2023数据采集与融合技术实践作业三
作业①:
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee
1).代码:
单线程:
weather_image.py:
import scrapy
from h1.items import WeatherImagesItem
class WeatherImageSpider(scrapy.Spider):
name = 'weather'
start_urls = ['http://p.weather.com.cn/zrds/index.shtml']
count = 0 # 初始化计数器
def parse(self, response):
urls = response.css('a::attr(href)').re(r'http://p.weather.com.cn/\d\d\d\d/\d\d/\d\d\d\d\d\d\d.shtml')
for url in urls:
if WeatherImageSpider.count == 105: # 当计数器达到105时停止
break
yield response.follow(url, self.parse_image)
def parse_image(self, response):
pics = response.css('img.lunboimgages::attr(src)').extract()
for pic in pics:
if WeatherImageSpider.count == 105: # 当计数器达到105时停止
break
item = WeatherImagesItem()
item['image_url'] = pic
WeatherImageSpider.count += 1 # 计数器加1
yield item
settings.py:
BOT_NAME = "h1"
SPIDER_MODULES = ["h1.spiders"]
NEWSPIDER_MODULE = "h1.spiders"
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.8 Safari/537.36}"
}
ITEM_PIPELINES = {
'h1.pipelines.SaveImagesPipeline': 500,
#'scrapy.pipelines.images.ImagesPipeline': 1,
}
LOG_LEVEL = 'DEBUG'
IMAGES_STORE ='./images'
pipelines.py:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class SaveImagesPipeline(ImagesPipeline):
# 根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['image_url'])
# 进行持久化存储的路径
def file_path(self, request, response=None, info=None):
