

Apache Parquet/Arrow 笔记
Apache Parquet/Arrow
Parquet
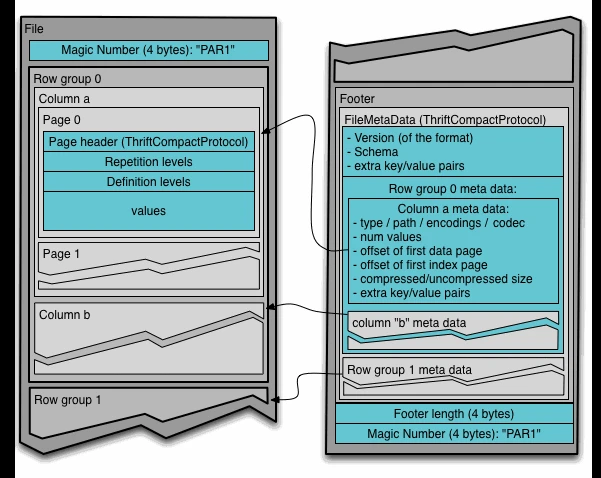
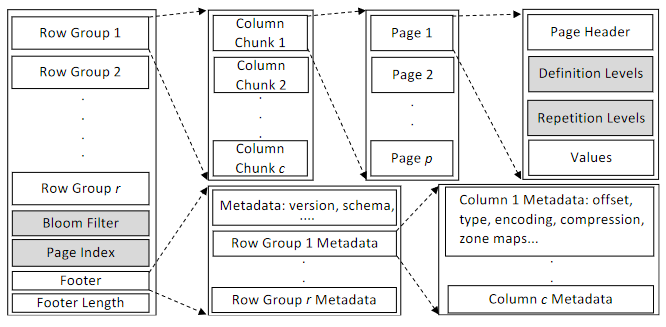
Parquet 文件的存储结构包括:
- Header:包含文件的 magic number(PAR1),表明文件是 Parquet 格式。
- Data Block:存放具体数据内容,由多个 Row Group 组成,每个 Row Group 包含该数据集中每一列的列块。
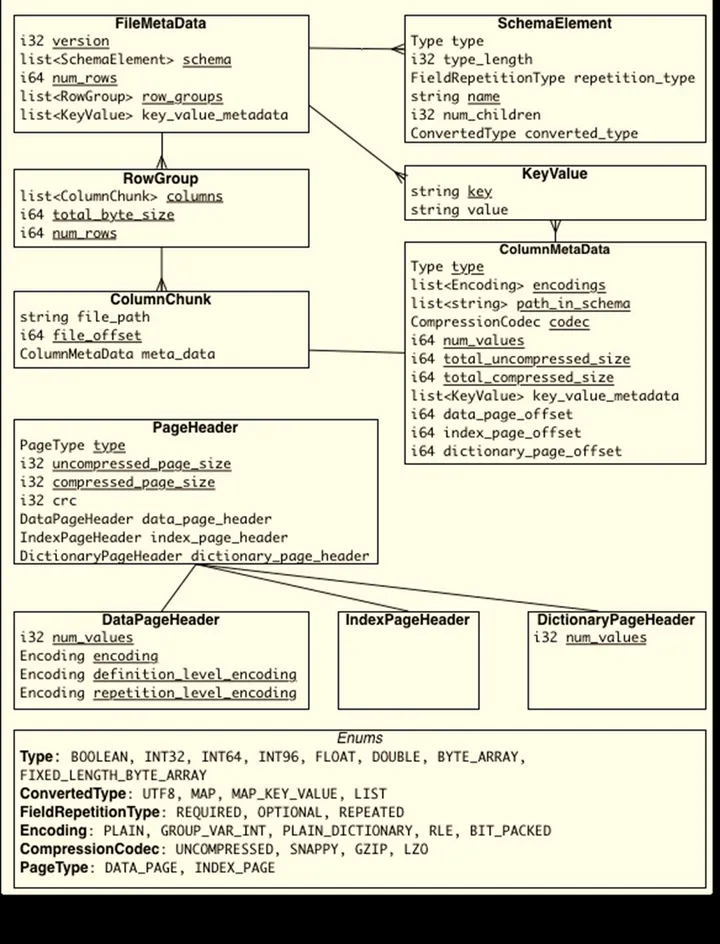
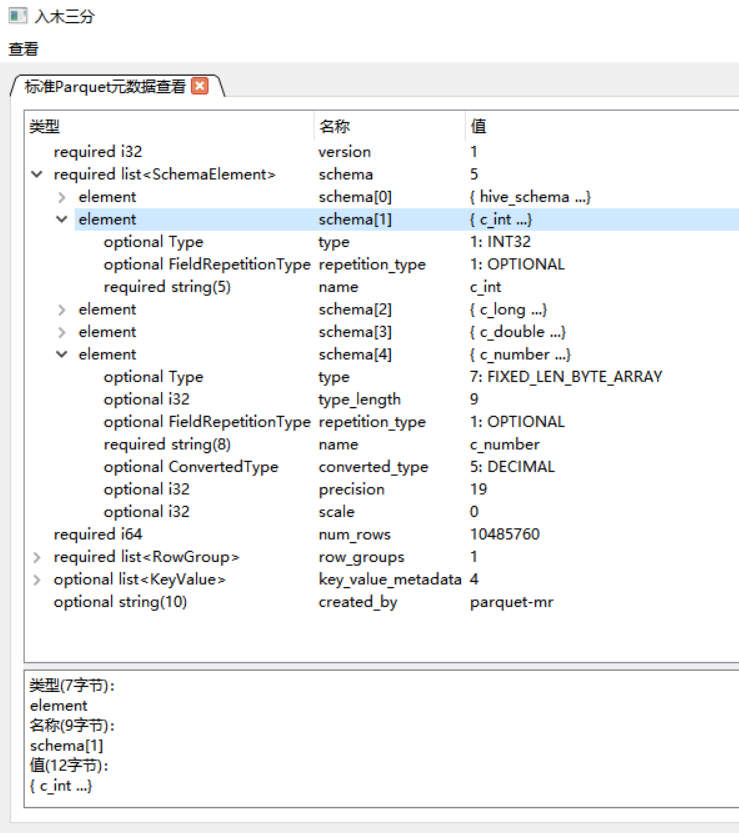
- Footer:包含文件的所有元数据信息,如版本、schema、列元数据等。

Arrow
Arrow 的本质是提供一个列存的二维内存表。
Apache Arrow 的主要目标是通过提供一个开放的标准,解决大数据领域常见的问题:大量的数据复制和序列化/反序列化操作所带来的性能问题,以及跨平台和跨语言环境下的数据兼容性问题。
Apache Arrow 的 ColumnReader 是一个用于从 Parquet 文件中读取单个列数据并将其转换为 Arrow 数组的组件。在处理大型数据集时,这种方法非常有用,因为它允许程序仅读取所需的列,而不是加载整个表的所有数据,这样可以节省大量的内存和提高性能。
序列化与进程间通信 (IPC)
多个长度相同的 array 组成的有序集合可以用来表示结果集的子集(或者部分的表),arrow 称这个有序集合为 Record Batch。Record Batch 也是序列化的基本单元。Arrow 定义了一个传输协议,能把多个Record Batch 序列化成一个二进制的字节流,并且把这些字节流反序列化成 Record Batch,从让数据能在不同的进程之间进行交换。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