

面试题
一、JAVA 基础
JAVA 的基本类型有哪些?
八个:short、int、long、char、float、double、byte、boolean
== 和 equals() 的区别?equals() 和 hashCode() 联系?
== : 对于基本类型比较的是值、对于对象比较的是内存地址
equals() : 如果对象没有重写此方法,那么和 == 等效。重写一般比较的是内容,例如 String
equals 和 hashCode 联系:如果一个类你不打算创建它的 Set 集合,那么这两个东西没什么联系。否则,你要创建 Set 集合,那么重写 equals 方法的时候也必须重写 hashCode。
参考阅读此链接
final、finally、finalize的区别?
二、JAVA 集合
HashMap 了解吗 ?
HashMap 是存储键值对常用的数据结构,在 JDK1.8 底层实现是哈希数组+链表/红黑树
HashMap 中 put 操作流程 ?
1)判断哈希数组 table 是否为空,为空则进行初始化
2)计算 key 的 hash = key.hashCode()) ^ (key.hashCode()>>>16)并通过 hash & (length - 1) 来获取其在哈希表的下标 index
3)查看 table[index] 是否为空,为空就新建一个 Node 放进去
4)如果 table[index] 不为空,则判断是否有相等的 key 存在,若存在则将对应 value 替换
5)如果不存在相等的 key 则判断当前节点结构是否为红黑树,如果是则插进去
6)如果不是红黑树是链表则插进链表,此后根据 length >= (默认64) && 链表长度 >= (默认8) 判断是否转红黑树
7)插入完成后判断当前结点数是否大于阈值(即 > loadfactor * length)来判断是否扩容(resize)
HashMap 相较 JDK1.7 的版本,JDK1.8 版本做了哪些改变?
1)解决冲突的节点结构中,由 链表 => 链表+红黑树
2)链表的插入方式中,由 头插法 => 尾插法,扩容时链表不会被倒置
3)扩容重哈希找节点下标中,1.7版是重新计算 Hash,1.8 版根据原 Hash 值的二进制位值优化判断和操作
缘何做这些改变?参考此链接
HashMap 和 ConcurrentHashMap 的区别?
HashMap 线程不安全,在多个线程 put 操作的时候会产生环,查询环内节点会产生死循环。
死循环如何产生参考此链接。ConcurrentHashMap 是线程安全的。
那能介绍一下 ConcurrentHashMap 吗?它是如何保证线程安全的?