# 指定图片名称。图片存储目录在配置文件中设置
img_name = request.url.split('/')[-1]
return img_name
def item_completed(self, results, item, info):
# 返回下一个即将被执行的管道类
return item
items.py:
import scrapy
class WeatherImagesItem(scrapy.Item):
image_url = scrapy.Field()
多线程:最开始以为需要通过threads多线程
import scrapy
from h1.items import WeatherImagesItem
import threading
import re
import requests
class WeatherImageSpider(scrapy.Spider):
name = 'weather'
start_urls = ['http://p.weather.com.cn/zrds/index.shtml']
count = 0 # 初始化计数器
thread_lock = threading.Lock()
threads = []
def parse(self, response):
urls = response.css('a::attr(href)').re(r'http://p.weather.com.cn/\d\d\d\d/\d\d/\d\d\d\d\d\d\d.shtml')
for url in urls:
if WeatherImageSpider.count == 105: # 当计数器达到105时停止
break
t = threading.Thread(target=self.parse_image, args=(url,))
t.setDaemon(False)
t.start()
WeatherImageSpider.threads.append(t)
def parse_image(self, url):
response = requests.get(url)
response.raise_for_status()
html = response.text
print(html)
pics = re.findall(r'<img class="lunboimgages" src="([^"]+)"', html)
for pic in pics:
with WeatherImageSpider.thread_lock:
if WeatherImageSpider.count == 105: # 当计数器达到105时停止
break
item = WeatherImagesItem()
item['image_url'] = pic
WeatherImageSpider.count += 1 # 计数器加1
yield item
但一直无法出来结果,后来通过csdn得知,scrapy本来就是异步的,只需要通过将settings.py中的CONCURRENT_REQUESTS的默认值从8改为16或32即可。
