软件安全笔试 重点内容复习
软件安全笔试 重点内容复习
注:本文着重于理论考试的笔试复习,与实践仍有一定差距
免责声明:本文中知识仅供学习参考
第1章 软件安全概论
2)牢记任何软件都是不安全的
-
为什么软件测试无法保证软件的安全性
由于软件系统规模越来越大,软件开发的进度要求越来越高,不可能在有限的时间内考虑所有安全方面的问题,即使进行了全方位的测试,也只能对所有的测试案例进行很小范围的覆盖 。即由于工程进度问题,实际上在测试时不可能兼顾全面,往往只是采用了一些具有代表性的测试案例来进行测试,但这些测试案例在设计的时候又不能保证能够具有最全面的代表性。
![image-20220530134519679]()
总情况数为\(5^{20}\),测试一种情况需要\(20ms\) ,总共时间为 \(20*5^{20}ms\)
-
分析存在问题的代码案例
注意整数溢出,use after free等问题

4)软件安全问题产生的原因
软件在设计、编码、测试和运行阶段,没有发现软件中的各种安全隐患,导致软件的不安全。
软件缺陷和错误
错误是指软件实现过程出现的问题,大多数的错误可以很容易发现并修复,如缓冲区溢出、死锁、不安全的系统调用、不完整的输入检测机制和不完善的数据保护措施等;
缺陷是 一个更深层次的问题,它往往产生于设计阶段并在代码中实例化且难于发现,如设计期间的功能划分问题等,这种问题带来的危害更大,但是不属于编程的范畴。
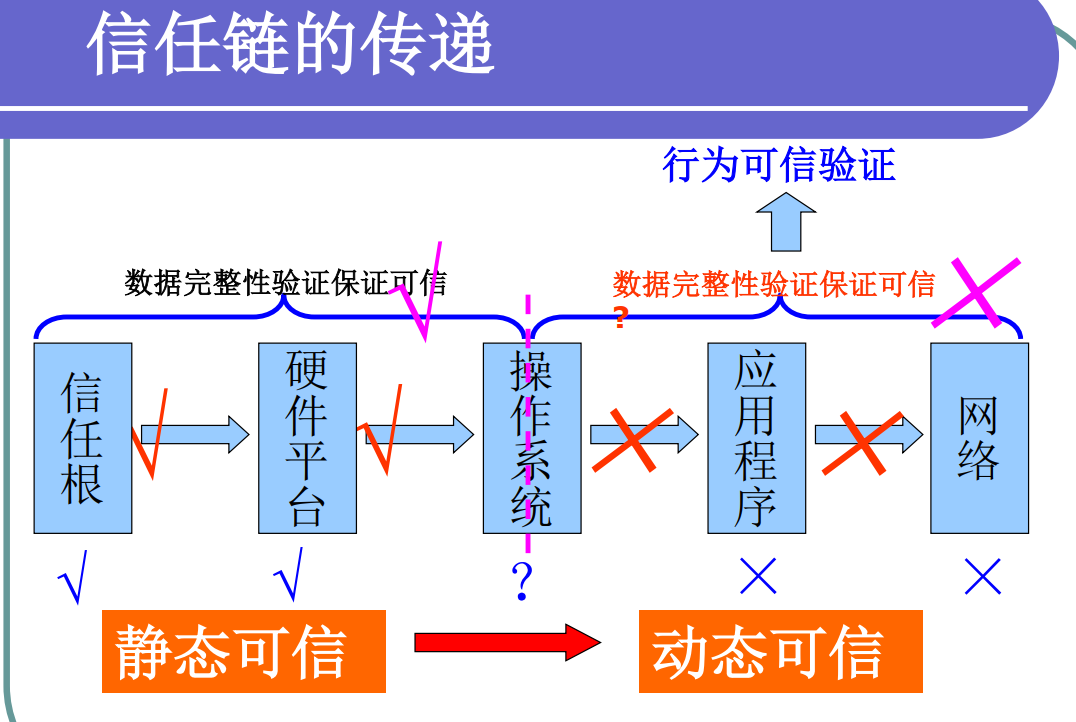
5)软件安全防护手段
-
安全设计与开发 -> 软件的开发管理流程
-
保障运行环境 -> 软件完整性校验 和 系统完整性校验
-
加强软件自身行为认证 -> 软件动态可信认证 :在确保软件数据完整性的前提下,如何确保软件的行为总是以预期的方式,朝着预期的目标运行
不同层面可信验证
![image-20220530143242754]()
-
恶意软件检测与查杀 -> 扫描、检测、主动防御恶意软件
-
黑客攻击防护 -> 防御黑客入侵
-
系统还原 -> 还原备份,彻底清除恶意程序
-
虚拟隔离 -> 隔离风险
第2章 软件安全基础知识
2)Windows/Linux 虚拟地址空间
每个用户模式进程都有其各自的专用虚拟地址空间,但在内核模式下运行的所有代码都共享称为“系统空间” 的单个虚拟地址空间。 用户模式进程的虚拟地址空间称为“用户空间” 。
在 32 位 Windows 中,可用的虚拟地址空间共计为 2^32 字节(4 GB)。 通常,较低的 2 GB 用于用户空间,较高的 2 GB 用于系统空间。可以将用户空间的大小增加到 3 GB,在这种情况下,系统空间只有1 GB 可用。
程序在内存中的映像整体情况
重点看 windows 32位
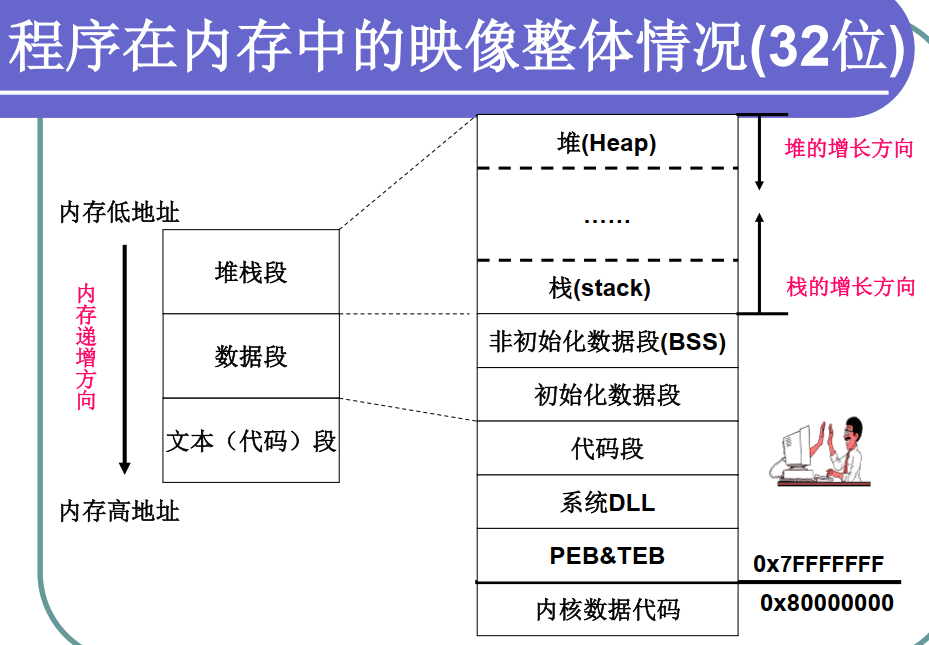
用户区是每个进程真正独立的可用内存空间,进程中的绝大部分数据都保存在这一区域。主要包括: 应用程序代码、全局变量、所有线程的线程栈以及加载的DLL代码等
每个进程的用户区的虚拟内存空间相互独立,一般不可以直接跨进程访问,这使得一个程序直接破坏另一个程序的可能性非常小
内存内核区中的所有数据是所用进程共享的,是操作系统代码的驻地。 其中包括: 操作系统内核代码,以及与线程调度、内存管理、文件系统支持、网络支持、设备驱动程序相关的代码
该分区中所有代码和数据都被操作系统保护。 用户模式代码无法直接访问和操作: 如果应用程序直接对该内存空间内的地址访问,将会发生地址访问违规。
32位系统下malloc思考题
1.windows编程中malloc实际上能够支持多大的内存呢?
用户空间2g,考虑其他开销,最多能申请2g少一些
2.不断增加物理内存, 能够增加malloc的内存大小吗?
不能,32位系统下虚拟地址空间最大4G
3.为什么增加物理内存,能够使得系统跑得更流畅呢?
- 一部分进程在物理内存中运行完后,将进行下一部分的加载和运行,而增加物理内存后,可以使得加载的速度更快,等待的进程更少,从而使系统运行得更流畅。
- 物理内存不够的情况下,系统会使用外存硬盘当做内存使用,但外存速度远低于内存所以慢
FAT32文件系统 为什么一般删除的文件可以恢复/如何彻底删除文件
文件被删除后,发生以下变化
(1) 目录项中文件名首字节被修改为E5、首簇高位被清零
(2) FAT表簇链被全部清空
注:文件内容本身无变化
(1)
文件名首字节被修改为E5,无需恢复,不影响文件本身内容查看。
如果文件在数据区中存放的位置比较靠前,文件起始簇号就会小,高位即为00,无需恢复,即可略过此步骤。反之,那么文件目录项中记录文件起始簇号的高位两个字节就会有数据,当文件删除时,这两个字节会被清零,该文件的起始簇号值也就丢失了,这种删除的文件参考以下两点:
①文件删除后,文件的创建时间并不改变,所以可以寻找与被删除的文件创建时间十分相近的文件(如相邻目录项),参考它们的起始簇号高位的两个字节。
②用穷举法,编一个程序,对起始簇号的高位依次穷举,然后验证。
(2)
文件删除后,其FAT表中的簇链也会清零,如果文件有碎片,也就是不连续存放,这种删除的文件也比较难恢复。
如果连续存储即可采用以下方法 :
通过文件大小先算出总簇数n,再通过上一步恢复的首簇开始连续n个簇即为文件内容。
注:文件删除后,虽然文件的内容并不会被清除,但其所占用的簇会释放,这些簇就很容易被其他文件进一步占用,这样就覆盖了被删除文件的数据,这种情况下的数据将无法恢复。
彻底删除文件,即在删除文件后,使用其他文件覆盖被删除文件原本占用的簇,覆盖原数据,实现彻底删除。
PE 文件与内存之间的映射
文件偏移地址(File offset):指定的这部分内容在磁盘上PE 文件中相对于文件头的偏移
装载基址 (Image Base):PE 装入内存时的基地址
虚拟内存地址(VA):PE 文件中的指令被装入内存后的虚拟内存地址
相对虚拟地址(RVA):指令的虚拟内存地址相对于装载基址的偏移量
相对内存偏移 (RVA) = 内存地址(VA) - 加载基址(Image Base)
节偏移 = Voffset(VSO 该节在内存中的偏移量) - Roffset(FSO 该节在文件中的偏移量)
文件偏移 = 相对内存偏移 (RVA) - 节偏移
如下图中例子
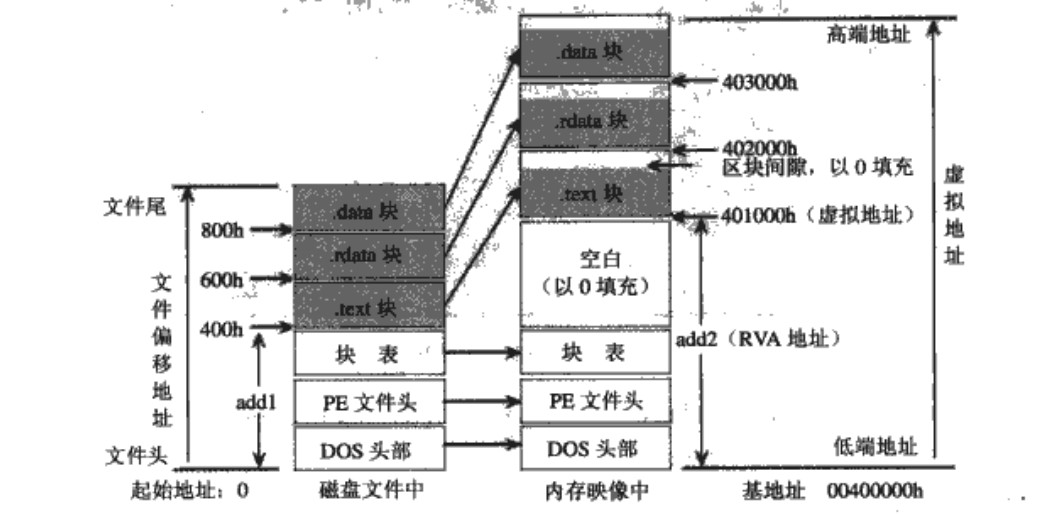
对于上图应用程序,给定一个内存地址 401125h,求对应的文件偏移地址。
根据上图知,该内存地址在. text 节,则根据文件偏移的计算方法
相对内存偏移 (RVA) = 401125h - 400000h = 1125h
. text 节,左边 400h - 0h = 400h 是 Roffset(.text 节在文件中的偏移量),右边 401000h - 400000h = 1000h 是 Voffset(.text 节在内存中的偏移量)
.text 节偏移 = 1000h - 400h = c00h
文件偏移 = 1125h - c00h = 525h
可以这样理解节偏移,2 个人比赛跑步,跑了一样的距离 125h,但起跑线不同 (一个从左边 400h 开始跑,另一个从右边 1000h 开始跑)。节偏移就是起跑线的差距。
第3章 恶意代码及其分类
恶意代码攻击目标
- 定点攻击
邮件、 IP、域名、 QQ等
服务器列表、特定人员名单等
- 群体攻击
挂马攻击、钓鱼攻击
病毒、蠕虫自动扩散
恶意代码功能
获取数据:静态数据,动态数据
动态控制与渗透拓展攻击路径等:中间系统,相关人员
破坏系统:删除修改数据,破坏系统服务、制程设备等
计算机病毒和网络蠕虫
计算机病毒:一组能够进行自我传播、需要用户干预来触发执行的破坏性程序或代码。 如CIH,熊猫烧香等
网络蠕虫:一组能够进行自我传播、不需要用户干预即可触发执行的破坏性程序或代码。 其通过不断搜索和侵入具有漏洞的主机来自动传播。 如SQL蠕虫王、震网等。
木马与后门
特洛伊木马:是指一类看起来具有正常功能,但实际上隐藏着很多用户不希望功能的程序。通常由控制端和被控制端两端组成。
后门:使得攻击者可以对系统进行非授权访问的一类程序。
相关法律

