JAVA 利用反射自定义数据层框架
之前的随笔一直都在介绍c#,主要公司最近的业务都是做桌面程序,那么目前c#中的WPF肯定是我做桌面程序的不二之选,做了半年的WPF,也基本摸清了c#写代码的套路和规则(本人之前是两年多的JAVA开发者,除了大学没有接触过任何c#的编程),我在大三开始搞工作室,接网站的单子,最难过的时候,一个人要写前台后台,说实话是JAVA把我引上了这条程序员的"不归路",我在南京上的一所985大学,当然大家也能猜到,南京总共就两个985,我的专业是网络工程,我是实在没有兴趣,唯独对JAVA编程感兴趣,我记得那时候我们的Java老师是一个浙大的年轻硕士,上了一学期从没写过一行代码,我就自己买书自学,直到现在我在苏州一家高新技术公司做软工,JAVA给我生活带来了色彩,也养活了我。
说这么多,是因为今天逛园子看见一个7年园龄的.net开发者,在一篇关于servlet的文章下,直言JAVA很简单,我是有点不服气的,但是我也没有反驳,毕竟人家7年园龄,我17年才毕业。
今天开始会把我这接近三年的JAVA经验,和死啃的技术文档所获得的心得分享出来,我这个人写文章不是很厉害,所以将就看看吧。
反射我就不详细解释了,不是很了解的可以看看园子里关于反射的知识贴。
一、反射的概述
#二、框架思路
获取数据库数据,反射获取类模型的字段,以及set方法,通过invoke我们的set方法,将数据set到类模型对象之中,将行数据作为对象返回出来,多条数据则返回对象集合
#三、工具类,辅助类编写
1.首先是封装类的对象,作用是将类的字段和方法都存储到两个数组之中,拆分模型类

package com.warrenwell.dao.util.bean; import java.lang.reflect.Field; import java.lang.reflect.Method; /** * 类的信息,用于封装类的结构 * @author Administrator * */ public class ClassInfo { //属性 private Field[] fields; //方法 private Method[] methods; public Field[] getFields() { return fields; } public void setFields(Field[] fields) { this.fields = fields; } public Method[] getMethods() { return methods; } public void setMethods(Method[] methods) { this.methods = methods; } }
2.有了模型类的封装类,自然就有数据库列的封装类,设定两个字段一个是列类型,一个是列名字,这样之后只要一个此类的数组就能表示一个表的结构
package com.warrenwell.dao.util.bean; /** * 列数据 * @author Administrator * */ public class ColumnData { private String columnName; private int columnType; public String getColumnName() { return columnName; } public void setColumnName(String columnName) { this.columnName = columnName; } public int getColumnType() { return columnType; } public void setColumnType(int columnType) { this.columnType = columnType; } }
3.接下来就是数据库的连接等工具类的编写,我把数据库的配置写在了配置文件,下面是我的DaoUtil中的数据库工具类的编写以及配置文件的书写方式,配置文件名字为DBConfig,在src路径下。获取连接等加锁是出于安全的考虑
private static String driver; private static String url; private static String user; private static String password; protected static int size; private static DataSource dataSource; /** * 加载配置文件 */ static{ ResourceBundle bundle = ResourceBundle.getBundle("DBConfig"); System.out.println("加载了配置文件"); //解析配置文件中的数据 driver = bundle.getString("driver"); user = bundle.getString("user"); password = bundle.getString("password"); url = bundle.getString("url"); try { size = Integer.parseInt(bundle.getString("pageSize")); } catch (NumberFormatException e) { // TODO Auto-generated catch block e.printStackTrace(); System.out.println("size格式非法!"); } } /** * 获取数据库连接 * @return */ public static synchronized Connection getConnection(){ Connection con = null; try { //驱动加载 Class.forName(driver); //获取连接对象 con = DriverManager.getConnection(url,user,password); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return con; } /** * 关闭数据库对象 * @param con 连接 * @param stmt 处理器 * @param rs 结果集 */ public static synchronized void close(Connection con, Statement stmt, ResultSet rs){ try { if(rs != null){ rs.close(); //rs = null; } if(stmt != null){ stmt.close(); //stmt = null; } if(con != null){ //如果该connection对象是由数据池创建的,其close方法表示将连接放回连接池 //如果该Connection对象是由数据库驱动提供的,close方法表示断开数据库连接,并清除开销的资源 con.close(); //con = null; } } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
driver=oracle.jdbc.driver.OracleDriver
url=jdbc:oracle:thin:@192.168.3.100:1521:orcl
user=system
password=niit
pageSize=4
4.我们从数据库查询到结果集就要被解析封装成列数据的数组了,相当于解析出结果集的结构
