

海量数据求 TOP N
海量数据求 TOPN
query 排名
有多台机器,每台机器日志记录了 query 的访问,每次有一个 query 查询就记录条日志。求访问次数最多的 n 条 query。
- 在每个机器上建立 <query, count> 的哈希表
- 每台机器将自己的 query [query0, queryn]列表汇总到一台机器上。
- 这台机器向所有机器发送 query_i 的出现次数,将其次数汇总到这台机器上。
- 在这台机器上建立一个大小为 n 的小顶堆。将汇总后的 <query_i,count_i> 插入到小顶堆之中,如果此时堆的大小超过了 n,那么就将堆顶元素移除。
- 在处理完所有 query 之后,就剩下了 top n 次数的 query。
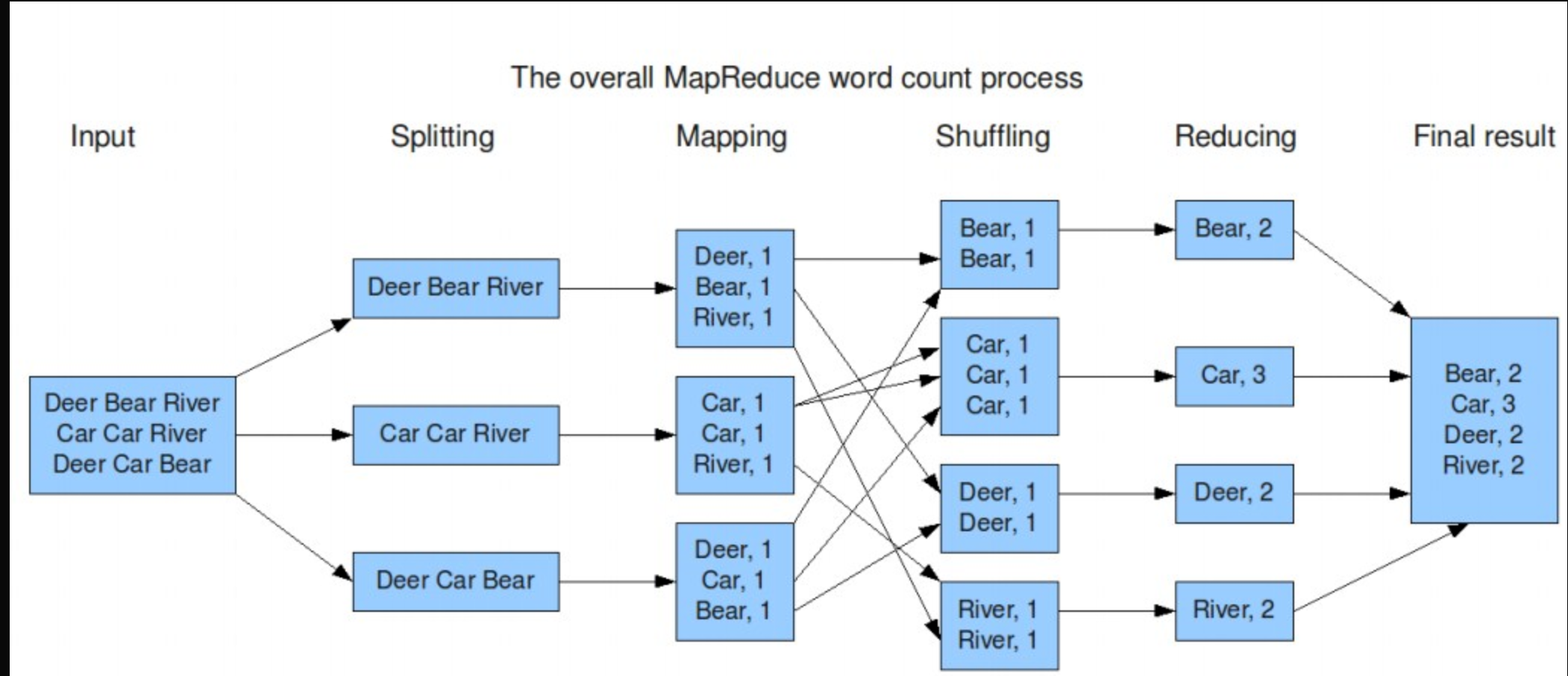
MapReduce


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