第4章 PE文件格式
注:本文中部分名称为本次笔试考试要求,可能部分名称较旧,与微软官方文档不一致,请以微软官方文档为准
全部详细说明详见微软官方文档
大体说明(只介绍完PE头)详见此链接
下图为吾爱破解中图片仅供参考

以下是笔试考试重点内容
整体结构
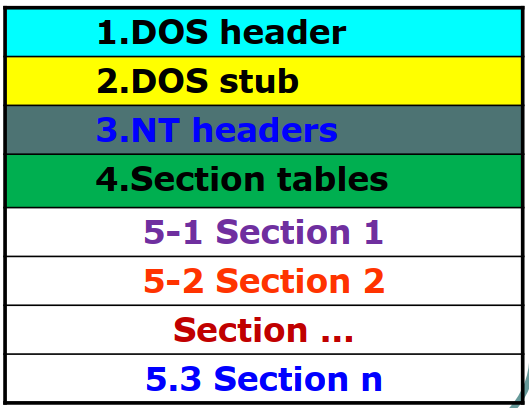
DOS头
DOS头分为两部分,分别是“MZ头部”和“DOS存根”
MZ头部是真正的DOS头部,由于其开始处的两个字节为“MZ”,因此DOS头也可以叫作MZ头。0x3C处有e_lfanew字段,指向后续NT_HEADERS的头部即PE标志。
DOS 残留是一段简单的程序,主要用于输出“This program cannotbe run in DOS mode.”类似的提示字符串。

NT header (PE头)
主要分为 PE标志 Signature ,映像文件头 File Header ,可选映像头Optional Header
Signature(4h),值为50h, 45h, 00h, 00h( PE\0\0)
IMAGE_FILE_HEADER(14h)

重点如下
WORD Machine; //运行平台
WORD NumberOfSections; //文件的区块数
WORD SizeOfOptionalHeader; //IMAGE_OPTIONAL_HEADER32结构的大小
WORD Characteristics; //文件属性
IMAGE_OPTIONAL_HEADER
尽管名字是可选,但是该头部不是一个可选的,而是一个必须存在的头,不可以没有。
内容较多,考试需要关注重点如下
typedef struct _IMAGE_OPTIONAL_HEADER {
+28H DWORD AddressOfEntryPoint; // 指出程序最先执行的代码起始地址(RVA)
+34H DWORD ImageBase; // 当加载进内存时,镜像的第1个字节的首选地址。
// WindowEXE默认ImageBase值为00400000,DLL文件的ImageBase值为10000000,也可以指定其他值。
// 执行PE文件时,PE装载器先创建进程,再将文件载入内存,
// 然后把EIP寄存器的值设置为ImageBase+AddressOfEntryPoint
// PE文件的Body部分被划分成若干区块,这些区块储存着不同类别的数据。
+38H DWORD SectionAlignment;
// SectionAlignment指定了内存中的区块的对齐大小
+3CH DWORD FileAlignment;
// FileAlignment指定了在磁盘文件中的区块的对齐大小
// SectionAlignment必须大于或者等于FileAlignment
DWORD NumberOfRvaAndSizes;
'// 指定DataDirectory的数组个数,由于以前发行的Windows NT的原因,它只能为16。
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
'// 数据目录数组。详见下文。'
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
AddressOfEntryPoint:程序执行的入口RVA地址。该地址是一个相对虚拟地址,简称 EP (EntryPoint),这个值指向了程序第一条要执行的代码
ImageBase:指出文件的优先装入地址。也就是说当文件被执行时,如果可能的话,Windows优先将文件装入到由ImageBase字段指定的地址中,只有指定的地址已经被其他模块使用时,文件才被装入到其他地址中。链接器产生可执行文件的时候对应这个地址来生成机器码,所以当文件被装入这个地址时不需要进行重定位操作,装入的速度最快,如果文件被装载到其他地址的话,将不得不进行重定位操作,这样就要慢一点。
SectionAlignment:当被装入内存时的区块对齐大小。每个区块被装入的地址必定是本字段指定数值的整数倍。
FileAlignment:磁盘上PE文件内的区块对齐大小,组成块的原始数据文件必须保证从本字段的倍数地址开始。对于x86可执行文件,这个值通常是200h或1000h
注 :程序无论是在内存中还是磁盘上,都无法恰好满足SectionAlignment和FileAlignment值的倍数,在不足的情况下需要补0值,这样就导致节与节之间存在了无用的空隙。这些空隙对于病毒之类程序而言就有了可利用的价值。
DataDirectory[16]:数据目录表,这是一个结构体数组,由16个相同的IMAGE_DATA_DIRECTORY结构组成,大小为字节,指向输出表、输入表、资源块等数据。
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress; //数据块的起始RVA
DWORD Size; //数据块的长度
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
16项中考试关键3项如下:
前两项为
- Export Table: The export table address and size.
- Import Table: The import table address and size.

倒数第四项 IAT: The import address table address and size.

详细介绍见后文导入、导出
Section Tables
节表,是紧挨着 PE header 的一个结构
每个节对应着一个节表
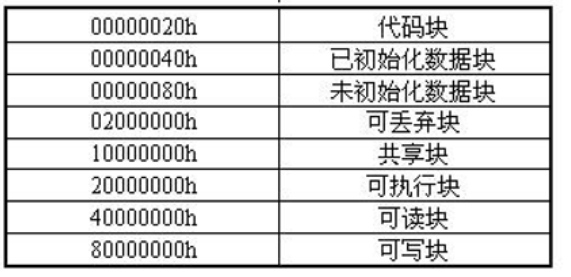
一个节表具体数据结构如下,红圈内为考试重点

