
论文笔记:The making of TPC-DS
论文笔记:The making of TPC-DS
这篇论文介绍了 TPC-DS 的主要特性,以及解释如此设计的原因,主要测试决策支持系统的哪些方面。
introduction
Transaction Processing Performance Council(TPC)是一个成立于1988年的非盈利组织。自此一直发布事务处理和数据库的基准。
1994 年 TPC 发布了第一个数据仓库的 benchmark TPC-D。
TPC-D 使用了包含 8 张表的 3NF schema。数据范围从 1GB - 3TB。由于查询重写技术的引入,在 1999.4 开发了两个衍生版本 TPC-H,TPC-R。
TPC-H 和 TPC-R 使用了相同的 schema,并引入了 10TB 的比例因子,多了 6 个查询。
- TPC-H an ad-hoc decision support benchmark
- TPC-R a business reporting decision support benchmark are nearly identical to TPC-D。由于论文上所描述的原因,TPC-R 于 2006.1 被废止。
3NF 的 TPC-H 由于没有数据倾斜,给基于统计信息收集的优化器压力很小。查询间差异小,能在被测试之前对系统进行调优,来提升性能。
为解决上述论文中提到的问题,在 2000 年,TPC 任命它的决策支持工作组(Decision Support Working Group)开发新的决策支持基准标准 (DS benchmark specification)。虽然计划在 2001 年完成标准的制定,但是 TPC-DS 标准的开发了超过 10 年,最终在 2012.1 通过。在 3 年之后的 2015 年,发布了 2.0 版本用于支持大数据系统。像 Apache Hive 和 Hadoop。
这篇论文主要介绍了:
- TPC-DS 的主要特性
- 以及从 TPC-DS 出发,抽象出来高效开发决策支持系统 benchmark 的通用方法。
主要关注的领域如下:

TPC-DS 模拟的零售产品供应商。抽象出了典型的场景,数据增长规律和常见的操作。一共有 99 条有差异的 SQL :其 SQL特点如下所述:
TPC-DS defines 99 distinct SQL-99 (with OILAP amendment) queries and 12 data maintenance operations covering typical DSS like query types such as
ad-hoc, reporting, iterative (drill down/up) and extraction queries and periodic refresh of the database.
logical schema creation
TPC-D 和其继任者 TPC-H,TPC-R 是 3NF schema。 TPC-DS 使用了 3NF 和 star schema 的混合 schema 叫做 multiple snowflake schemas。
multiple snowflake schema 与 pure star schema 的不同之处在于,snowflake schema 它将外围维度表中的静态数据与内部维度表和事实表中的更动态的数据分开。这意味着除了与事实表的关系之外,维度还可以与其他维度有关系。
在决策⽀持系统的 schema 中 event 被存放在大的事实表(fact table)中,而小的维度表(dimension table)⽤来描述数据。
3NF schema 由于其有 normalization process 会拥有大量的表。多重雪花模型,能够应对 star schema 和 3NF schema 所带来的挑战。
ad-hoc 查询因为 DBA 不能提前进行优化,可能会运行很长时间。
reporting workload 因为执行前可能已经知晓,可以对数据库系统进行优化,来让其执行的更快。
将这两种类型的查询合并在基准环境中一直是一个难题,因为根据基准的定义,除了绑定变量之外,所有查询都是预先知道的。
TPC-DS 通过将 schema 分为 reporting 和 ad-hoc 两部分来实现这种融合。下面介绍了这样做的原因:
For the reporting part of the schema complex auxiliary data structures are allowed, while for the ad-hoc part only basic auxiliary data structures are allowed. The idea behind this approach is that the queries accessing the ad-hoc part constitute the ad-hoc query set while the queries accessing the reporting part are considered the reporting queries.
下面以 store_sales 销售渠道为例,介绍了 TPC-DS 的 schema:

论文中将该表进行了简单的描述,图中的 customer address 表,被 customer 和 store_sales 表同时引用,能够很好的测试星型转化优化。
store_sales 和 store_return 之间有外键,可以进行 join。在单表星型模型下只能进行 self-join。不同的 fact table 之间也可以通过 Item 或者 Customer 进行连接。
Store 和 Web 相关的 schema 构成了 ad-hoc 部分,Catalog 的 schema 构成 reporting 的部分。 引用 Catalog channel 的查询是 ad-hoc 查询。
下表展示了 TPC-DS 范式在表和列上的统计特性:
| property | number |
|---|---|
| Number of fact tables | 7 |
| Number of dimension tables | 17 |
| Number of columns(min) | 3 |
| Number of columns(max) | 34 |
| Number of columns(avg) | 18 |
| Number of foreign keys | 104 |
| Row Length[bytes] (min) | 16 |
| Row Length[bytes] (max) | 317 |
| Row Length[bytes] (avg) | 136 |
下图介绍了各个表的名字,以及相关信息:

data set scale
数据集的设计不仅仅是统计信息收集算法和查询优化的需要,也是挑战数据布局算法的需要,例如聚类,垂直和水平分区的需求。
数据集设计需要注意的两个方面:
A good data set design includes proper data set scaling, both domain and tuple scaling.
a hybrid approach to data set design scores many advantages over both pure synthetic and pure real world data。
需要注意的是只有比例因子为 100,300,1000,3000,10000,30000 和 100000 的测试数据结果是有效的。因为其他比例因子生成的数据并没有设计好数据模型。生成的数据数量存在不合理。
data set scaling
scaling 包括两个方面:
- the number of tuples in the dataset is expanded, but the underlying value sets (the domains) remain static
- the number of tuples remains fixed, but the domains used to generate them are expanded.
对于第二种情况,可以举个例子,比如往数据集中,引入了新的零售商,或者能够记录更长的时间段(时间字段的 domin 值更大了)。
表中的大部分列,尤其是对于事实表一般采用 scaling scaling。对于 small table 中的一些列采用 domain scaling。在调整 domain scaling 要注意按比例缩小。
fact table 进行线性 scaling with scale factor,dimensions 进行次线性 scale。避免了TPC-H 下存在的不切实际的表比率。即使有高比例因素,顾客、商品、商店和其他维度的比例仍然是现实的。
下图展示了不同 scale factor 下,各表的基数:

Synthetic vs. Real Data Set
人造的数据集,通常使用数学模型、经过充分研究的分布(如正态分布或泊松分布)。这些分布导致合成数据集,这些数据集在决策支持基准方面有许多优点,但也有一个显著的缺点:They do not work very well for decision support benchmarks that need to dynamically substitute bind variables。
绑定变量用于使基准测试更不可预测,并覆盖整个数据集,而不是由查询谓词定义的子集。
对于 SQL 查询,这意味着只有那些保持以下内容几乎相同的替换是允许的:

遵循上述规则,TPC-DS 在其大部分数据中采用传统的人造分布,使用均匀分布的整数或具有高斯分布的 word selections。而对于一些关键的分布,TPC-DS 构造真实世界的数据,创建所谓的可比性区域。可比区域中的数据具有均匀分布。对于 TPC-DS 查询集中的每个selectivity,group by和 order by 谓词的替换,会从同一可比性区域中选择值。
然后论文中举了一个例子对 zone 进行了讲解,如下图所示:


Specific Multi Dimensional Issues in TPCDS’s Data Populations
- Hierarchies The hierarchies defined in the TPCDS schema all display simple, single-inheritance.
- Slowly Changing Dimensions
In addition to the transaction-focused fact tables and attributefocused dimension tables described above, a typical multidimensional system includes some dimensions whose data
evolves over the life of the system. Referred to as slowly changing
dimensions (SCD), they capture the historical evolution of a data
set. Each entity in a SCD can change attributes.
然后举了几个例子来说明什么是 SCD。也就是给维度表增加版本信息,主要是靠增加开始日期和结束日期字段。在 SCD 中任何的维度表 entry 最多有 3 个版本,这很重要,因为第二次性能运行应该作为第一次性能运行的重复,因此应具有相同的数据特征。
workload
TPC-DS 标准有两个重要的组成部分:
1.user queries
2.data maintenance
Query workload
the query modeled by the benchmark cover:

reporting 查询,ad-hoc 查询,iterative olap,data mining 查询。
reporting query 是"事先非常熟悉的”,因此可以使用“灵活的数据分配方法”和“辅助数据结构(例如物化视图、索引)”进行优化。
ad-hoc 查询,模拟事先不知道的用户查询。为此,禁止通过辅助数据结构(如DDL、会话选项、全局配置参数)对架构的特殊部分进行某些显式优化。后者与 TPC-H 一起引入,以解决 TPC-D 的性能相关问题。
iterative olap 查询被实现为一系列语法上独立但逻辑上相关的查询。
data mining queries 数据挖掘查询的特点是返回大量输出。尽管这种输出不在 TPC-DS 的范围内,但它旨在为数据挖掘工具提供数据。
iterative olap 和 data mining querier 可以分为 ad-hoc 查询和 reporting 查询,因为它们同时引用 schema 的两部分、ad-hoc 查询和 reporting 的查询部分。因此,它们也被视为“混合查询”。
TPC-DS 的查询是由 template 来保证能覆盖到整个数据集的:
The query set is designed to cover the entire dataset. This is guaranteed by a sophisticated query template model. Templatebased queries are defined as sets of one or more pseudo-random, valid SQL statements produced at the time of benchmark execution. Template-based queries are intended to model common, well-understood queries.
替换 query template 中的 sql fragment 和 scalar constant 为 valid sql。
query generator 定义了多种类型的 substitutions,包括:
They include filter predicates, such as equality, in-list and between predicates. More complex text substations are also possible, such as exchanging aggregations, such as max, min.
Data Maintenance workload
TPS-DS 强调随着决策⽀持系统的增长,吸收⼀个新数据库数据的能⼒。
TPC-DS 将定期数据刷新过程视为数据仓库生命周期的组成部分。其刷新过程以 ETL 为模型,而 ETL 是一种将数据从一个或多个源系统复制到目标系统的通用过程。它由以下三个步骤组成,大多数数据仓库系统通常都支持这些步骤:
- 数据提取(E)
- 数据转换(T)
- 数据加载(L)
在进行基准测试之前,从外部系统提取的数据将生成文本文件用于展示。数据转换和数据装入步骤是数据维护工作量的一部分,该部分将更新,插入和删除操作合并到测试数据库中。
维度表中的 “business key”,类似于 OLTP 系统中的 primary key。
rec_end_date 是 NULL,表示当前的记录。
在 data maintenance workload 中:
The data maintenance workload contains the updating of dimension rows, the inserting and the deleting of fact table rows.
Dimensions are categorized in static, non-history keeping and history keeping dimensions. Static dimensions such as Date_dim,
Time_dim, and Reason are loaded once at the beginning of the
benchmark and are not updated during the data maintenance
phase.
下面介绍了 维度表 maintained 的算法:


然后是 fact table maintained 的算法:
Fact table data are deleted and inserted in a logically clustered fashion.