结果:
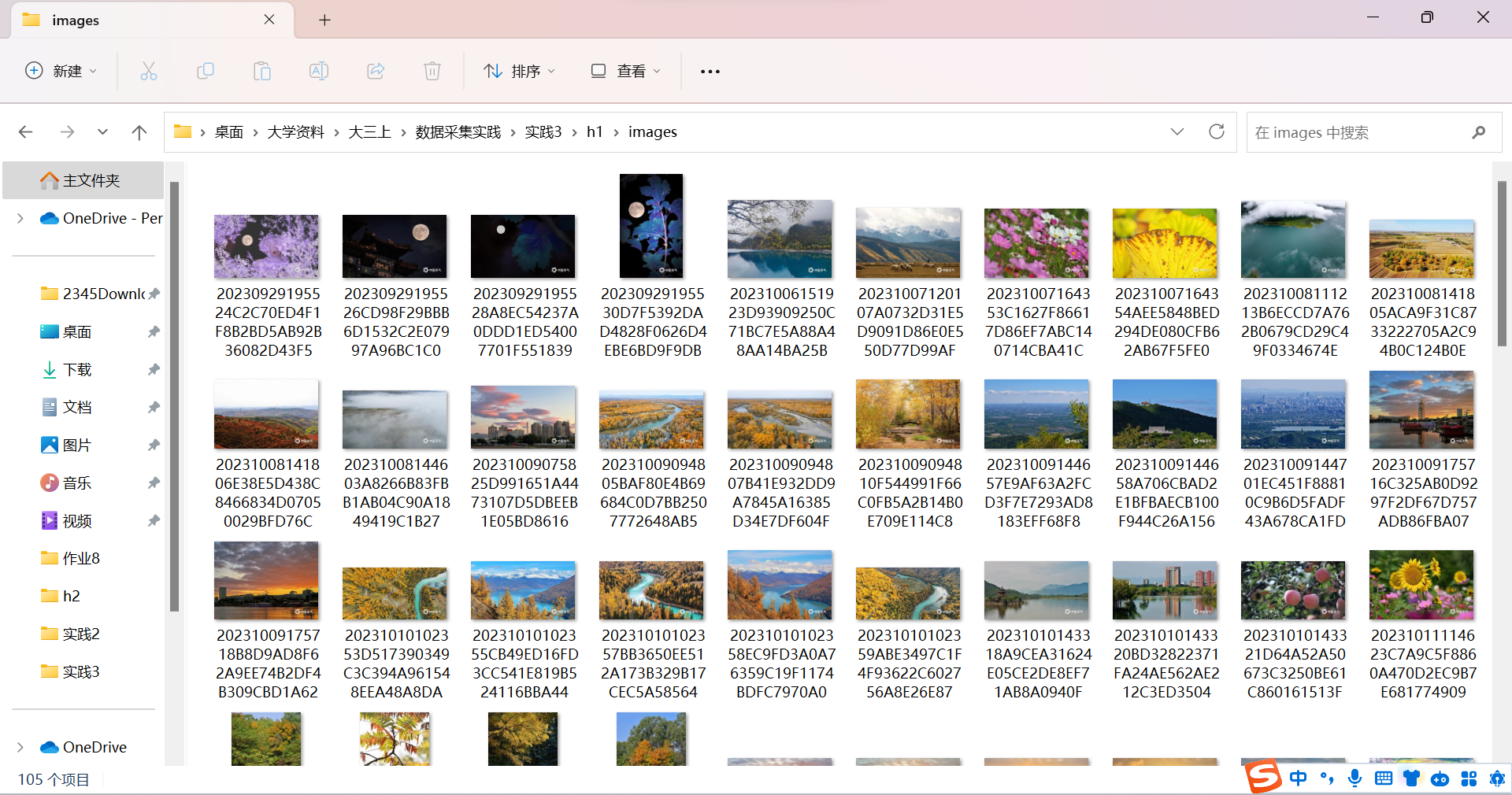
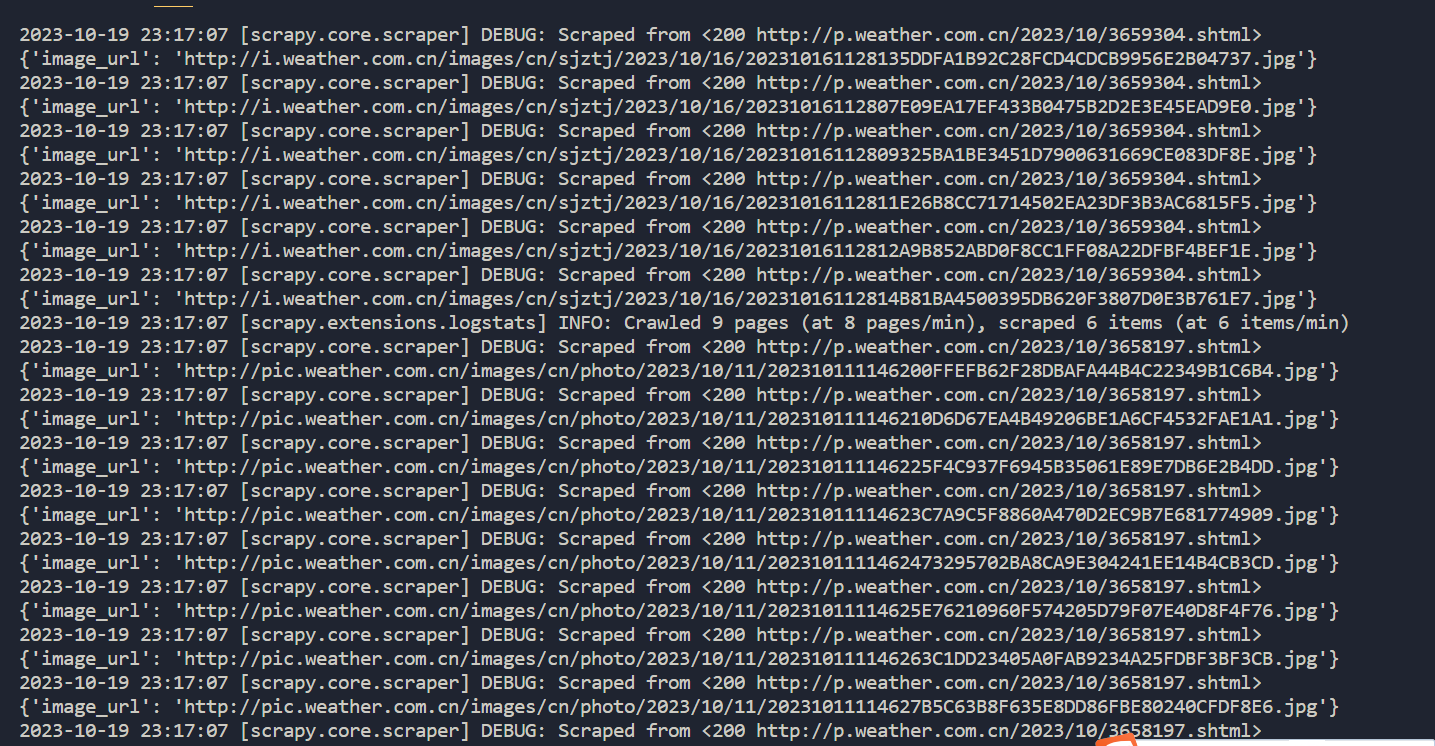
2).心得体会:
这道题要求单线程和多线程爬取图片,了解到scrapy为异步和多线程,对爬取图片、线程和scrapy有了更加深刻地了解。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
-
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55 2…… Gitee文件夹链接
1).代码:
eastmoney.py:
import requests
import scrapy
import json
class EastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
start_urls = ['http://42.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409594985484135052_1697702833397&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697702833398']
page_next_id = 2
def parse(self, response):
json_str = response.text[len('jQuery112409594985484135052_1697702833397('):-1]
json_str = json_str[:-1]
# 解析 JSON 数据
json_data = json.loads(json_str)
items = json_data['data']['diff']
for item in items:
stock_item = {
"股票代码": item['f12'],
"股票名称": item['f14'],
"最新报价": item['f2'],
"涨跌幅": item['f3'],
"涨跌额": item['f4'],
"成交量": item['f5'],
"成交额": item['f6'],
"振幅": item['f7'],
"最高": item['f15'],
"最低": item['f16'],
"今开": item['f17'],
"昨收": item['f18'],
}
yield stock_item
# 处理分页
if self.page_next_id <= 5:
next_page_url = f'http://42.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409594985484135052_1697702833397&pn={self.page_next_id}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697702833398'