/** * 解析元数据 * @param data * @return */ public static ColumnData[] parseResultSetMetaData(ResultSetMetaData data){ ColumnData[] columnData = null; if(data != null){ try { columnData = new ColumnData[data.getColumnCount()]; for(int i = 0; i < data.getColumnCount(); i++){ ColumnData column = new ColumnData(); //封装列的名称 column.setColumnName(data.getColumnName(i+1)); //封装列的类型 column.setColumnType(data.getColumnType(i+1)); columnData[i] = column; } } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } return columnData; }
映射实体类也要被解析到类模型之中,说白了就是将实体类的字段和方法进行解析,以便之后使用,这里我们需要考虑到有的实体类可能是继承自父类的,我们这里需要反射的时候都获取到就可能出现重复的字段或者方法,所以我们选择set集合存储这些字段和方法,利用的就是set集合的自动去重复,之后再将set集合转为数组
/** * 解析类 * @param classObj * @return */ public static ClassInfo parseClass(Class classObj){ //存储所有属性的集合 //方式一 Set<Field> setF = new HashSet<Field>(); for(Field f : classObj.getDeclaredFields()){ setF.add(f); } for(Field f : classObj.getFields()){ setF.add(f); } //存储所有方法 Set<Method> setM = new HashSet<Method>(); for(Method m : classObj.getDeclaredMethods()){ setM.add(m); } for(Method m : classObj.getMethods()){ setM.add(m); } //封装类的属性和方法 ClassInfo info = new ClassInfo(); Field[] arrayF = new Field[setF.size()]; //将集合转换成数组 setF.toArray(arrayF); Method[] arrayM = new Method[setM.size()]; setM.toArray(arrayM); info.setFields(arrayF); info.setMethods(arrayM); return info; } /** * 首字母大写转换 * @param str * @return */ public static String upperFirstWorld(String str){ return str.substring(0,1).toUpperCase().concat(str.substring(1)); }
到了这里所有的辅助类和工具类就都完成了,我们就可以去编程我们的数据的增删改查的框架了
#四、核心框架代码编写
1.增删改的数据框架,没有什么需要反射的,主要是做到sql注入的时候,我们把参数都写到一个object数据,因为我们也不知道参数的个数和参数的类型
public static synchronized void executeUpdate(String sql,Object[] params){ Connection con = DaoUtil.getConnection(); PreparedStatement pstmt = null; if(con != null){ try { pstmt = con.prepareStatement(sql); //注入参数 if(params != null){ for(int i = 0; i < params.length; i++){ if(params[i].getClass() == String.class){ pstmt.setString(i+1, params[i].toString()); } else if(params[i].getClass() == int.class || params[i].getClass() == Integer.class){ pstmt.setInt(i+1, (Integer)params[i]); } //....else if() 判断各种事情类型情况 else{ pstmt.setObject(i+1, params[i]);//其实只要这句话上面的判断就不需要了 } } //执行增删改 pstmt.executeUpdate(); } } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally{ DaoUtil.close(con, pstmt, null); } } }
2.这也是重点来了,查询数据,我这里以查询多行数据为例,从而返回的应该是实体映射类对象的集合下图是我们数据库中表的大概结构
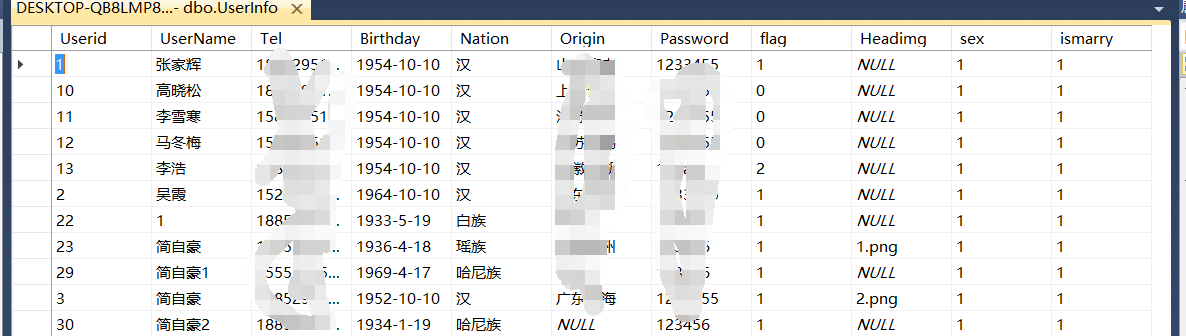
从而对应的实体类应为
package com.warrenwell.pojo; /** * 数据持久层 * @author 123 *此处为用户类 */ public class User { private String userName; private int userid; private String tel; private String birthday; private String nation; private String origin; private String password; private int flag; private String headimg; private int ismarry; private int sex; public int getIsmarry() { return ismarry; } public void setIsmarry(int ismarry) { this.ismarry = ismarry; } public int getSex() { return sex; } public void setSex(int sex) { this.sex = sex; } public String getHeadimg() { return headimg; } public void setHeadimg(String headimg) { this.headimg = headimg; } public String getUserName() { return userName; } public void setUserName(String userName) { this.userName = userName; } public int getUserid() { return userid; } public void setUserid(int userid) { this.userid = userid; } public String getTel() { return tel; } public void setTel(String tel) { this.tel = tel; } public String getBirthday() { return birthday; } public void setBirthday(String birthday) { this.birthday = birthday; } public String getNation() { return nation; } public void setNation(String nation) { this.nation = nation; } public String getOrigin() { return origin; } public void setOrigin(String origin) { this.origin = origin; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public int getFlag() { return flag; } public void setFlag(int flag) { this.flag = flag; } }
我们需要获取到实体类所拥有的属性和set方法,再去解析结果集的结构,依次比较实体类中有的字段在数据库之中也有的,那么就是我们所需要的,从而invoke该实体类的set方法,将值set到实体类的对应字段之中。
/** * 通用的数据查询方法 * @return 多行数据 */ public static synchronized <T> List<T> executeQueryForMultipl(String sql, Object[] params, Class<T> classObj){ List<T> list = new ArrayList<T>(); T t = null; Connection con = DaoUtil.getConnection(); PreparedStatement pstmt = null; ResultSet rs = null; if(con != null){ try { pstmt = con.prepareStatement(sql); if(params != null){ //循环注入参数 for(int i = 0; i < params.length; i++){ pstmt.setObject(i+1, params[i]); } } //执行查询 rs = pstmt.executeQuery(); //解析结果集的数据结构 ColumnData[] data = DaoUtil.parseResultSetMetaData(rs.getMetaData()); //解析映射类的结构 ClassInfo info = DaoUtil.parseClass(classObj); //读取结果集 while(rs.next()){ //实例化 t = classObj.newInstance(); //每列的值 Object value = null; //根据结果集的数据结构获取每个列的数据 for(int i = 0; i < data.length; i++){ ColumnData column = data[i]; //判断映射类中是否存在对应的属性 for(Field f : info.getFields()){ if(f.getName().equalsIgnoreCase(column.getColumnName())){ //判断映射类是否存在该属性对应的setter方法 for(Method m : info.getMethods()){ if(m.getName().equals("set"+DaoUtil.upperFirstWorld(f.getName()))){ if(f.getType() == Integer.class || f.getType() == int.class){ value = rs.getInt(i+1); } else if(f.getType() == Double.class || f.getType() == double.class){ value = rs.getDouble(i+1); } else if(f.getType() == String.class){ value = rs.getString(i+1); } else if(f.getType() == Timestamp.class){ value = rs.getTimestamp(i+1); } //如果方法存在则invoke执行 //System.out.println(m.getName()+"\t"+value); m.invoke(t, value); break; } } break; } } }//end-for list.add(t); }//end-while } catch (IllegalArgumentException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (InstantiationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IllegalAccessException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (InvocationTargetException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally{ DaoUtil.close(con, pstmt, rs); } } return list; }
以后我们在Dao之中只需要调用我们的核心方法即可,如下图:
public class UserDao { public User findUserById(int userId){ return DaoHandle.executeQueryForSingle("select * from users where userid=?", new Object[]{userId}, User.class); } public void saveUser(User user){ DaoHandle.executeUpdate("insert into users values(userid.nextval,?,?,?,?,?)", new Object[]{user.getUserName(),user.getUserPwd(),user.getHead(),user.getRegTime(),user.getSex()}); } public User findUserByName(String userName){ return DaoHandle.executeQueryForSingle("select * from users where username=?", new Object[]{userName}, User.class); } }
我们的数据层框架就会把结果依次的映射到对象中,并且返回出来。
单行和分页查询大家可以去试试,我这里只是提供了多行数据返回对象集合的代码。希望大家工作愉快,需要源码的dd我。拜拜!
#五、源代码地址



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义