ConcurrentHashMap 有着比 HashTable 更加高效的性能,相比 HashTable 直接锁住整个集合的方式,ConcurrentHashMap 在 1.7 是划分为 Segment 的方式实现,而 1.8 优化成了粒度更小的 Node 且使用了无锁策略的 CAS 来实现线程安全。1.7版的实现方式具体可以查看此链接、1.8版本的实现方式具体可查看此链接
三、多线程
1、ThreadLocal 原理?弱引用带来的内存泄漏?
ThreadLocal 变量在每一个线程中都保有属于线程自己的副本,在多线程环境下不会产生互相干扰问题。实现的原理就是每个线程都维护了一个 ThreadLocalMap,这是一个 ThreadLocal 的内部类,其和 Map 相似存放 <K, V>,K 是 ThreadLocal 对象(是弱引用)且 V 是线程独立拥有的变量对象。但是这个 ThreadLocalMap 并不实现 Map 接口,一旦哈希冲突,它采用的是线性探测法,所以如果让线程维护很多个 ThreadLocal 对象,则很有可能产生哈希冲突,导致效率变差。下面左图为原理图,右边为引用示意图(虚线为弱引用)
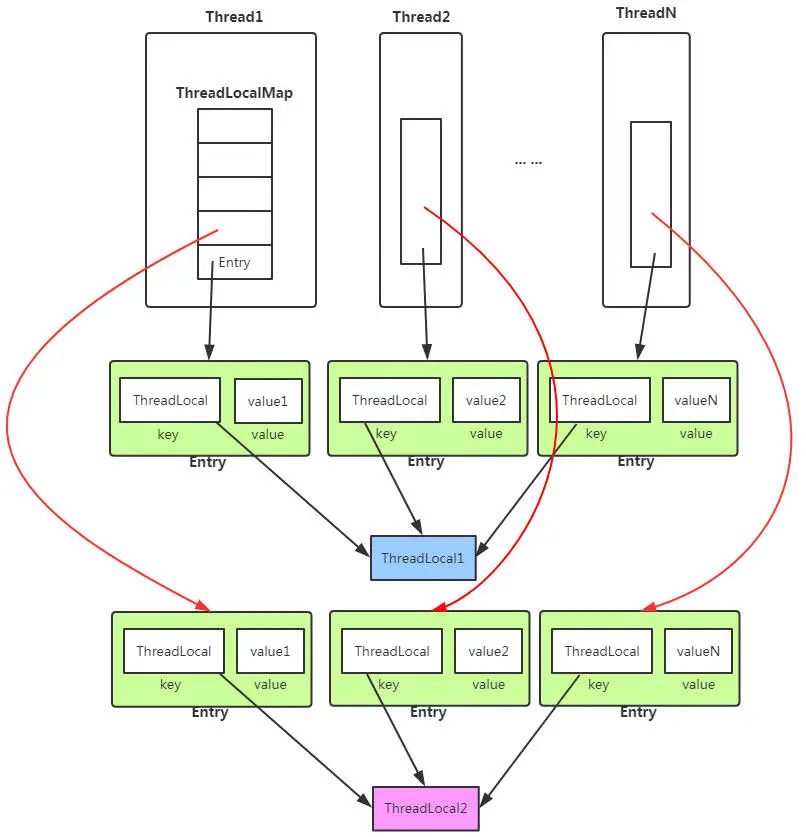
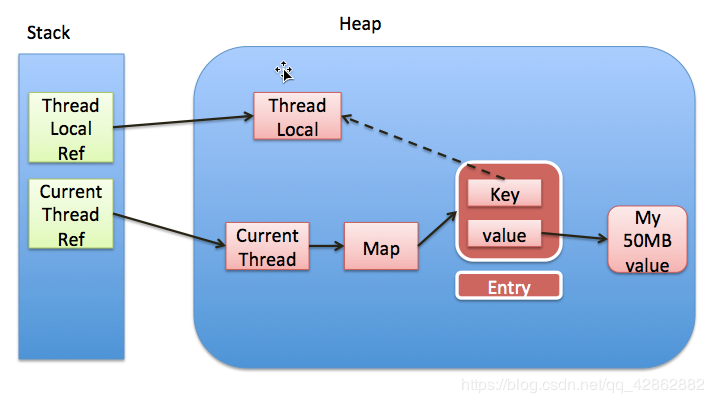
内存泄漏问题:由上面第二幅原理图可以看出,如果外部的 ThreadLocal 变量失去了强引用(如 ThreadLocal = null)那么此时引用 ThreadLocal 的只有每个线程里面 Map 的 Key,但是很可惜,这个是弱引用,声明周期到下一个 GC 就会被收回,ThreadLocal 变量被收回之后存在一个问题,Key 对应的 Value 是强引用啊?那么对应的 Entry 并不会被收回,而失去了 Key 那么这个 Value 就不会被利用,由此就产生了内存泄漏。当然,ThreadLocal 里面还有一个方法叫 expungeStaleEntry(),在每次 get、set、remove、rehash 都会调用,它会将 remove 的 Value 置为 null,同样也会将所有已经被回收的 Key 对应的 Value 置为 null。但是如果线程永远不去进行 get、set 等操作,那么这段时期,这个 Entry 就永远不会被 GC 回收,这段时期就是内存泄漏时期了!所以每个线程在使用完 ThreadLocal 变量之后最好都调用 remove() 方法。
2、大致描述一下线程池的工作原理?
参考此链接,看完链接相信一定就能组织语言答出来了
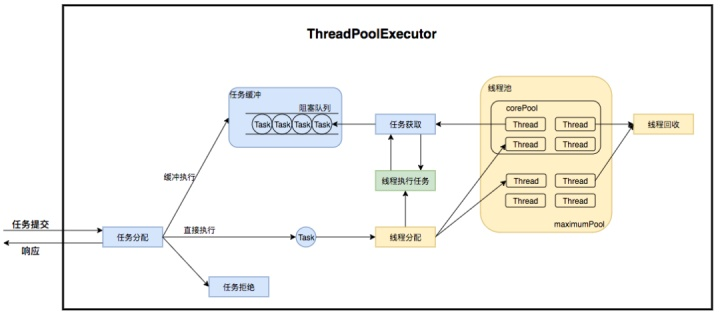
3、new 一个 ThreadPoolExecutor 都有哪些参数,代表什么含义?
4、四种线程池?四种工作队列?四种拒绝策略?(各自属性特点+使用场景)
四、JVM 相关
1、阐述一下运行时数据区?
五、数据库
1、事务并发可能出现的问题?事务隔离级别?