节属性规定了节的属性(读写执行权限等,具体如下,了解即可
Section
节紧跟在节表后面,PE文件一般有多个节。典型的有代码节、已初始化数据节、未初始化数据节、引入函数节、导出函数节,详细说明如下。
代码节 .text
该节含有程序的可执行代码
已初始化的数据节 .data
未初始化的数据节 .bss
引入函数节 旧名(考试名) .rdata 现名 .idata
引入函数:是被某模块调用的但又不在调用者模块中的函数。这些函数位于一个或者多个DLL中, 在调用者程序中只保留了函数信息,包括函数名及其驻留的DLL名等。
注:可选头中的DataDirectory中有指定IDT和IAT的项
Import Directory Table(IDT)
引入目录表由一系列的 IMAGE_IMPORT_DESCRIPTOR结构数组组成 ,数量取决于PE文件要使用的DLL的数量,每个结构对应一个DLL文件。在所有DLL对应的结构最后,用一个全0的结构表示数组结束。如下图所示。
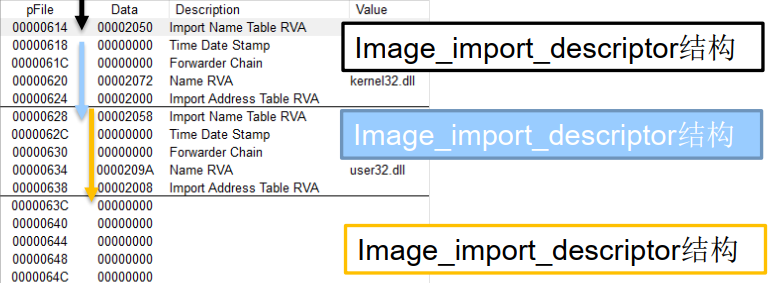
具体结构详见下图
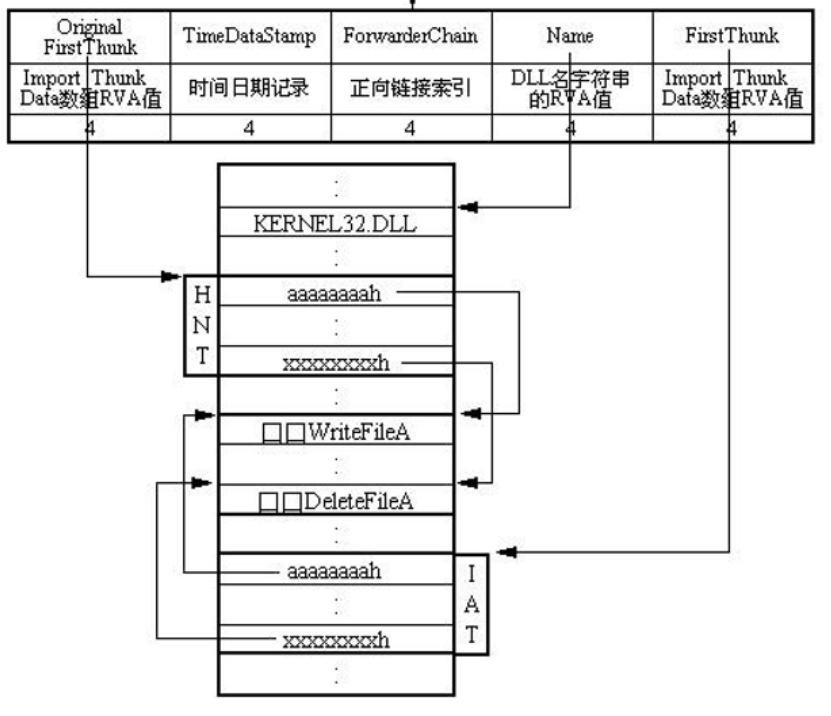
微软官方说明如下
| Offset | Size | Field | Description |
|---|---|---|---|
| 0 | 4 | Import Lookup Table RVA (Characteristics) | The RVA of the import lookup table. This table contains a name or ordinal for each import. (The name "Characteristics" is used in Winnt.h, but no longer describes this field.) |
| 4 | 4 | Time/Date Stamp | The stamp that is set to zero until the image is bound. After the image is bound, this field is set to the time/data stamp of the DLL. |
| 8 | 4 | Forwarder Chain | The index of the first forwarder reference. |
| 12 | 4 | Name RVA | The address of an ASCII string that contains the name of the DLL. This address is relative to the image base. |
| 16 | 4 | Import Address Table RVA (Thunk Table) | The RVA of the import address table. The contents of this table are identical to the contents of the import lookup table until the image is bound. |
Import Name(LookUp) Table
具体如下
| Bit(s) | Size | Bit field | Description |
|---|---|---|---|
| 31/63 | 1 | Ordinal/Name Flag | If this bit is set, import by ordinal. Otherwise, import by name. Bit is masked as 0x80000000 for PE32, 0x8000000000000000 for PE32+. |
| 15-0 | 16 | Ordinal Number | A 16-bit ordinal number. This field is used only if the Ordinal/Name Flag bit field is 1 (import by ordinal). Bits 30-15 or 62-15 must be 0. |
| 30-0 | 31 | Hint/Name Table RVA | A 31-bit RVA of a hint/name table entry. This field is used only if the Ordinal/Name Flag bit field is 0 (import by name). For PE32+ bits 62-31 must be zero. |
IMPORT Hints/Names &DLL names
微软官方说明如下
| Offset | Size | Field | Description |
|---|---|---|---|
| 0 | 2 | Hint | An index into the export name pointer table. A match is attempted first with this value. If it fails, a binary search is performed on the DLL's export name pointer table. |
| 2 | variable | Name | An ASCII string that contains the name to import. This is the string that must be matched to the public name in the DLL. This string is case sensitive and terminated by a null byte. |
| * | 0 or 1 | Pad | A trailing zero-pad byte that appears after the trailing null byte, if necessary, to align the next entry on an even boundary. |
即 Hint为提示的export name pointer table中的index,如果直接对上就命中,否则对export name pointer table进行二分搜索查找。最终得到地址。
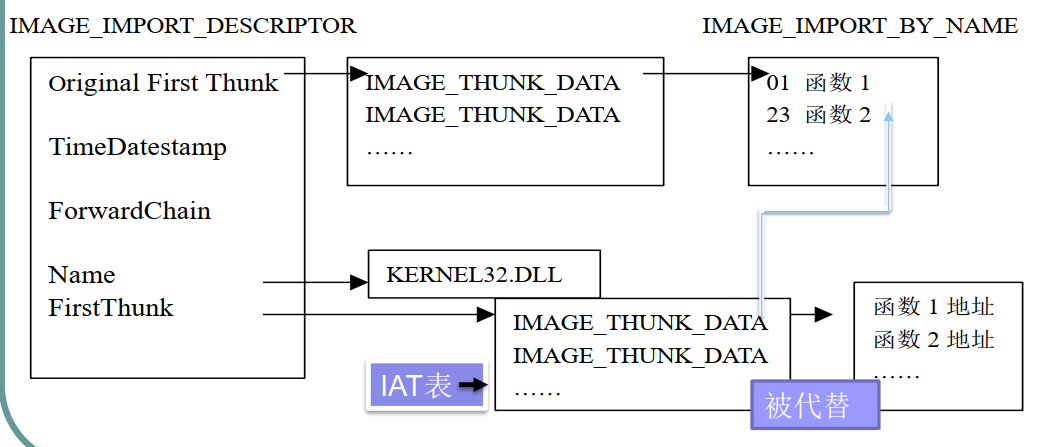
Import Address Table
文件此部分内容与Import Name(LookUp) Table完全相同 ,直到文件被装载进内存里,就被覆盖为对应引入函数的地址。如下图所示
导出函数节 .edata
本文件向其他程序提供调用函数的列表、函数所在的地址及具体代码实现 。
主要结构如下(旧名称) 新名称详见微软官方文档
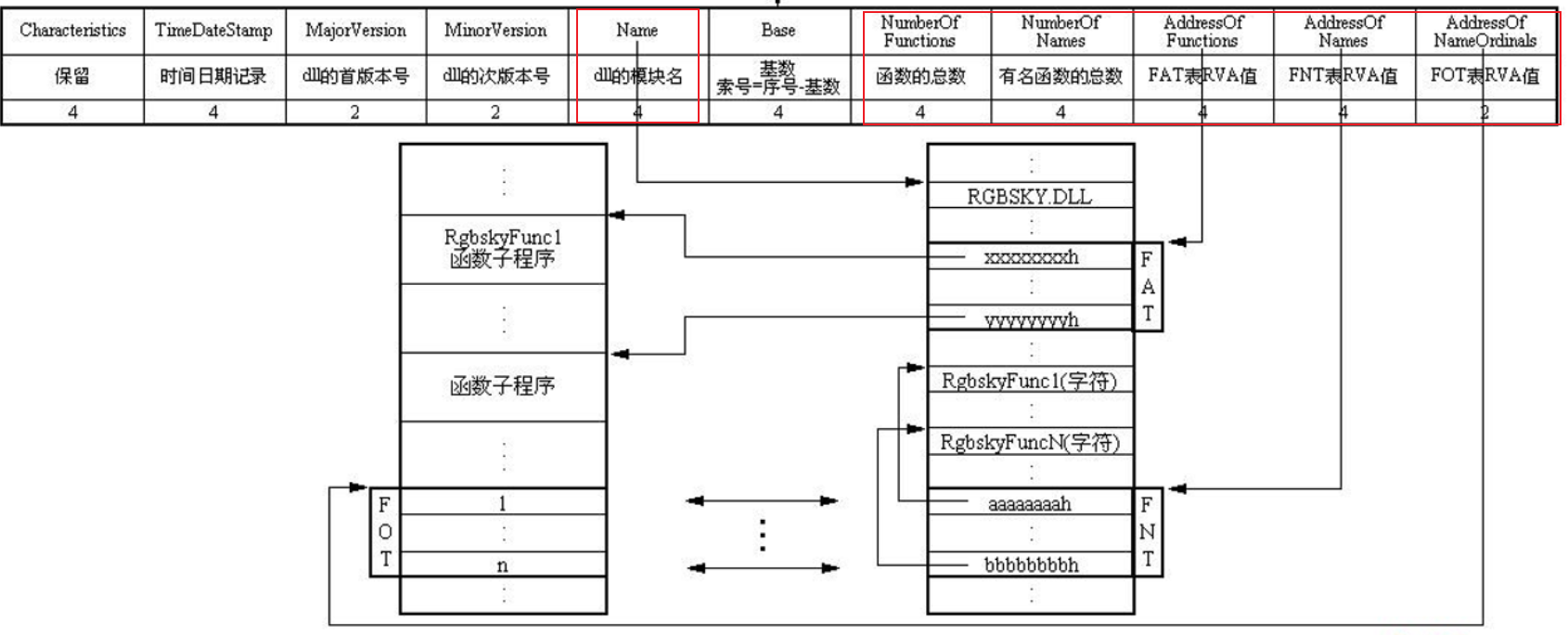
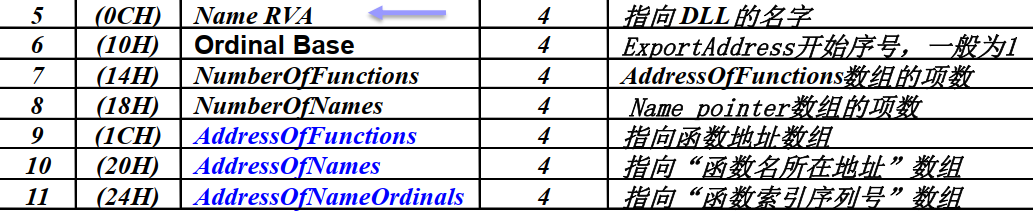
具体解释见下图
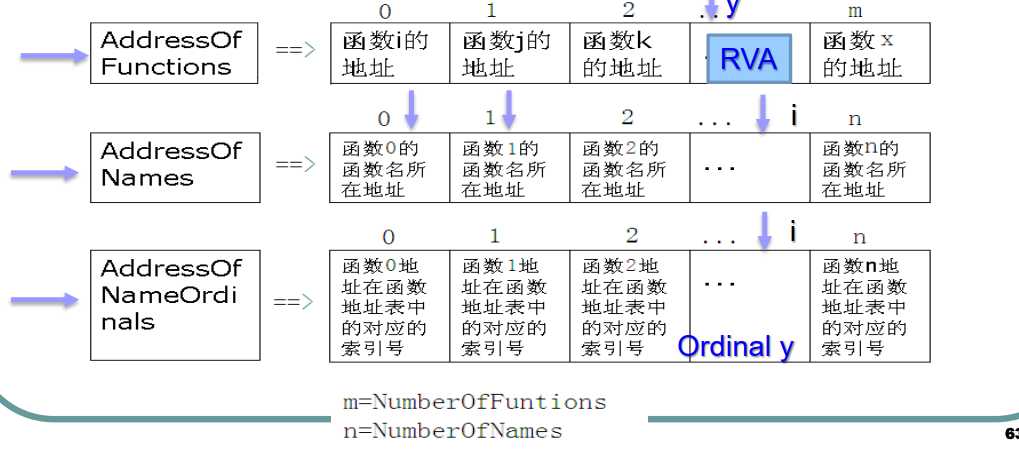
解释:
AddressOfNames指向的数组中存储的值是dll文件名的字符串指针,可以根据此数组找到对应的函数名字,记录下标iAddressofNameOrinals指向的数组的第i个元素,即上一步找到的那个函数的 地址表的ordinal ,假设为yAddressOfFunction指向的数组中第y项,就是要找的函数RVA地址
如果根据函数名HashData 查找函数地址具体步骤如下
- 首先从
AddressOfNames指向的指针数组中找到HashData字符串,并记下该数组序号 i - 然后从
AddressofNameOrinals指向的数组中,定位第i项成员,得到一个Ordinal: y - 从
AddressOfFunction指向的数组中 取出第y项,就是HashData的RVA
注意起始序号,只说了第y项,没有说序号为y
资源节
这个节放有如图标、对话框等程序要用到的资源。
重定位节
重定位节存放了一个重定位表。若装载器不是把程序装到程序编译时默认的基地址时,就需要这个重定位表来做一些调整。
第5章 Windows PE病毒
PE病毒基本概念
感染
在尽量不影响目标程序(系统)正常功能的前提下,使其具有病毒自己的功能。
病毒自己的功能
- 感染模块:被感染程序同样具备感染能力。
- 触发模块:在特定条件下实施相应的病毒功能
- 破坏模块等
按感染类型分类
- 文件感染:将代码寄生在PE文件
- 系统感染 :将代码或程序寄生在Windows操作系统
进行传统文化感染型
感染思路
通过对被感染文件添加新节的方法,如下图所示