self.page_next_id += 1
yield response.follow(next_page_url, self.parse)
settings.py:
BOT_NAME = "h2"
SPIDER_MODULES = ["h2.spiders"]
NEWSPIDER_MODULE = "h2.spiders"
ROBOTSTXT_OBEY = False #之前爬取json时改为了False,要改回来
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.8 Safari/537.36}"
}
ITEM_PIPELINES = {
'h2.pipelines.H2Pipeline': 300, # 根据优先级设置适当的值
}
ITEM_PIPELINES = {
'h2.pipelines.H2Pipeline': 300,
}
pipelines.py:
import pymysql
class H2Pipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="db", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened = True
self.count = 0 # 初始化count属性
except Exception as err:
print(err)
self.opened = False
self.cursor.execute(create_table_query)
self.con.commit()
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute(
"insert into stocks (id, StockNo, StockName, StockQuote, Changerate, Chg, Volume, Turnover, StockAmplitude, highest, lowest, Pricetoday, PrevClose) values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",
(self.count+1, item["股票代码"], item["股票名称"], item["最新报价"], item["涨跌幅"], item["涨跌额"], item["成交量"], item["成交额"], item["振幅"], item["最高"], item["最低"], item["今开"], item["昨收"]))
self.count += 1
except Exception as err:
print(err)
return item
items.py:
import scrapy
class H2Item(scrapy.Item):
序号 = scrapy.Field()
股票代码 = scrapy.Field()
股票名称 = scrapy.Field()