execution rules and metric
The execution rules and the metric are two fundamental components of any benchmark definition and are probably the most controversial when trying to reach an agreement between different companies.
General Metric Considerations
A performance metric needs to be simple such that easy system comparisons are possible. In order to unambiguously rank results, the TPC benchmarks focus on a single primary performance metric, which encompass all aspects of a system’s performance weighting the individual components.
Execution Rules
如下图所示,展示了
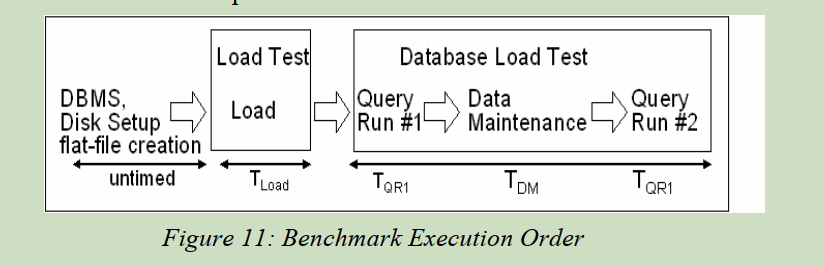
The performance test consists of two query runs and one data
maintenance run. The first query run (Query Run 1) measures the
query execution power of the system immediately after it is
loaded. The data maintenance run measures the system’s ability
to load, delete and update data and to maintain auxiliary data
structures. The second query (Query Run 2) measures the query
execution power after the system has been updated and auxiliary
data structures have been maintained, thereby, revealing any
query performance changes due to the maintenance of auxiliary
data structures. Without including a second query run it would be
possible to avoid or defer maintenance of auxiliary data structures,
thereby, not including their time in the measured interval
不同的 scale facotr 下的并发数量的要求:

Primary Metrics
性能基准
反应每小时的有效查询数量的性能指标,其计算公式为:QphDS@SF(SF是数据库规模因子,单位为GB,最小为100GB),值越大说明性能越高。

Tqr1:在 Query#1 执行的时间
Tqr2:在 Query#2 执行的时间
Tdm: 数据维持所花费的时间
Tload:数据加载所花费的时间
S:执行 benchmark 的数据流个数
SF:比列因子
论文接下来解释了公式中各个参数的决定考虑。
由于 catalog 渠道的相关 25% data set 是允许使用辅助的数据结构的,所以公式里有 Tload 相关参数的考量。
公式里的 0.01 系数是为了提供一个能够评估和比较的 metric,而不是为了模拟特定的 DSS 环境。
价格-性能基准
反应每秒查询数据量的性价比指标,值越小说明性价比越高。其公式为:

$ 是指使用三年时间的总花费,包括软件,硬件,7*24 小时维护花费,4 小时内用户问题反馈花费。
完整配置的可用日期
term
-
data maintenance : data maintenance is the process of organizing and curating data according to University needs properly maintaining and caring for data is essential to ensuring that data remains accessible and usable for its intended purposes.
-
catalog : A book printed and distributed periodically by a department store or mail-order retail company containing pictures and descriptions of merchandise offered for sale, as well as an order form for ordering such merchandise by mail.
-
reporting queries are "very well konwn in advance" so that "clever data placement methods" and "auxiliary data structures" can be used for optimization.
-
ad-hoc queries form the opposite and should simulate user queries not known in advance. For this purpose,certain explicit optimizations via auxiliary data structures(such as DDL,session options,global configuration parameters) are prohibited for the ad-hoc port of the schema. The latter technique was introduced with TPC-H to fix the performance-ralated issues with TPC-D.
-
变量绑定:是指在sql语句的条件中使用变量而不是常量。
词汇
pertinent 有关的,恰当的
curate 操持;组织
warehouse 仓库
multiple snowflake schema 多重雪花范式
coupling 耦合
confronted 使…无法回避; 降临于; 处理,解决(问题或困境); 面对; 对抗; 与(某人)对峙
hefty adj 有力的;猛烈的
spurred 鞭策; 激励; 刺激; 鼓舞; 促进,加速,刺激(某事发生); 策(马)前进; (尤指用马刺)策(马)加速;
transparently 透明地,明亮地
proportional increase 成比例增长
decommission 拆散(核反应堆、大型机械等);使退役
vouch for 保证;担保;表示负责;保证做到或保证不出问题
manifold 多的;多种多样的;许多种类的
purity 纯洁;纯净;纯粹
amalgamate (使)合并,联合
cornerstone 基石;奠基石
accommodating 乐于助人的;与人方便的
constellation 一系列(相关的想法、事物);一群(相关的人)
pertinent 直接相关的
scaling down 按比例缩小
qualifying rows 符合条件的行
numerator 分子
denominator 分母
impartial 公正的