关键技术
- 重定位
- 获取API函数的地址
- 获取Kernel32.dll的模块基地址
- 查找其导出表,找到以上
LoadLibraryA和GetProcAddress的地址并保存
- 检索感染目标
- 感染
重定位
-
病毒为什么需要重定位?
正常写程序时,不会关心变量的位置。程序在编译的时候,变量在内存中的位置由编译程序计算。通过变量名访问变量,编译程序会将相应地址填入对应指令。而病毒代码在运行时,访问数据时,不能使用编译程序计算的地址,因为病毒装载位置并不是编译时预期的地址,而是与预期地址有一定偏移。我们需要通过重定位,计算这段偏移,对病毒代码访问的地址,进行纠正。
-
重定位方法
逐一硬编码过于繁琐,不常用。主要学习采用call指令等,使病毒代码在运行过程中自我重定位的方法。
利用call指令将下一条指令运行时真实地址压栈的特点,获取下一条指令的真实地址(下图中的delta真实地址),另外,通过offset delta取得delta的预期地址,从而计算矫正值=下一条指令真实地址-下一条指令预期地址。后面需要访问其他变量,比如var1时,就可以利用纠正值及对应预期地址:var1运行时真实地址=var1预期地址+纠正值。
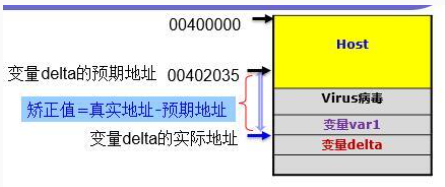
call delta ;这条语句执行之后,堆栈顶端为delta在内存中的真正地址
delta:
pop eax ;将delta在内存中的真正地址存放在eax寄存器中
sub eax,offset delta ;计算得到矫正值
call作用详见本文10.1章
获取API函数的地址
实现弹窗、读写文件、检索文件等操作,我们需要使用Windows自带的API。
系统加载PE文件的时候,会将其引入的特定DLL中的函数的运行地址装入PE的引入函数表中,那么系统是如何为PE引入表填入正确的函数地址的呢?系统解析引入DLL的导出函数表,根据函数名称或序号,得到相应引出函数的RVA,加上模块首地址后,就可以得到API函数运行时的VA地址。
Kernel32.dll中的函数 LoadLibraryA装入任意一个DLL,函数GetProcAddress可以获得这个DLL中函数的地址。
所以只要有以上的两个API就可以获得其他DLL中的函数。
获取Kernel32.dll的模块基地址
主要掌握两个方法
- 栈内获得某个kernel32的地址后暴力检索
- 从fs寄存器访问teb-peb-ldr双链
栈内获得某个kernel32的地址后暴力检索
系统打开一个可执行文件时,它会调用Kernel32.dll中的CreateProcess函数,CreateProcess函数在完成应用程序装载后,会先将返回地址压入到堆栈顶端。当该应用程序结束后,会将返回地址弹出放到EIP中,继续执行。
而这个返回地址正处于KERNEL32.DLL的地址空间之中。这样,利用PE文件格式的相关特征(如03C偏移处内容存放着“PE”标志的内存地址等),在此地址的基础上往低地址方向逐渐搜索(SectionAlignment为10000H,所以一次减10000H),必然可以找到KERNEL32.DLL模块的首地址。不过这种暴力搜索方法比较费时,并且可能会碰到一些异常情况。
从fs寄存器访问teb-peb-ldr双链

注:需要通过Flink指针,遍历链表,判断第几个是kernel32.dll,最后再取基地址
详见链接 中 0x2 基于PEB搜索
获取函数 LoadLibraryA和GetProcAddress
具体步骤详见本文第4章导出函数节内容,不再赘述
获取其他API地址
Kernel32.dll中的函数 LoadLibraryA装入任意一个DLL,函数GetProcAddress可以获得这个DLL中函数的地址。只要有以上的两个API就可以获得其他DLL中的函数。
增加新节的感染步骤
判断目标文件开始的两个字节是否为“MZ”。判断PE文件标记“PE”。判断感染标记,如果已被感染过则跳出继续执行HOST程序,否则继续。获得Directory(数据目录)的个数,(每个数据目录信息占8个字节)。得到节表起始位置。(Directory的偏移地址+数据目录占用的字节数=节表起始位置)得到目前最后节表的末尾偏移(紧接其后用于写入一个新的病毒节)节表起始位置+节的个数*28H (每个节表占用的字节数28H)=目前最后节表的末尾偏移。开始写入节表和病毒节修正文件头信息
第6章 宏病毒与脚本病毒
宏的概念
宏就是能组织到一起作为独立的命令使用的一系列word命令,可以实现任务执行的自动化,简化日常工作 。
宏病毒的概念
存在于数据文件或模板中, 使用宏语言编写,利用宏语言的功能将自己寄生到其他数据文档。
宏病毒的传播路线
- 单机:单个Office文档—〉 Office文档模板—〉 多个Office文档
- 网络:电子邮件居多
宏病毒代码的主要部分
- 自我保护
- 禁止提示信息
- 屏蔽命令菜单,不允许查看宏
- 隐藏宏的真实病毒代码
- 感染代码导出 将病毒代码导出保存
- 代码导入 将病毒代码导入文档
脚本病毒感染文件
脚本病毒是直接通过自我复制来感染文件的,病毒中的绝大部分代码都可以直接附加在其他同类程序的中间 。
脚本病毒对抗反病毒软件
-
自加密
-
巧妙运用Execute函数
有些杀毒软件检测VBS病毒时,会检查程序中是否声明使用了
FileSystemObject对象,如果采用了,这会发出报警。如果病毒将这段声明代码转化为字符串,然后通过Execute(String)函数执行,就可以躲避某些反病毒软件。 -
改变某些对象的声明方法

- 直接关闭反病毒软件
VBS脚本功能强大,它可以查看系统正在运行的进程或服务,尝试关闭和删除相应的关键程序。
第7章 木马与后门
特洛伊木马:是指一类看起来具有正常功能,但实际上隐藏着很多用户不希望功能的程序。通常由控制端和被控制端两端组成。
- 具有远程控制、 信息窃取、 破坏等功能的恶意代码 。
- 特点:欺骗性、 隐藏性、 非授权性、 交互性
木马分类
- 远程控制型木马

-
信息获取型木马
![image-20220606203119670]()
-
破坏型木马


木马植入方式
- 网页挂马植入 自动下载安装
- 电子邮件植入 附件形式,打开附件被植入
- 文档捆绑植入 office文档、 pdf文档漏洞等
- 伪装欺骗植入 更改后缀名(Unicode翻转字符)、图标伪装
- 捆绑植入 EXE捆绑、文档嵌入、多媒体文件、电子书植入
- 其他
- 特定U盘植入(故意丢弃、或者工作U盘、数据拷贝等)
- 社会工程
木马通信方式
-
传输通道构建信息 IP地址、端口等信息、第三方网站地址
-
建立通信连接的方式
-
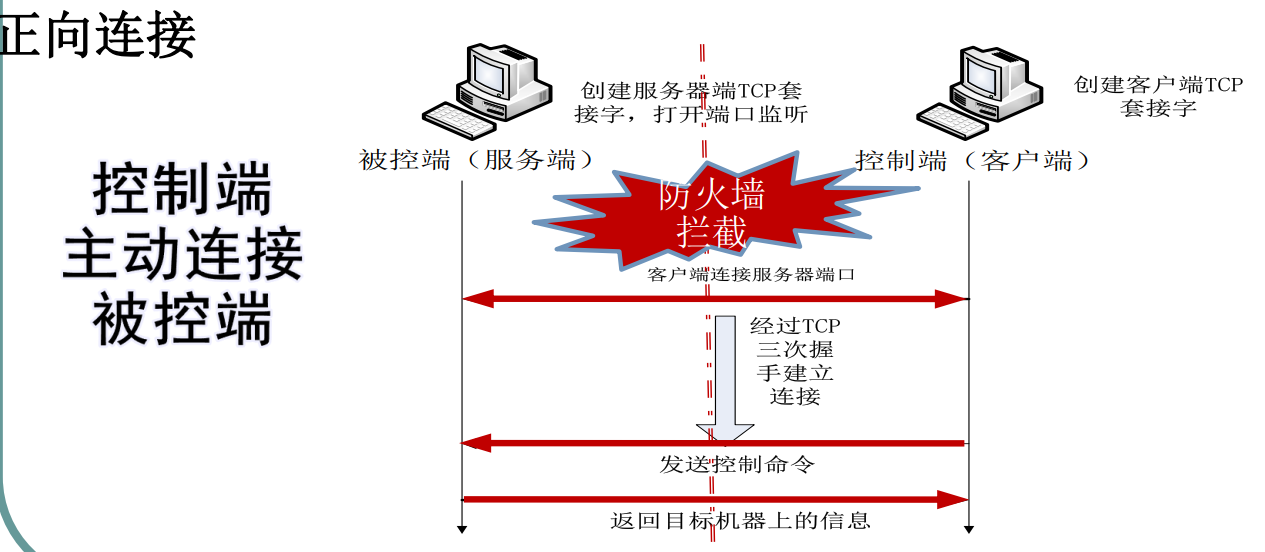
正向连接
![image-20220606204822484]()
优点
- 攻击者无需外部IP地址
- 木马样本不会泄露攻击者IP地址
缺点
- 可能被防火墙阻挡
- 被攻击者必须具备外部IP地址
- 定位被攻击者相对困难
- 被攻击者IP是否变化
- 目标主机何时上线
-
反向连接
-
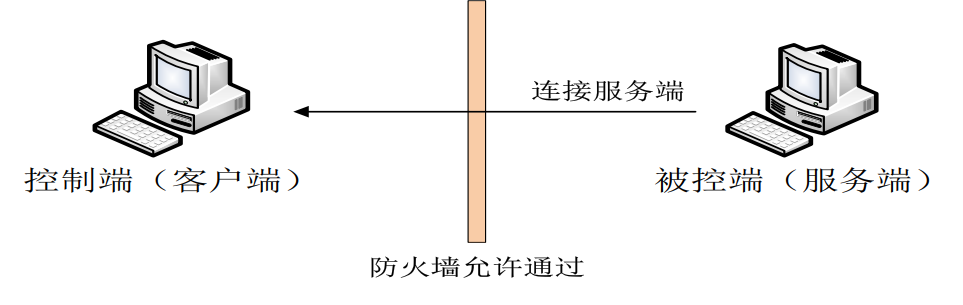
直接反向连接
![image-20220606210123913]()
优点
- 通过防火墙相对容易
- 攻击目标随时上线、随时控制
- 可以控制局域网内的目标
缺点
- 样本会暴露控制服务器信息(域名或IP)
- 攻击者通常应当具有外部IP
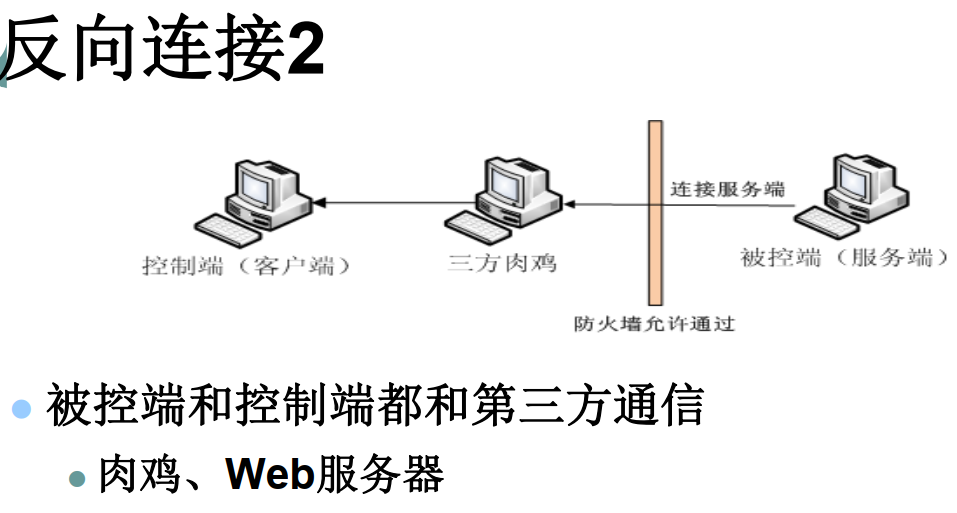
2.通过肉鸡中转反向连接
![image-20220606210556014]()
优点:可绕过防火墙,自动连接上线,不易被发现(代理)
缺陷:肉鸡稳定性需要保障
-
-
第8章 蠕虫
莫里斯蠕虫

