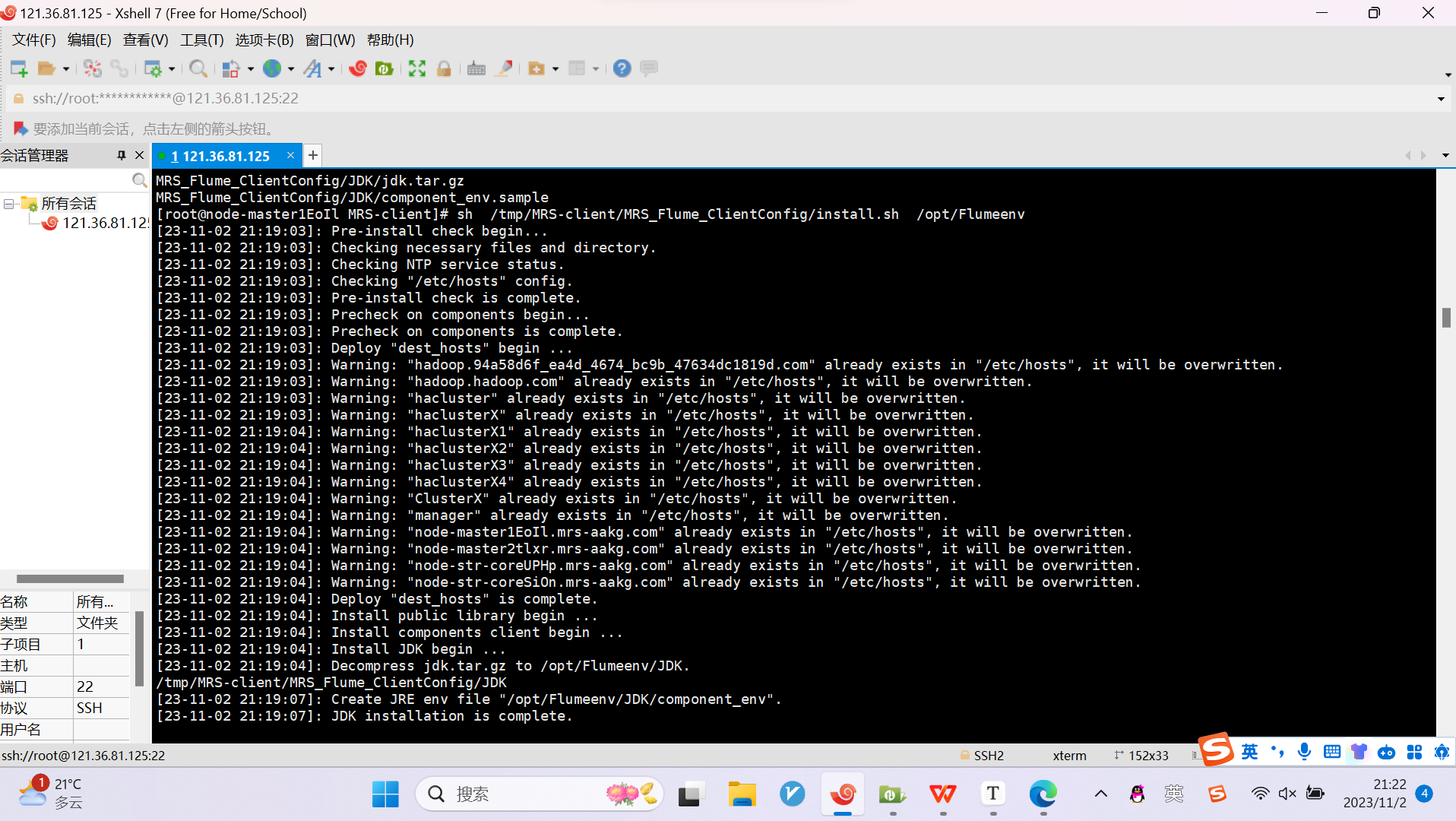

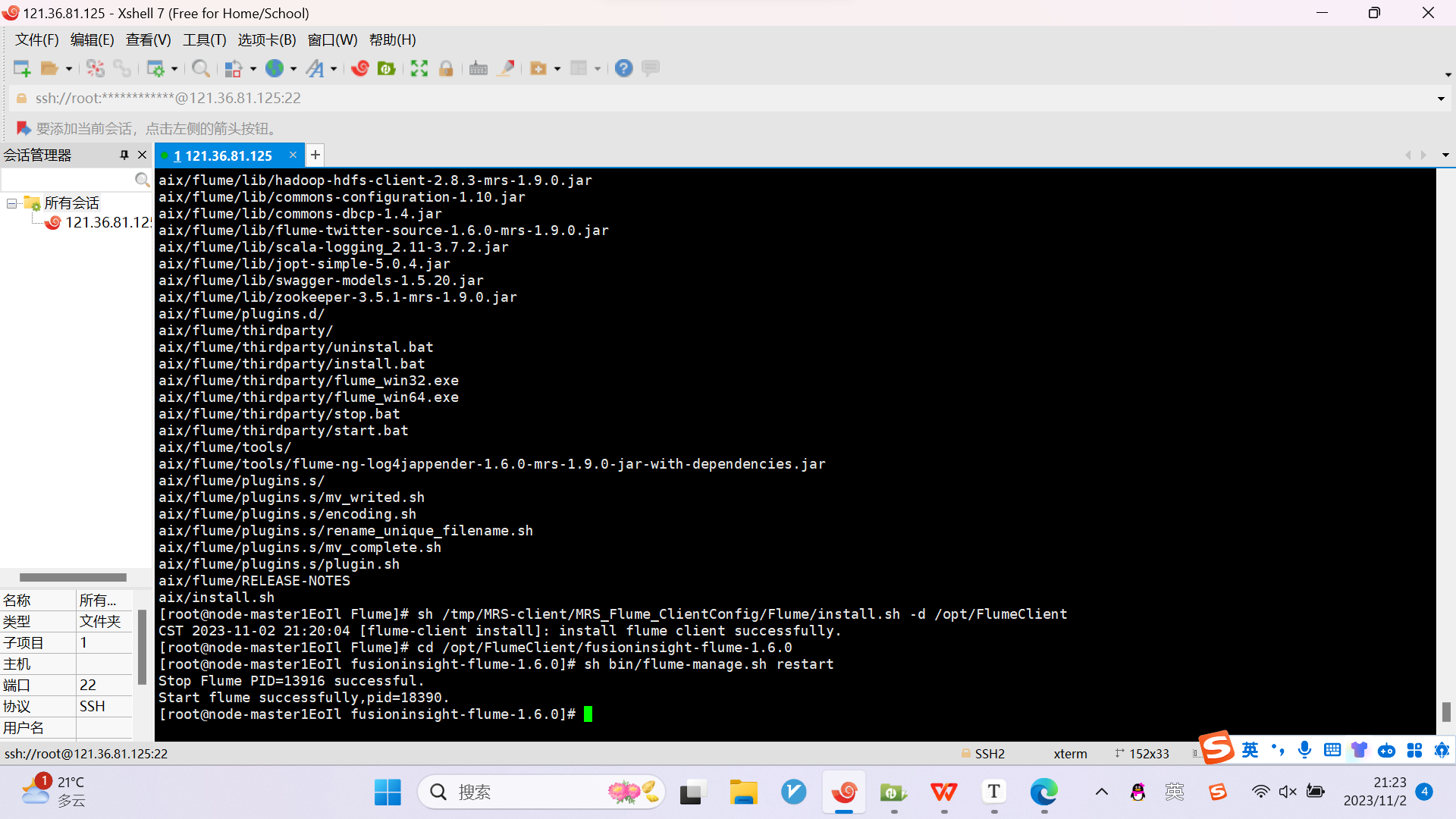
任务四:配置Flume采集数据