1)事务 ACID 四大特性:原子、一致、隔离、持久
2)事务并发会出现的问题:更新丢失、脏读、不可重复读、幻读
(当然还有脏写、写偏差等,但是面试会这些就够了)
3)事务隔离级别如下(MySQL 实验结果 推荐阅读)
读未提交(Read Uncommitted):事务 A 可以读到事务 B 还未提交的修改操作,显然这样做什么都避免不了
读已提交(Read Committed):事务 A 只可以读到事务 B 已经提交的操作,这样可以避免脏读,但是根据是不可重复读的,因为如果 A 在 B 事务开启前进行了查询操作,然后 B 事务开启事务并完成了修改操作且提交,此时因为 B 的事务是已经提交了的,所以如果 A 在这之后又执行了 B 事务开始前一模一样的查询操作,就发生了不可重复读错误。
可重复读(Repeatable Read):主流数据库采用的是 MVCC 多版本并发控制来实现 RR,这样的方式还能避免幻读。
串行化(Serializable):事务排队,一个个执行,这样天下太平
2、数据库索引失效的情况?
1)索引列使用函数、表达式、计算等 例如 where id + 1= 4
2)like 前面带 % 用不到
3)非逻辑查找 例如 not like
4)组合查询遇到中断情况中断后面字段不走索引,中断情况一般为字段中断或者范围查找
例如索引 (a, b, c) 那么 where a=1, c=2 只有 a 用到了索引。where a=1, b>1, c=1,只有 a,b走索引
3、B Tree 和 B+Tree 是什么?区别?
4、建立索引时候的一些建议?
1)字段会出现在 where... 、order by... 、join on... 上建议创建索引
2)索引个数不要太多,浪费空间,插入和删除操作会变慢
3)区分度低的字段,尽量别建立索引,例如性别,因为字段太多相同,即便建立索引在查找的时候也会扫描很多节点
4)频繁更新的值,不建议作为主键或者索引
5)组合索引把区分度高的值放在最左边
6)过长的字段建立索引,可以考虑前缀索引 or 哈希处理之后进行索引建立
5、MVCC
这里我就真的要推荐一个超好的文章了:参考链接
简述(建议别看这个简述,这个是给我自己看的,看链接就好,链接内容真的很棒):每个数据库记录都有两个隐藏字段,更新这个记录事务的 ID 和回滚指针 roll pointer,每次更新 ID 都会记录当前更新它的事务的 ID(事务都有一个id,且这个id是递增的),那么更新前和更新后就形成了新旧两个版本,旧版本存在了 undo log 中,新版本的 roll pointer 指向旧版本,以此类推会形成一个版本链,链头是记录最新的模样,沿着链走会找到它的各个历史版本。其实这个就是多版本了,那么这个有什么用呢?首先 MVCC 中事务在读的时候,执行的是快照读,快照读会生成一个快照(快照里面记录了当前快照生成时刻正在活跃线程的 ID,以及当前还未分配出去的最小的事务 ID,例如当前已经执行了三个事务,那么当前还未分配出去的最小事务 ID 就是 4),通过快照里面的信息,可以帮助当前执行快照读的事务进行可见性算法。具体就是,前面说到,记录都有新旧版本嘛且记录了更新每个版本的事务 ID,首先执行快照读的事务取出读取那一条记录最新版本中记录的操作此版本的事务 ID,和快照里面的信息进行比对,例如此 ID 比快照里面记录的所有在快照生成时候活跃的事务 ID 都要小,那么也就是说此记录早在那些快照生成时的活跃事务开启前就被完成了修改了,那么这个记录对当前执行快照读的事务是可见的,如果此 ID 大于等于快照中记录的快照生成时还未分配的事务 ID ,那么也就是说在快照生成之后有事务动了这个记录,当前记录版本对进行快照读的事务不可见,那么就要根据 roll pointer 指针回溯到上一个版本去找可见的版本,最后一种情况就是此 ID 不大也不小,正好介于快照记录的生成快照时活跃事务的最小 ID 和生成快照时还未分配的事务 ID 之间的话,就看看此 ID 在不在快照记录的活跃事务 ID 里面,如果在,就说明也是不可见的,继续回溯。当然如果你看到了这里,看不懂,没关系,去看那个链接,这里的废话只是我脑中的理解。接下来说说,RC 和 RR 隔离级别下有什么区别,RC 级别下就是每次快照读都生成一次快照,而 RR 就是每次快照读依赖的快照都是第一次快照读生成的,这样就不会产生不可重复读,并且还解决了幻读,真是妙不可言!