蠕虫和病毒的区别
计算机病毒:一组能够进行自我传播、需要用户干预来触发执行的破坏性程序或代码
网络蠕虫:一组能够进行自我传播、不需要用户干预即可触发执行的破坏性程序或代码
蠕虫的四个主要功能
信息收集
主要完成对本地和目标节点主机的信息汇集
扫描探测
主要完成对具体目标主机服务漏洞的检测
攻击渗透
利用已发现的服务漏洞实施攻击[控制权获取]
自我推进
完成对目标节点的感染[蠕虫主体程序传输]
第9章 恶意代码的检测技术
恶意代码的检测是将检测对象与恶意代码特征(检测标准)进行对比分析,定位病毒程序或代码,或检测恶意行为 。
特征值检测
自己理解:对特定病毒的特有的字符串或二进制串做匹配检测
病毒特征值是反病毒软件鉴别特定计算机病毒的一种标志。通常是从病毒样本中提取的一段或多段字符串或二进制串 。
- 优点:检测速度快、 误报率低等优点,为广大反病毒厂商所采用,技术也比较成熟。
- 缺点:只能检测已知恶意代码。容易被免杀绕过 。
校验和检测
自己的理解:检测文件和系统数据是否为预期的正常状态
在文件使用/系统启动过程中,检查检测对象的实际校验和与预期是否一致,因而可以发现文件/引导区是否感染 。