最新报价 = scrapy.Field()
涨跌幅 = scrapy.Field()
涨跌额 = scrapy.Field()
成交量 = scrapy.Field()
成交额 = scrapy.Field()
振幅 = scrapy.Field()
最高 = scrapy.Field()
最低 = scrapy.Field()
今开 = scrapy.Field()
昨收 = scrapy.Field()
ps:需要先在mysql里创建一个db数据库,然后在db里面创建一个stocks的表
CREATE TABLE stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
StockNo VARCHAR(255),
StockName VARCHAR(255),
StockQuote FLOAT,
Changerate FLOAT,
Chg FLOAT,
Volume FLOAT,
Turnover FLOAT,
StockAmplitude FLOAT,
highest FLOAT,
lowest FLOAT,
Pricetoday FLOAT,
PrevClose FLOAT
)
结果:
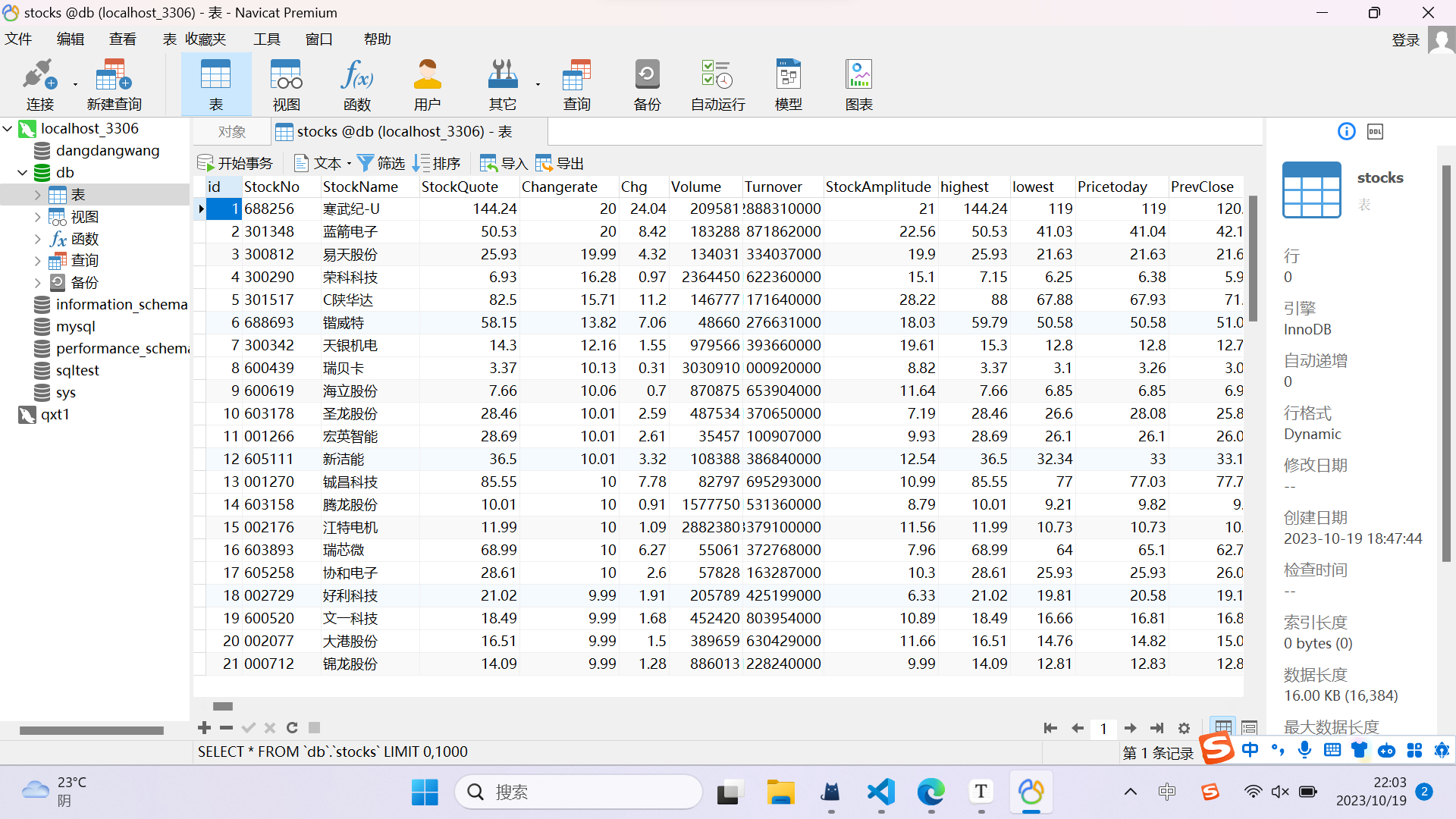
2).心得体会:
最开始使用Xpath一直无法输出结果,后来知道是动态网页,只能通过抓包的链接,此次作业要存储在mysql数据库中,最燃有学过,但是没有亲自实践过,第一次使用也遇到了不小的困难,需要安装MySQL以及创建数据库、表,插入数据等,最后鸡精挫折才完成存储。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:****中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
Gitee文件夹链接
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
bank.py:
import scrapy
from h3.items import H3Item
from bs4 import UnicodeDammit
class BankSpider(scrapy.Spider):
name = "bank"
start_urls = ['https://www.boc.cn/sourcedb/whpj/index.html']
def parse(self, response):
rows = response.xpath('//tr[position()>1]')
for row in rows:
item = H3Item()
item['Currency'] = row.xpath('.//td[1]/text()').get()
item['TBP'] = row.xpath('.//td[2]/text()').get()
item['CBP'] = row.xpath('.//td[3]/text()').get()
item['TSP'] = row.xpath('.//td[4]/text()').get()