六、计算机网络
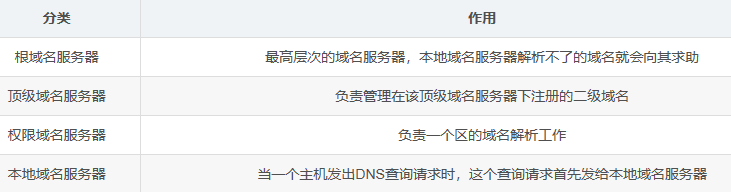
1、讲一下从输入网址到获得页面都经过了什么过程?
1)浏览器根据域名查询 DNS 获得主机 IP,具体包括搜索自身 DNS 缓存、搜索操作系统 DNS 缓存、读取本地 Hosts 文件,如果都没有则向本地 DNS 服务器发起查询。如果本地 DNS 服务器解析不了,那么将向根域名服务器发起迭代查询,根域名服务器会告诉本地域名服务器对应的顶级域名服务器位置,然后就是到权限域名服务器,最后把结果交给本地域名服务器,最后再交给主机。
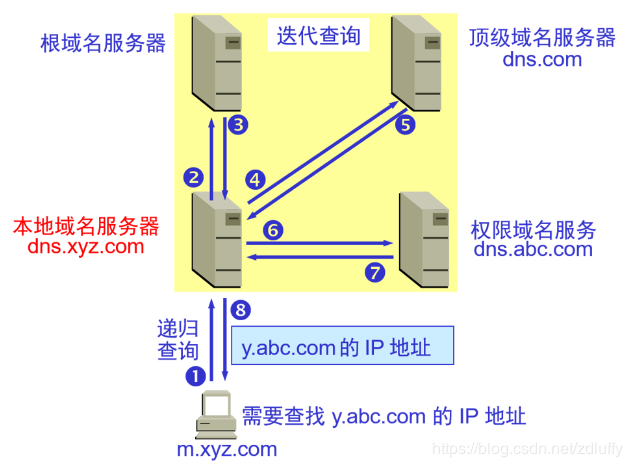
2)浏览器获得域名 IP 后,向 IP 指向的服务器建立链接,发起三次握手
3)TCP 链接建立之后,浏览器就会向服务器发送 HTTP 请求
4)服务器接收到这个请求之后,会根据路径参数映射到特定的请求处理器处理,并将处理结果和对应视图返回给浏览器
5)浏览器解析并渲染视图,若遇到 js、css或者其他静态资源,则重复上述不在向服务器请求这些资源
6)浏览器根据请求到的资源最后呈现给用户一个完整的页面
2、TCP 和 UDP 的区别?
1)TCP 面向连接可靠性高,UDP 基于非连接可靠性低
2)TCP 建立连接有三次握手、重传机制,会有延时,实时性相较 UDP 较差
3)TCP 的报头比 UDP 复杂,占用字节数也比 UDP 大,TCP为 20 字节,UDP为 8 字节
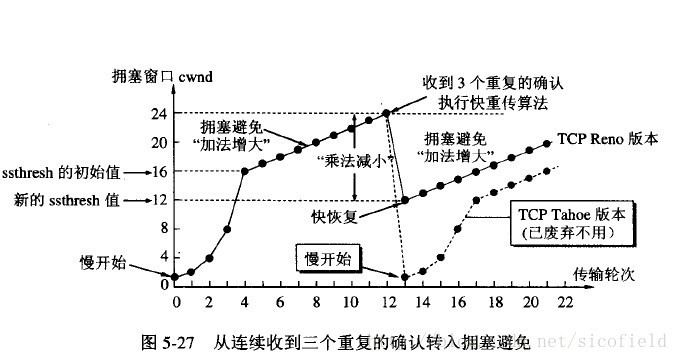
3、TCP 拥塞处理讲一下?
1)慢开始:不要一开始就发送大量数据,先探测一下,让拥塞窗口(cwnd)设为一个MSS(最大报文段)然后每经过一轮 RTT(一个往返时间) 这个窗口值就呈2的幂的指数增长,直到超过门限值(ssthresh)后采用拥塞避免算法
2)拥塞避免算法:让 cwnd 缓慢增大,每经过一个 RTT 就 + 1
以上无论哪个算法,一旦出现拥塞,那么就吧 ssthreash 设置为 cwnd/2

3)快重传:快重传要求接收方在收到一个 失序的报文段 后就立即发出 重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时捎带确认。快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。

4)快恢复:快重传配合使用的还有快恢复算法,当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半,但是接下去并不执行慢开始算法。因为如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法。
4、 HTTP 有哪些状态码?分别代表什么含义?


