
2023数据采集与融合技术实践作业一
作业①
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
| *排名* | *学校名称* | *省市* | *学校类型* | *总分* |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
爬虫高校排名
1).代码:
import urllib.request
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 发送HTTP请求并获取网页内容
response = urllib.request.urlopen(url)
html = response.read()
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(html, 'html.parser')
# 定位到包含大学排名信息的表格
table = soup.find('table', class_='rk-table')
# 获取表格中的每一行数据
rows = table.find_all('tr')
# 打印表头
print("排名\t学校名称\t省市\t学校类型\t总分")
# 遍历每一行数据,打印TOP 5的大学排名信息
for row in rows[1:10]: # 跳过表头,只打印前5行
# 获取每一行中的列数据
cols = row.find_all('td')
# 提取排名、学校名称、省市、学校类型和总分
rank = cols[0].text.strip()
name = cols[1].text.strip()
location = cols[2].text.strip()
type = cols[3].text.strip()
score = cols[4].text.strip()
# 打印排名信息
print(rank + "\t" + name + "\t" + location + "\t" + type + "\t" + score)
结果:
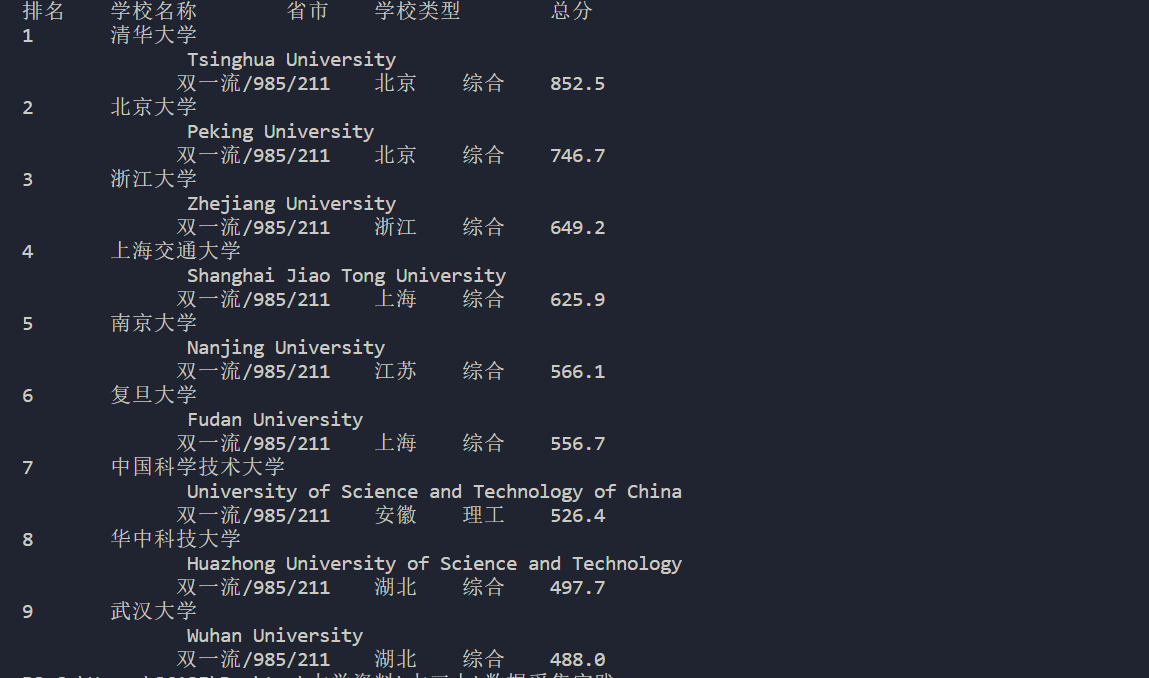
2).心得体会:
本次实验是第一次进行自主爬虫,爬取的是高校的名称、省市、学校类型以及总分,通过获取网页的内容、解析、定位到标签并进行打印,最后通过按照格式输出结果。第一次进行爬虫较为容易,标签较为容易找同时网页较为容易爬取。
作业②
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| *序号* | *价格* | *商品名* |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
爬取商城
1).代码:
import requests
from bs4 import BeautifulSoup
import re
import urllib3
import urllib.request
url ="http://search.dangdang.com/?key=python%20%C5%C0%B3%E6&act=click"
prices = []
titles = []
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding #把获取到的页面信息 替换成utf-8信息,这样就不会乱码
html = r.text.encode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
ul_ele = soup.find('div', id='search_nature_rg')
li_ele = ul_ele.find_all('li')
title_regex = r'<a.*?dd_name="单品标题".*?>(.*?)</a>'
price_regex = r'<p class="price">.*?<span class="search_now_price">(.*?)</span>'
# 在<li>标签下寻找商品名和价格
for li in li_ele:
title_match = re.search(title_regex, str(li))
if title_match:
title = title_match.group(1)
soup = BeautifulSoup(title, 'html.parser')
title= soup.get_text() # 使用 BeautifulSoup 的 get_text() 方法获取文本内容
titles.append(title)
price_match = re.search(price_regex, str(li))
if price_match:
price = price_match.group(1)
prices.append(price)
title_price = "{:^10}\t{:^10}\t{:^20}"
print(title_price.format("序号", "价格","商品名称"))
count=0
for i in range(len(titles)):
count = count + 1
print(title_price.format(count,prices[i],titles[i]))
结果:
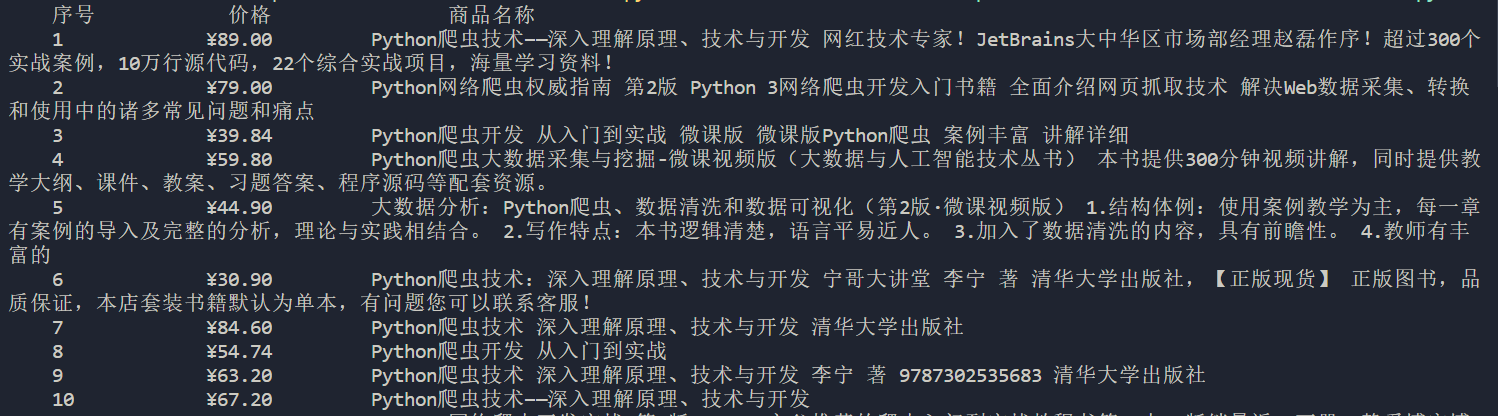
2).心得体会:
此次作业最开始是爬虫淘宝,但由于淘宝具有很强的反爬机制,每次爬虫需要进行登录验证,后来换为京东,尝试了一天发现仍然爬不下来,最后发现当当不需要登录就可以进行爬取,最后通过检查当当的标签进行爬取。但一开始爬取还是有点难度,需要通过找标签及以下的标签,最终找到商品的名字与价格对应的标签
作业③
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
爬取定向网页
1).代码:
import urllib.request
import re
from bs4 import BeautifulSoup
def get_html(url):
res = urllib.request.urlopen(url)
html = res.read()
return html
def get_picture(html):
mysoup = BeautifulSoup(html, 'html.parser')
pictures = mysoup.findAll('img')
img_re = re.compile(r'src="(.*?)"')
for i in range(len(pictures)):
picture = str(pictures[i])
img_url = re.findall(img_re, picture)
if img_url:
img_url = img_url[0]
img_url = url1 + img_url
with open(r"C:\Users\86135\Desktop\大学资料\大三上\数据采集实践\%s.jpg" % (i+1), 'wb') as f:
try:
pic_url = get_html(img_url)
f.write(pic_url)
except :
print("URLError")
if __name__ == '__main__':
url="https://xcb.fzu.edu.cn/info/1071/4481.htm"
url1 = 'https://www.fzu.edu.cn/'
html = get_html(url)
get_picture(html)
结果

2).心得体会
此次作业爬取的是定向网页的图片,通过找到网页的图片标签然后通过正则表达式进行提取,但是由图图片前面需要加上'https://www.fzu.edu.cn/'这个前缀才能保存成功。
总结
本次作业的3次小作业都是通过urllib与正则表达式进行爬取,步骤都差不多,唯一不同的是网页的标签以及各个提取各个标签下内容的正则表达式。通过此次实验加深了对bs、request、urllib、re等的理解,并且通过此次作业简单理解了爬虫的框架。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号