

一、实现规格所采取的设计策略
整体策略:先把所有规格整个读一遍,提前想好自己可能会用到哪些算法,以便在实现的时候采用合适的容器和实现方式。
第九次作业
通读一遍之后感觉除了查询关系需要进行优化,其余的操作直接对照规格实现就可以了。我最终使用常规的并查集来实现关系的查询,其他的操作均使用Arraylist和循环进行朴素实现。
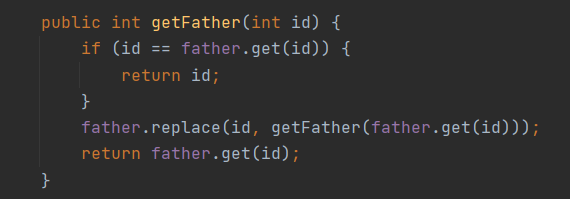
↑非常经典的朴素并查集
第十次作业
保留了第九次作业中的并查集。读完所有规格后,感觉时间复杂度高的操作主要是对group求平均值和sum的那几个操作。当时想的是,把On^2的操作均摊到O1的操作上,就能让所有的操作复杂度讲到On,也就应该不会超时了······其他规格就直接用Arraylist和循环偷懒了。写完之后算了算复杂度,看着2s的cpu时间,感觉应该不会超时就没管了(忘了这是Java)。
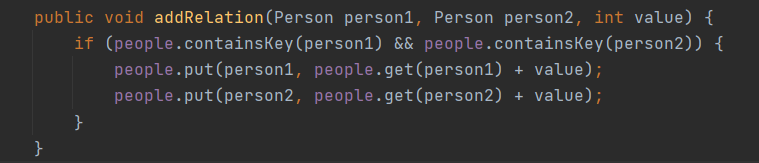
↑在每次改变关系和人的时候就处理sum,来实现单一操作复杂度的平摊
第十一次作业
发现多了一个最短路,显然这就是最耗时的操作了。没想出如何处理动态的人和边,就直接用dijkstra的堆优化写了,估摸着能跑完。其他的规格里,能用HashMap优化的都尽可能进行了优化。
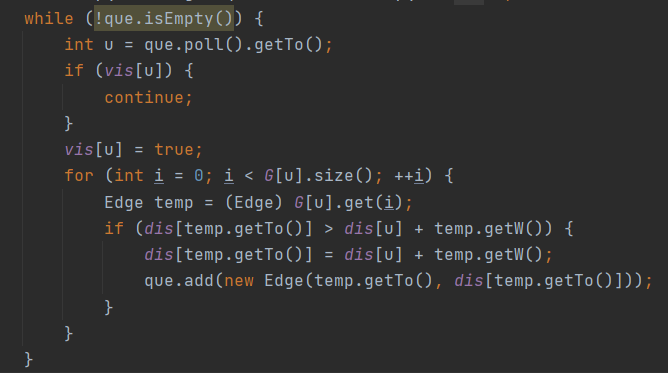
↑dijkstra的堆优化
设计测试的方法和策略
并没有尝试基于JML规格进行测试。
前两次作业没进行太多的测试,在第二次中发现自己没注意到1111的问题···于是在第三次中选择和其他人进行对拍,来检测有无题意理解相关问题。跑了相当数量的随机数据,感觉就应该没啥问题了。
尝试过JUnit进行测试,但感觉意义不大,因为查不出题意理解相关错误。构造一些测试样例似乎就能达到与其相同的效果。
有关容器选择
一开始没想太多与性能相关的事情,就直接用Arraylist和循环来实现大多数的操作。后来第二次作业被卡了0.1s之后,发觉应该把优化做到位,就想起了HashMap这个容器。
以前写c代码的经历,让我总是习惯去选择更简便的方式来实现功能。后来意识到这是Java,具有奇怪的运行速度和非常好用的各种容器如HashMap等,而且根本不用自己去手动实现。于是在第三次作业中,我把几乎所有Arraylist都用HashMap、PriorityQueue这类高效容器代替。毕竟是不用自己手动造轮子,多用几个也不会浪费太多时间来改代码,就很不错。
性能问题
第二次作业中,我根据c的复杂度估计方法来计算,感觉应该不会超时,结果最后超时了0.1-0.6秒不等。debug的时候改了一个HashMap,运行时间就缩短到了一半···实话实说,Java的时间复杂度估计有点让我摸不着头脑。
避免性能问题,个人觉得主要就是要保证单一操作不会有过高的时间复杂度(如n^2)。可以通过使用高效容器如HashMap、PriorityQueue来解决,有的也可以通过复杂度均摊的方式来降低单一操作的复杂度。
架构设计
整体上依照JML规格进行实现,没有太多变化。
前两次作业由于仅存在无向关系的查询,因此并没有建图,直接采用并查集来完成;最后一次作业中,每一次查询时都构建了一个无向图,并用单源最短路径算法来求解。由于图只存在加边的操作,因此维护也比较简单,只需要在添加关系时加上正反两条边就可以。
心得体会
JML要仔细读,1111这种奇怪的规格要求,如果不细读的话太难发现了,这一点可以说设计得很有趣。
中测完全是摆设···第一次的时候有个异常两id相同只记一次的坑,中测没有涉及到,自己写完之后得多进行测试才行。
优化一定要到位,点到为止属实不是好习惯,整出事故就坏了。
重测更新
重测1111没了,大快人心~之前几个被卡了0.1-0.6s的数据点也过了,挺好。