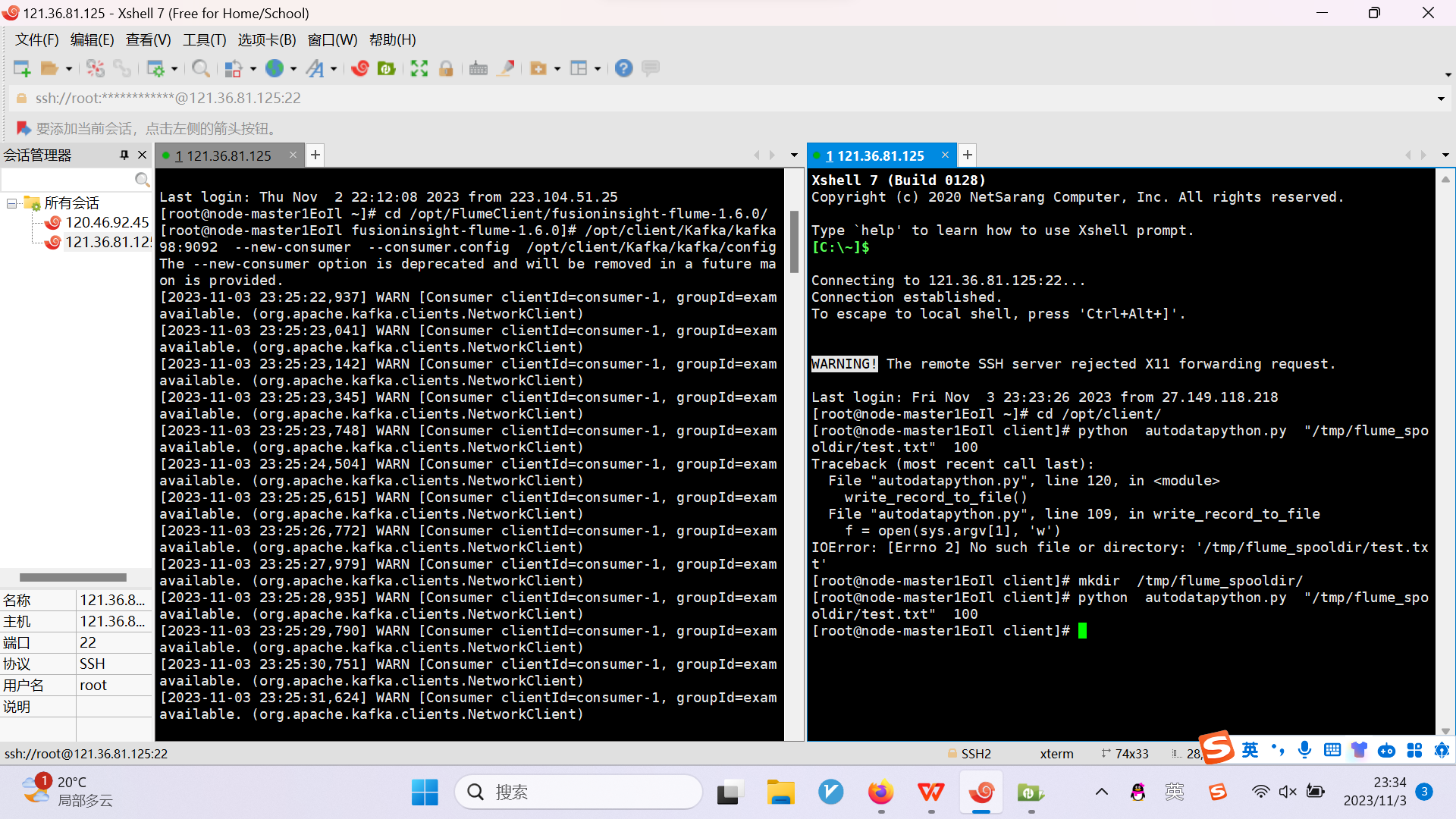
心得体会:
本次实验通过华为云平台与xshell进行实验,了解了Python脚本生成测试数据、配置Kafka、安装Flume客户端、配置Flume采集数据这四个过程,初步了解了云。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号