item['CSP'] = row.xpath('.//td[5]/text()').get()
item['Time'] = row.xpath('.//td[8]/text()').get()
yield item
settings.py:
BOT_NAME = "h3"
SPIDER_MODULES = ["h3.spiders"]
NEWSPIDER_MODULE = "h3.spiders"
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.8 Safari/537.36}"
}
ITEM_PIPELINES = {
'h3.pipelines.H3Pipeline': 300,
}
pipelines.py:
from itemadapter import ItemAdapter
import pymysql
class H3Pipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123456",db="db",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from ICBC")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute(
"insert into ICBC(ID,Currency,TBP,CBP,TSP,CSP,Time) values(%s,%s,%s,%s,%s,%s,%s)",
(self.count+1,item["Currency"], item["TBP"], item["CBP"], item["TSP"], item["CSP"], item["Time"]))
self.count += 1
except Exception as err:
print(err)
return item
items.py:
import scrapy
class H3Item(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
ps:需要先在mysql里创建一个db数据库,然后在db里面创建一个icbc的表
CREATE TABLE stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
TBP FLOAT,
CBP FLOAT,
TSP FLOAT,
CSP FLOAT,
Time DATA
)
结果:
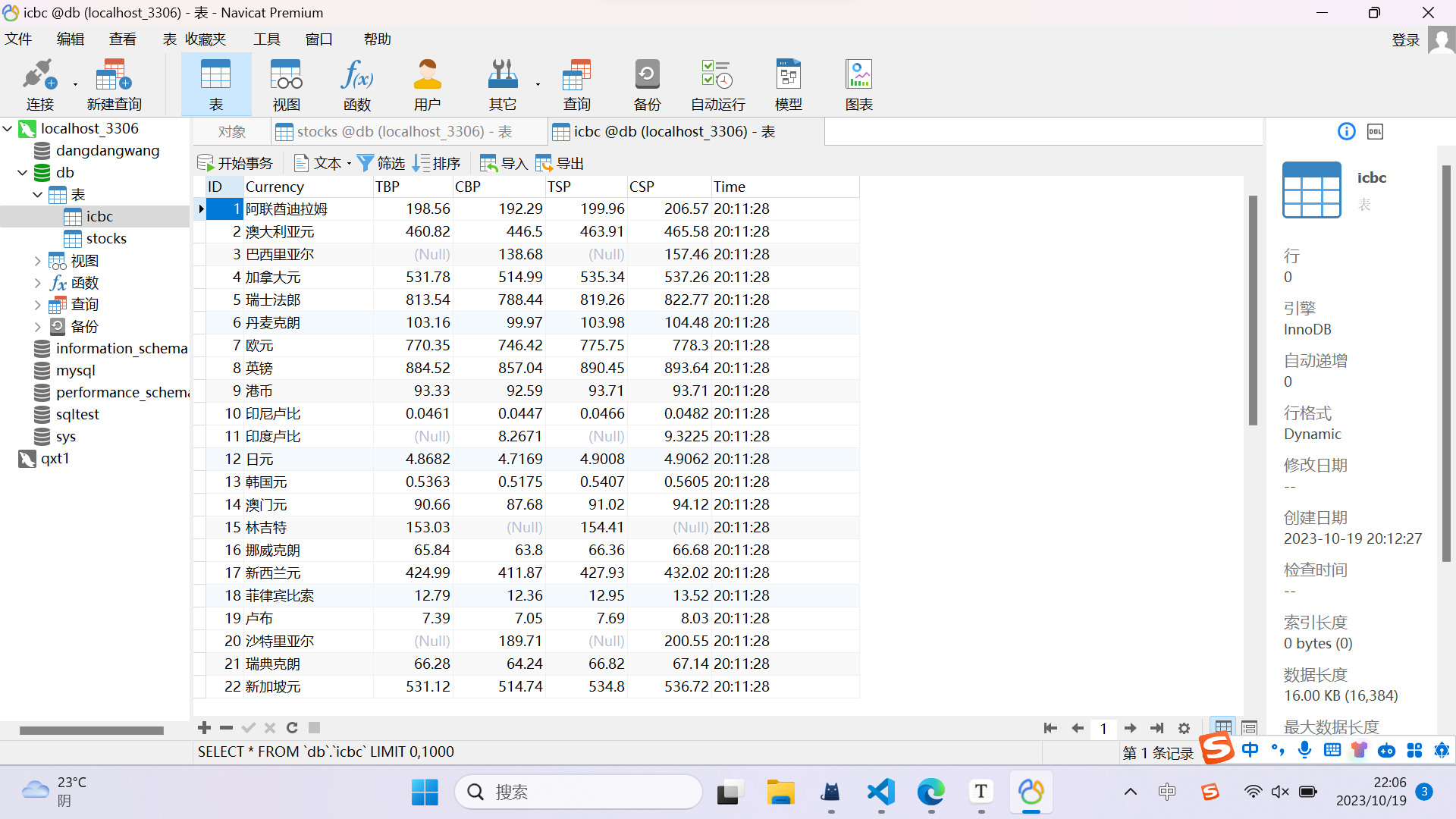
2).心得体会:
这道题与作业2差不多,但这道题可以直接通过Xpath进行信息的提取,但最开始把路径想得较为复杂,没有结果的输出,后来简化了之后反而可以了,因为有了第二题,这道题的存储在MySQL中顺利了许多。通过此次作业,加深了对scrapy框架与mysql的认识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号