检测对象
- 文件头部
- 文件属性
- 文件内容
- 系统数据
优缺点
优点
- 方法简单
- 能发现未知病毒
- 目标文件的细微变化也能发现
缺点
- 必须预先记录正常文件的校验和[预期]
- 误报率高
- 不能识别病毒名称
- 效率低
启发式扫描技术
自己的理解:对可疑的行为特征进行扫描
主要步骤
- 定义通用可疑特征(指令序列或行为,如格式化磁盘、调用敏感API函数等)
- 对上述功能操作将被按照安全和可疑的等级进行排序,授以不同的权值
- 鉴别特征,如果程序的权值总和超过一个事先定义的阈值,则认为 “发现病毒”
优缺点
优点:能发现未知病毒
缺点:误报率高
虚拟机检测技术
自己的理解:内存中模拟封闭沙箱执行待查文件
因为部分病毒是加密病毒,真实代码被压缩或加密,但最终需要在内存中还原 ,所以需要虚拟机检测
具体步骤:在反病毒系统中设置的一种程序机制,它能在内存中模拟一个小的封闭程序执行环境,所有待查文件都以解释方式在其中被虚拟执行 。
优点
- 有效处理加密类病毒
- 虚拟机技术+特征值扫描,准确率更高
- 虚拟机技术+启发式扫描,有利于检测未知变形病毒
主动防御技术
自己的理解:检测程序的程序流逻辑关系,敏感风险时拦截供用户自行选择
主动防御检测技术有时也被称为行为监控等技术 。
- 动态监视所运行程序调用各种应用编程接口(API)的动作,自动分析程序动作之间的逻辑关系,自动判定程序行为的合法性 。
- 监控应用程序的敏感行为,并向用户发出提示,供用户选择。
如下图
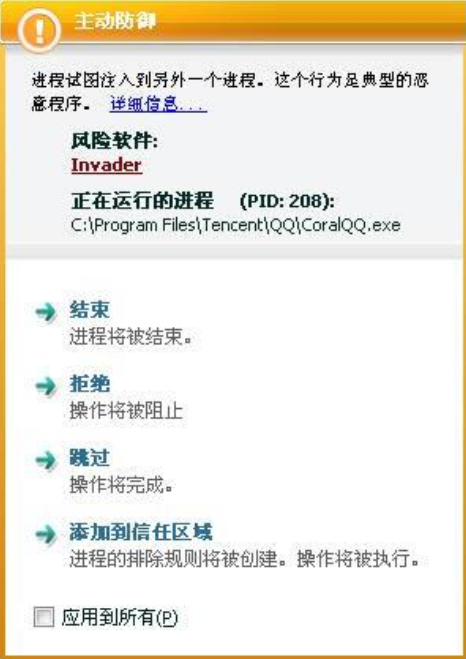
优点:可发现未知恶意软件、可准确地发现未知恶意软件的恶意行为。
缺点:可能误报警、不能识别恶意软件名称,以及在实现时有一定难度 。
第10章 软件缺陷与漏洞机理基础
软件漏洞定义及要素
漏洞(Vulnerability ),通常也称脆弱性, RFC2828将漏洞定义为“系统设计、实现或操作管理中存在的缺陷或弱点,能被利用而违背系统的安全策略”。攻击者利用漏洞可以获得计算机系统的额外权限。
要素:
- 受影响的软件版本
- POC-验证漏洞存在的代码
- 漏洞触发的条件
- 攻击能力
漏洞分类
- 获取访问权限漏洞
- 权限提升漏洞
- 拒绝服务漏洞
- 恶意软件植入漏洞
- 数据丢失或者泄露漏洞
软件漏洞生命周期
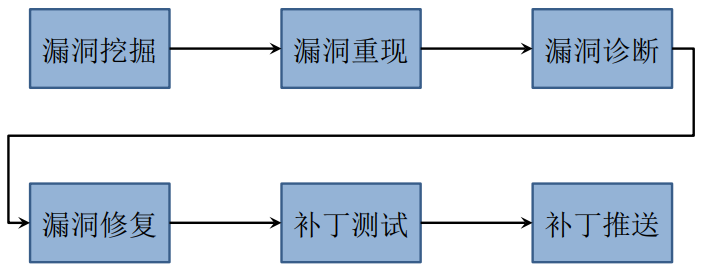
第10.1章 栈缓冲区溢出
函数调用类型
__cdecl
- 在后面的参数先进入堆栈
- 在函数返回后,调用者要负责清除堆栈.所以这种调用常会生成较大的可执行程序
详见微软官方文档
__stdcall
- 在后面的参数先进入堆栈
- 被调用的函数在返回前自行清理堆栈,所以生成的代码比cdecl小
详见微软官方文档
__fastcall
- 在参数列表中从左到右找到的前两个 DWORD 或更小的参数在 ECX 和 EDX 寄存器中传递;所有其他参数从右到左在堆栈上传递。
- 被调用的函数在返回前自行清理堆栈
详见微软官方文档
函数调用过程堆栈
注:此处所讲的堆栈,是指32位系统中程序为每个线程分配的默认堆栈,用以支持程序的运行,而不是指程序员为了实现算法而自己定义的堆栈。
明确以下几点基本概念
-
程序的堆栈是由处理器直接支持的,在intel x86 下,堆栈的内存地址是由高地址向低地址扩展;因此栈顶地址是不断减小的,越后入栈的数据,地址越低。
-
32位系统中,堆栈中每个数据单元大小为4字节。小于等于 4 字节的数据,比如字节、字、双字和布尔型,在堆栈中都是占 4 个字节的;大于 4 字节的数据在堆栈中占 4 字节整数倍的空间。
-
关于EBP,ESP寄存器。ESP寄存器总是指向栈顶
push指令 先将数据压入堆栈,再 esp=esp-4
pop指令 向将esp所指向的数据取出,再esp=esp+4
-
堆栈中存储了函数的参数,函数的局部变量,寄存器的值(用以恢复寄存器),函数的返回地址等。这些数据是按照一定的顺序组织在一起的,我们称之为一个堆栈帧(Stack Frame)。一个堆栈帧对应一次函数的调用。在函数开始时,对应的堆栈帧已经完整地建立了(所有的局部变量在函数帧建立时就已经分配好空间了,而不是随着函数的执行而不断创建和销毁的);在函数退出时,整个函数帧将被销毁。
-
函数的调用者称为 Caller(调用者),被调用的函数称为 Callee(被调用者)
以此代码为例,从main函数开始跟踪堆栈
int foo1(int m, int n)
{
int p = m * n;
return p;
}
int foo(int a, int b)
{
int c = a + 1;
int d = b + 1;
int e = foo1(c, d);
return e;
}
int main()
{
int result = foo(3, 4);
return 0;
}
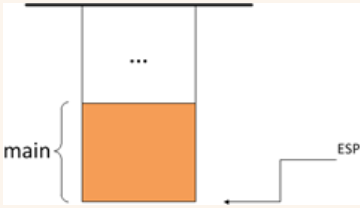
堆栈的建立
从main函数的第一行代码 int result = foo(3, 4); 开始跟踪,此时main函数堆栈帧已经在堆栈中了,如下图所示
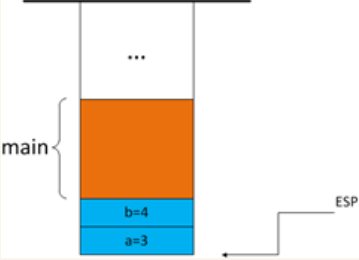
参数入栈
当foo函数被调用时,首先将参数入栈,此处为__stdcall,在后面的参数先进入堆栈,所以先将b=4压入栈,再将a=3压入栈
返回地址入栈
因为函数调用结束后,需要回到main函数执行下一条语句继续执行,所以需要将下一条指令的地址入栈。假设当前"call foo"指令的地址是 0x00171482, 由于 call 指令占 5 个字节,那么下一个指令的地址为 0x00171487,0x00171487 将被压入堆栈。
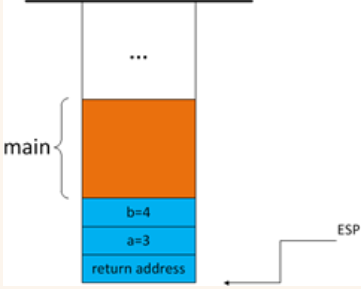
跳转到被调用函数执行
返回地址入栈后,代码跳转到foo中执行。
EBP 入栈
在foo函数中,首先将EBP压入栈,再将 EBP=ESP 。
因为刚进入foo函数时,EBP还是main函数的EBP,用来访问main函数的参数和局部变量,所以先压入栈中,方便返回后恢复旧值,继续执行main函数。然后将EBP=ESP,即将EBP更新为foo函数的基址,用来访问foo函数的参数和局部变量。
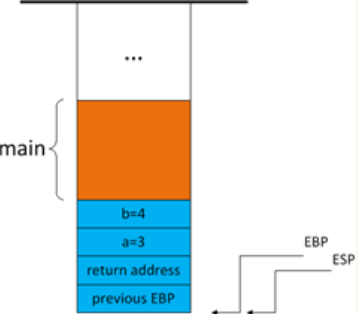
注意到,[EBP+4]就是函数返回值,[EBP+8]以及更高位的都是函数的参数
为局部变量分配地址
foo函数为局部变量分配地址,将esp减去某个值,直接为所有局部变量分配空间,注:编译器为局部变量分配的空间往往大于实际所需。
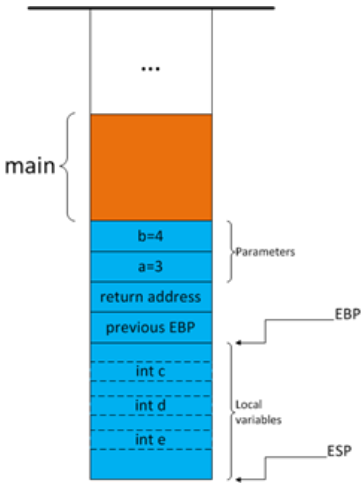
注:在 debug 模式下,编译器为局部变量分配的空间远远大于实际所需,而且局部变量之间的地址不是连续的(此次尝试间隔 8 个字节)
通用寄存器入栈
将函数中使用的通用寄存器入栈,暂存起来,以便函数结束时恢复。如在 foo 函数中用到的通用寄存器是 EBX,ESI,EDI,将它们压入堆栈。
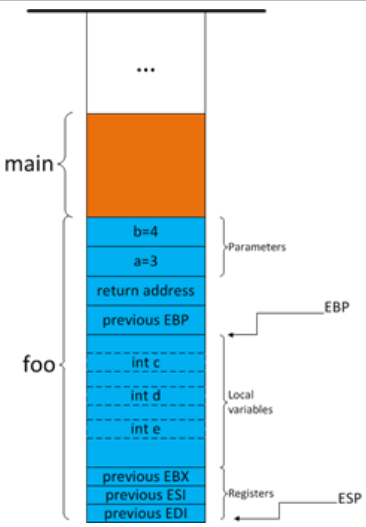
至此完整的堆栈帧就建立完成了
堆栈的特性分析
-
一个完整的堆栈帧建立起来后,在函数执行的整个生命周期中,它的结构和大小都是保持不变的;不论函数在什么时候被谁调用,它对应的堆栈帧的结构也是一定的。
-
在 A 函数中调用 B 函数,对应的,是在 A 函数对应的堆栈帧 “下方” 建立 B 函数的堆栈帧。例如在 foo 函数中调用 foo1 函数,foo1 函数的堆栈帧将在 foo 函数的堆栈帧下方建立。如下图所示
![image-20220604134829341]()
-
函数用 EBP 寄存器来访问参数和局部变量。我们知道,参数的地址总是比 EBP 的值高,而局部变量的地址总是比 EBP 的值低。而在特定的堆栈帧中,每个参数或局部变量相对于 EBP 的地址偏移总是固定的。因此函数对参数和局部变量的的访问是通过 EBP 加上某个偏移量来访问的。比如,在 foo 函数中,EBP+8 为第一个参数的地址,EBP-8 为第一个局部变量的地址。
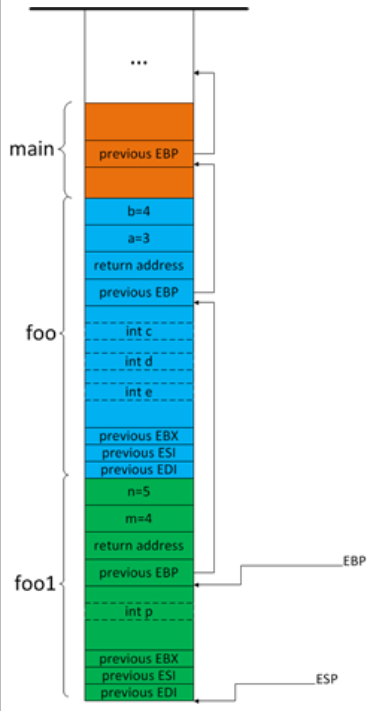
函数返回值的传递
- 如果返回值小于等于 4 字节,函数将把返回值赋予 EAX 寄存器,通过 EAX 寄存器返回。例如返回值是字节、字、双字、布尔型、指针等类型,都通过 EAX 寄存器返回。
- 如果返回值等于 8 字节,函数将把返回值赋予 EAX 和 EDX 寄存器,通过 EAX 和 EDX 寄存器返回,EDX 存储高位 4 字节,EAX 存储低位 4 字节。例如返回值类型为__int64 或者 8 字节的结构体通过 EAX 和 EDX 返回。
- 如果返回值为 double 或 float 型,函数将把返回值赋予浮点寄存器,通过浮点寄存器返回。
堆栈帧的销毁
函数在返回前清理堆栈帧,步骤如下
- 从堆栈中弹出先前的通用寄存器的值,恢复通用寄存器。
- ESP 加上某个值,回收局部变量的地址空间(加上的值和堆栈帧建立时分配给局部变量的地址大小相同)。
- 从堆栈中弹出先前的 EBP 寄存器的值,恢复 EBP 寄存器。
- 从堆栈中弹出函数的返回地址,准备跳转到函数的返回地址处继续执行。
- ESP 加上某个值,回收所有的参数地址。
前面 1-5 条都是由 callee 完成的,第6条由函数调用约定决定。stdcall和fastcall中被调用的函数在返回前自行清理,__cdecl调用者要负责清理。
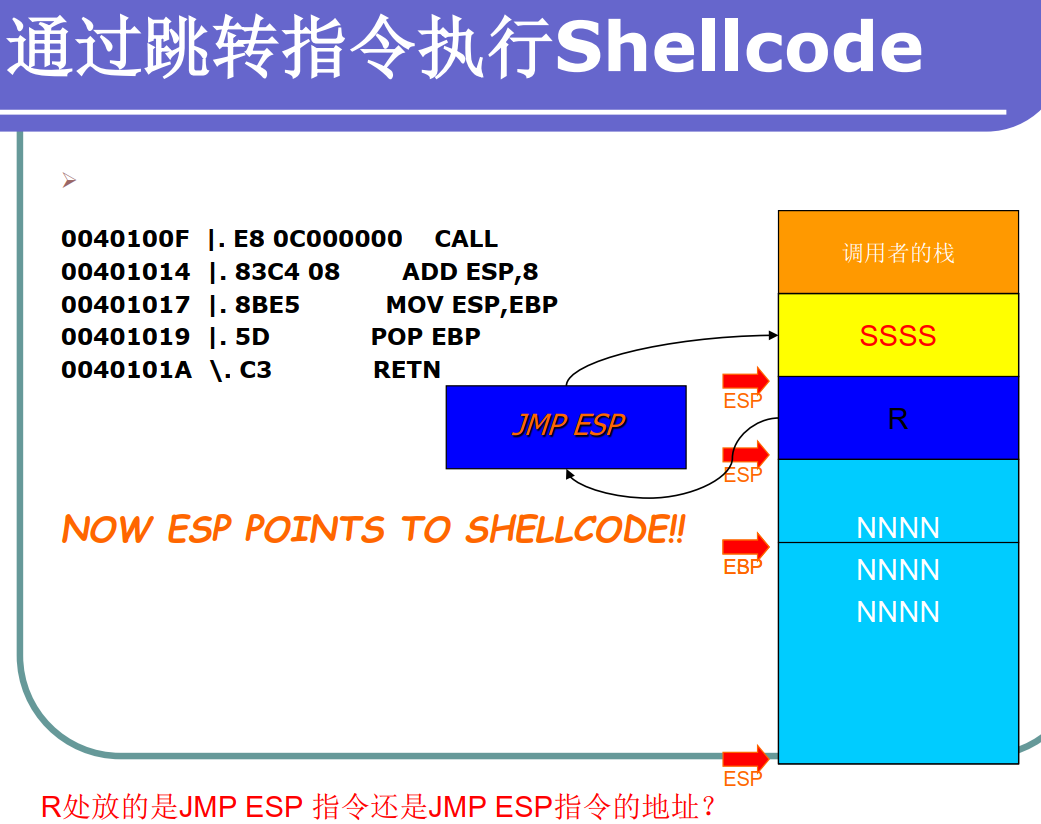
栈溢出的利用可以考虑
-
覆盖返回地址为 jmp esp地址再执行shellcode
![image-20220604144931542]()
-
覆盖SEH中handler
SEH为结构化异常处理,一般在栈空间附近,可以被覆盖到 。
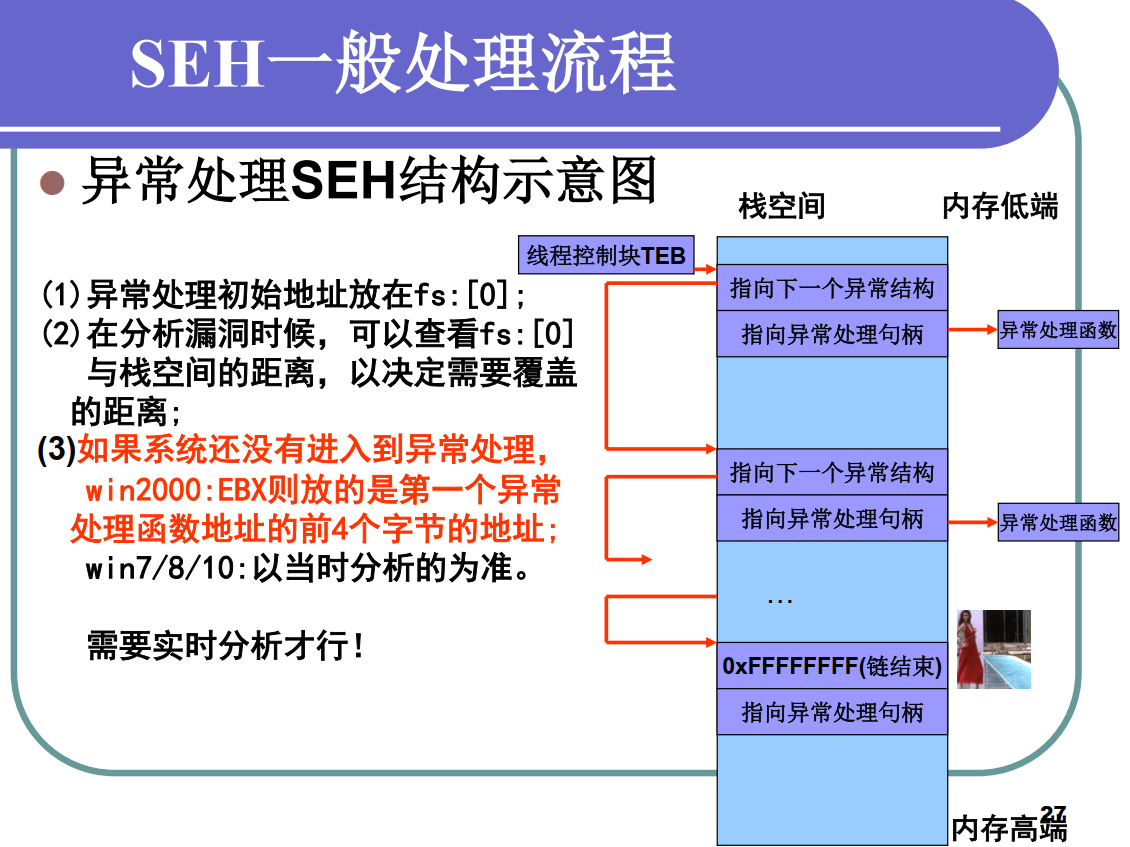
SEH保存在栈中,对其进行覆盖 。Exploit使得返回前异常触发,程序流进入异常处理 。异常处理句柄赋值为
类似于JMP ESP的跳转指令,指向ShellCode 。
第10.2章 堆溢出和格式化字符串溢出
堆概述
堆是用于存放程序运行中请求操作系统分配给自己的内存段
- 大小并不固定,可动态扩张或缩减
- 操作系统采用动态链表管理
- 内存不一定连续
- 每一个进程有自己的堆
- 用new/malloc/HeapAlloc 等指令申请堆空间
- 用delete/free/HeapFree…指令释放堆空间
堆结构分为 堆表+堆块
- 堆表位于堆区的起始位置,主要作用是用来索引堆区中所有堆块的位置,堆表分为两种 空表和块表(空闲双向链表(Freelist),快速单向链表(Lookaside))
- 堆块就是用来提供程序员申请堆空间的,结构为 “块首”+“块身”
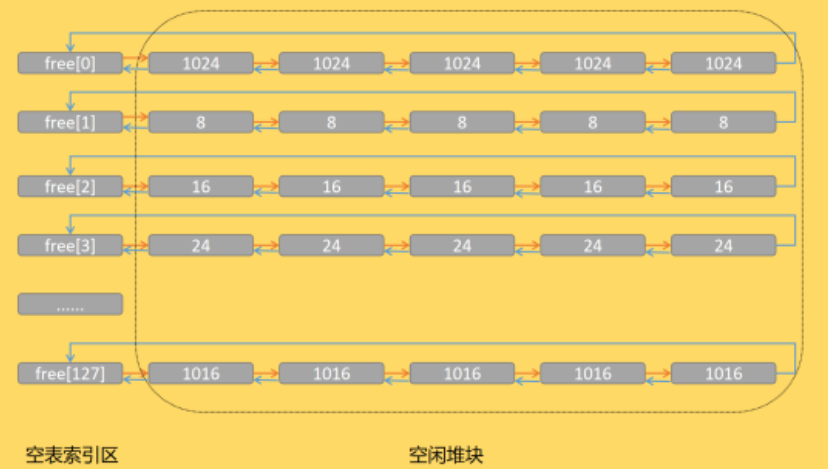
空闲双向链表(Freelist)
空闲双向链表有“段表索引”,“虚表索引”,“空表使用标识”,“空表索引区”组成。我们需要特别了解的是“空表索引区”这个内容。“空表索引区”由128项指针数组组成。这对指针用来将空闲堆组织成双向链表。根据堆块的大小不同存放的指针数组也是不同。索引由“0”编号开始,即128项的标号为free[0]~free[127]。当中free[1]链接8字节的堆块,free[2]链接16字节的堆块。即每项链接的堆块大小均比其前一项链接的堆块增大8字节。值得注意的是free[0]链接的是大于等于1024字节的堆块。详细如下图展现:
快速单项链表(Lookaside)
快速单项链表大体与双向链表相同,也是128项,区别在于快速单项链表单项链接,且链中的堆不会发生合并现象。且每项最多4个节点。详细如下图:

堆块
堆块就是用来提供程序员申请堆空间的,结构为 “块首”+“块身”
- 块首 :头部几个字节,用来表示自身信息(大小、是否空闲等)
- 块身:实际数据存储区域,紧跟 块首
占用态示意图
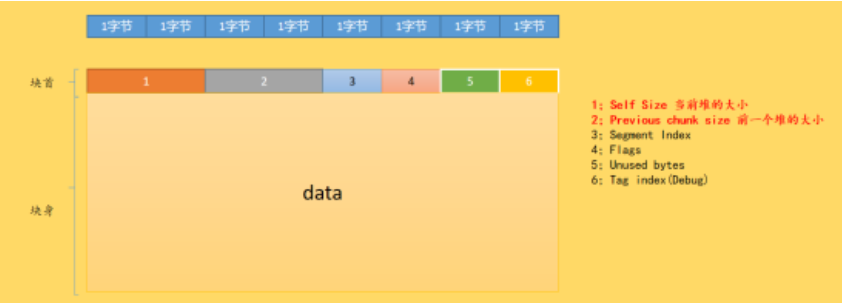
空闲态示意图
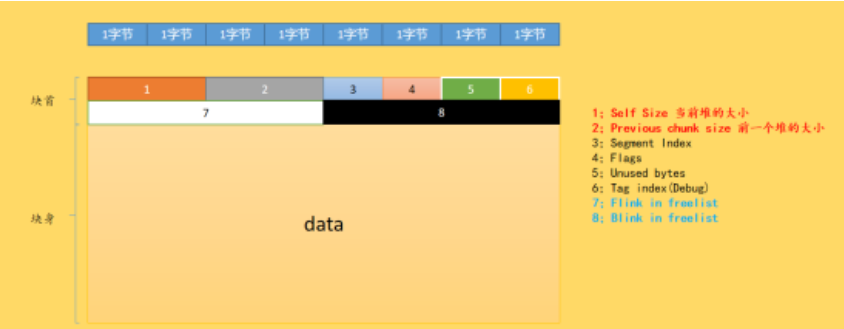
注意到空闲态中,块首添加了8字节的指针对, Flink(向前指针),Blink(向后指针)
堆溢出利用 unlink
在软件安全课上的堆溢出利用类似于linux下的unlink,具体如下
在双向链表中如果需要申请使用p1、p2指向的内存,或者释放p1、p2指向的内存,如下将左图变为右图。

需要进行的堆操作如下图所示
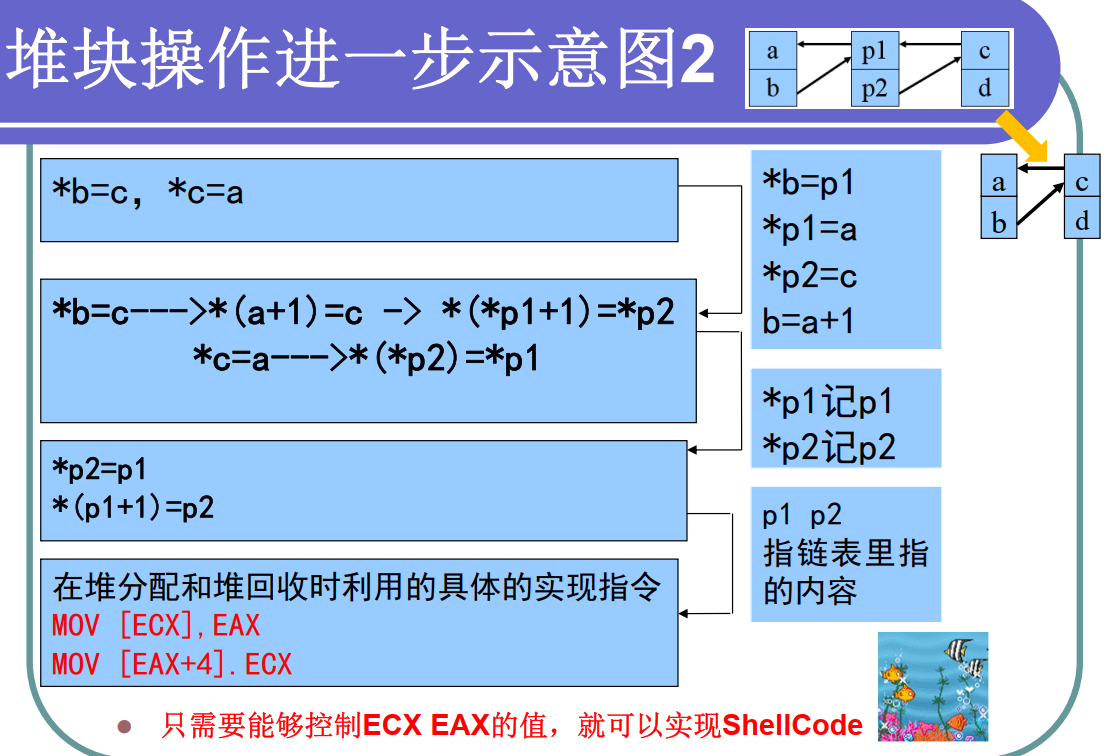
例如下所示:

分配完buf1之后向其中拷贝内容,拷贝的内容大小超过buf1的大小,即16字节,就会发生溢出,如果覆盖掉两个4字节的指针,而下一次分配buf2之前又没有把buf1释放掉的话,就会把一个4字节的内容写入一个地址当中,而这个内容和地址都是能够控制的,这样就可以配合其他控制eip的漏洞(如栈溢出等)控制函数的流程转向shellcode。
以上操作被称为 what \(\rarr\)where 操作 或 Dword Shoot
利用 MOV [ECX],EAX 和 MOV [EAX+4], ECX完成任意地址写入任意值的控制
堆喷射
堆喷射是在 shellcode 的前面加上大量的slide code(跳板指令),组成一个注入代码段。然后向系统申请大量内存,并且反复用注入代码段来填充。这样就使得内存被大量的注入代码占据。然后通过结合其他漏洞控制程序流,使得程序执行到堆上,最终将导致shellcode的执行。
向堆中注入大量数据,使得数据填满特定内存地址空间,当栈溢出时可以引导EIP到堆的空间 。
- Injected data=slide code(滑板指令)+shellcode
- 可以是堆和栈结合的攻击方式
Q1 : 为什么需要在shellcode前面加上silde code?
如果想要成功执行shellcode,必须要准确的跳转到shellcode的第一条指令开始执行,如果整个空间都被填充为shellcode,精确跳转到shellcode的第一条指令的几率反而很低。如果在shellcode前面加上很长一段slide code,那么只要跳转到slide code范围内的任意地址,最后都能执行shellcode。
Q2 :为什么是 0x0c0c0c0c?
一是因为堆的分布不均衡(存在碎片),所以最先分配的一些堆块的地址可能是无规律的,但是如果大量的分配堆块的话,那么就会出现稳定的地址分布。也就是说内存中碎片过多,必须喷射到更高的地址才能使 exploit 更稳定。
通常在申请的内存超过200M(0xc8000000 > 0x0c0c0c0c),0x0c0c0c0c被含有shellcode的内存片覆盖,只要slide code能够击中0x0c0c0c0c的位置,shellcode最后都能被执行。
正常情况下的堆布局:
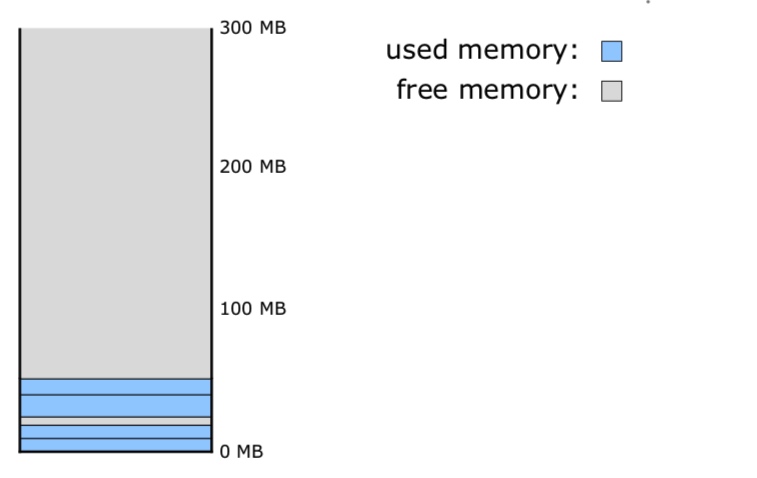
堆喷射后的布局
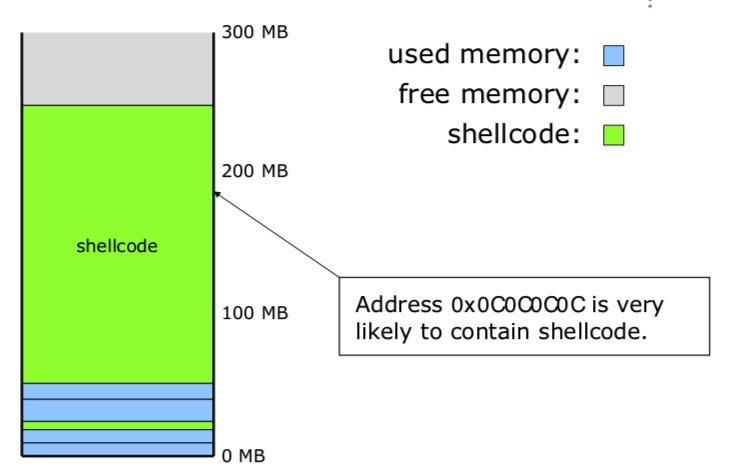
堆喷射的检测与防范
- 如果发现应用程序的内存大量增加(设置阈值),立即检测堆上的数据,看是否包含大量的slidecode
- 当浏览器的脚本解释器开始重复申请堆的时候,监控模块可以记录堆的大小、内容和数量,如果这些重复的堆请求到达了一个阀值或者覆盖了指定的地址(譬如0x0C0C0C0C, 0x0D0D0D0D等等),监控模块立即阻止脚本的执行
- 对于一些利用脚本( Javascript Vbscript Actionscript)的进行Heap Spray攻击的情况,可以通过hook脚本引擎,分析脚本代码,根据一些Heap Spray常见特征,检测是否受到Heap Spray攻击
- 开启DEP
Use After Free
Use After Free 就是其字面所表达的意思,当一个内存块被释放之后再次被使用。
- 内存块被释放后,若其对应的指针没有被设置为NULL,指向这一块内存的指针被称为 dangling pointer 野指针
- 若操作系统将这部分已经释放的内存重新分配给另外一个进程,而原来的程序重新引用现在的野指针,则将产生无法预料
- 野指针所指向的内存已经完全是不同的数据,若原程序继续往野指针所指向的内存地址写入数据,这些和原程序不相关的数据将被损坏,进而导致不可预料的程序错误。
hakcer可以利用UAF,向野指针指向的内存写入构造的shellcode等方式改变程序执行流,获得程序控制权。
格式化字符串溢出
以 printf() 为例,不定参数输入,且不检查参数的个数。
格式化控制符说明如下
- %d 用于读取10进制数值
- %x 用于读取16进制数值
- %s 用于读取字符串值
- %n不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量,例子如下
printf("%s%n", "01234", &n); // n = 5
格式字符串漏洞发生的条件就是格式字符串要求的参数和实际提供的参数不匹配。
-
为什么可以通过编译?
- 因为
printf()函数的参数被定义为可变的。 - 为了发现不匹配的情况,编译器需要理解
printf()是怎么工作的和格式字符串是什么。然而,编译器并不知道这些。 - 有时格式字符串并不是固定的,它可能在程序执行中动态生成。
- 因为
-
printf()函数自己可以发现不匹配吗?
printf()函数从栈中取出参数,如果它需要 3 个,那它就取出 3 个。除非栈的边界被标记了,否则printf()是不会知道它取出的参数比提供给它的参数多了。然而并没有这样的标记。
所以在没有压参数的时候,构造payload,利用多余%x,即可查看栈上任意内存地址内容,造成数据泄露。
利用 %n 还可修改任意栈上内容,从而修改返回地址eip,实现控制程序执行流
10.3 整数溢出
整数在内存里面保存在一个固定长度的空间内,它能存储的最大值和最小值是固定的,如果我们尝试去存储一个数,而这个数又大于这个固定的最大值时,就会导致整数溢出。
整数溢出的危害
如果一个整数用来计算一些敏感数值,如缓冲区大小或数值索引,就会产生潜在的危险。通常情况下,整数溢出并没有改写额外的内存,不会直接导致任意代码执行,但是它会导致栈溢出和堆溢出,而后两者都会导致任意代码执行。由于整数溢出出现之后,很难被立即察觉,比较难用一个有效的方法去判断是否出现或者可能出现整数溢出。
关于整数的异常情况主要有三种:
- 溢出
- 只有有符号数才会发生溢出。有符号数最高位表示符号,在两正或两负相加时,有可能改变符号位的值,产生溢出
- 溢出标志
OF可检测有符号数的溢出
- 回绕
- 无符号数
0-1时会变成最大的数,如 1 字节的无符号数会变为255,而255+1会变成最小数0。 - 进位标志
CF可检测无符号数的回绕
- 无符号数
- 截断
- 将一个较大宽度的数存入一个宽度小的操作数中,高位发生截断
宽度溢出
#include<stdio.h>
void main() {
int l;
short s;
char c;
l = 0xabcddcba;
s = l;
c = l;
printf("宽度溢出\n");
printf("l = 0x%x (%d bits)\n", l, sizeof(l) * 8);
printf("s = 0x%x (%d bits)\n", s, sizeof(s) * 8);
printf("c = 0x%x (%d bits)\n", c, sizeof(c) * 8);
printf("整型提升\n");
printf("s + c = 0x%x (%d bits)\n", s+c, sizeof(s+c) * 8);
}
输出如下
$ ./a.out
宽度溢出
l = 0xabcddcba (32 bits)
s = 0xffffdcba (16 bits)
c = 0xffffffba (8 bits)
整型提升
s + c = 0xffffdc74 (32 bits)
可以看到,在整数转换的过程中,导致变量值发生了变化。
void main(int argc,char* argv[])
{
unsigned short s;
int i;
char buf[80];
i = atoi(argv[1]);
s = i;
if(s >= 80)
return;
memcpy(buf,argv[2],i);
}
上图中奖int赋值给short后,用short型变量做边界检查,大宽度赋值给小宽度后,变小,从而绕过边界检查。
运算溢出
void CopyIntArray(int *array,int len)
{
int *myarray; int i;
myarray = malloc(len*sizeof(int));
if(myarray == NULL)
return;
for(i=0;i<len;i++)
myarray[i] = arrary[i];
}
上图代码中, malloc(len*sizeof(int)) ,括号中乘法后可能溢出,变成一个很小的正整数,从而myarray指针分配的空间过小,后续拷贝中溢出
符号溢出
static char data[256];
int store_data(char *buf, int len)
{
if(len > 256)
return -1;
return memcpy(data, buf, len);
}
// void *memcpy(void *dest, const void * src, size_t n)
如果len是负数,可以通过if的判断,但是传入函数时,会被自动转化为无符号整型(size_t),变得特别大,导致溢出。
10.4 漏洞的利用与发现
漏洞利用的目标
- 修改内存变量
- 修改代码逻辑(实现任意跳转)
- 修改函数返回地址
- 修改异常处理函数的指针(SEH等)
漏洞利用的思路
- 定位漏洞点:利用静态分析和动态调试确定漏洞机理,如堆溢出、栈溢出、整数溢出的数据结构,影响的范围。
- 按照利用要求,编写shellcode
- 溢出,覆盖代码指针,使得Shellcode获得可执行权
理解shellcode的地址重定位,说明含义
详见PE病毒重定位
掌握shellcode实例运行原理
jmp short GotoCall
shellcode:
pop esi;老EBP
xor eax,eax
mov byte ptr[esi+8], al;截断字符串,变成 calc.exe
lea ebx,[esi]
push ebx;字符串 calc.exe
mov ebx, 75813D30h ;system地址
call ebx; 调用system
GotoCall:
Call shellcode
db 'calc.exeddd'
end _start
ROP
为绕过DEP导致的数据段不可执行等,产出了ROP,利用现成的代码片段
如例题
假设内存中存在各种所需的ROP代码段,并且已知一个数存放在0x0A69地址,另外一个数存在0x0A89地址,尝试利用ROP设计一个完成0x0A69所在的值减去0x0A89所在的值,并将结果保存到0x0AF0.
假设0X0A69处的数字为x,0X0A89处数字为y,目标位将 x-y存放在[0X0AF0]
假设存在以下ROP代码段,注 (i)表示地址
;地址(1)处
pop eax
ret
;地址(2)处
mov ebx,[eax]
ret
;地址(3)处
mov ecx,ebx
ret
;地址(4)处
sub ecx,ebx
ret
;地址(5)处
sub [eax],ecx
ret
构造栈示意图如下
| 低地址 |
|---|
| (1) 注:溢出点从此地址开始 |
| 0X0A69 注:EAX=0X0A69 |
| (2) 注:EBX=x |
| (3) 注:ECX=x |
| (1) |
| 0X0A89 注:EAX=0X0A89 |
| (2) 注:EBX=y |
| (4) 注:ECX=x-y |
| (1) |
| 0X0AF0 注:EAX=0X0AF0 |
| (5) 注:[0X0AF0]=ECX=x-y |
| 高地址 |
注:需要非常注意构造payload里面如果有 00 截断的问题
防护手段
ASCII armoring机制想办法让libc所有函数的地址都包含一个零字节,让strcpy拷贝函数在遇到零地址时结束拷贝,攻击失败。
静态分析 VS 动态分析
静态分析不涉及被测软件的动态执行,通过软件设计规范或者编程规范对源代码审计等静态手段,在运行程序之前的早期阶段检测可能的缺陷。
动态分析:收集程序多次执行的运行过程的状态信息,结合输入和输出,检测程序存在的缺陷或漏洞。
11. win系统安全基址及漏洞防护手段
DEP/NX 数据执行保护
将数据所在的页面标识为不可执行,阻止栈/堆上代码执行
兼容性问题
可能造成某些软件正常功能无法使用。如翻译软件的全局划词翻译功能需要WriteProcessMemory进行代码注入,先执行翻译软件的函数,再回到原本软件的正常执行流程;但开启DEP后,会导致无法执行数据段代码,造成划词翻译失败。以及一些旧的应用程序,尤其是在Windows XP SP2之前开发的应用程序,可能与DEP不兼容,因为此类应用程序通常动态生成代码(如JIT compiling) 或者链接到动态生成代码的旧库(如旧版本的ATL)。以及杀毒软件某些功能。
绕过DEP
Ret2Libc ,ROP等
Stack Guard/Stack Canary 栈溢出检查-GS
检测覆盖函数的返回地址或某些类型的参数的某些缓冲区溢出。
GS基本思想
- 在函数开始时往栈中压入一个可以检验的随机数
- 在函数结束时验证栈中的随机数是否一致
主要步骤如下
- 系统以.data节的第一个DWORD作为Cookie的种子,或称原始Cookie(所有函数的Cookie都用这个DWORD生成)
- 在栈帧初始化以后系统用ESP异或种子,作为当前函数的Cookie,以此作为不同函数之间的区别,并增加Cookie的随机性(在程序每次运行时Cookie的种子都不同,因此具有很强的随机性)
- 在函数返回前,用ESP还原出Cookie的种子
- 最后,调用Security_check_cookie 函数进行校验
ASLR 地址空间布局随机化
栈和堆的基址是加载时随机确定的 ,程序自身和关联库的基址是加载时随机确定的

具有一定局限性
- ASLR是需要和DEP配合使用的。如果没有DEP保护,恶意代码一旦可以执行,就可以通过程序进程表结构来获得特定DLL的加载基址
- 只有第二个字节变化,即256种可能性
- 兼容问题:如果在编译时,编译器对可执行文件的基址进行了假设或者去掉了基址重定位信息。这种可执行文件在开启ASLR时,会导致错误,因为程序执行流试图jmp到内存中预期位置,但跟实际位置不一样。
第12章 构建安全的软件
软件设计阶段威胁建模

威胁分类后,画威胁树
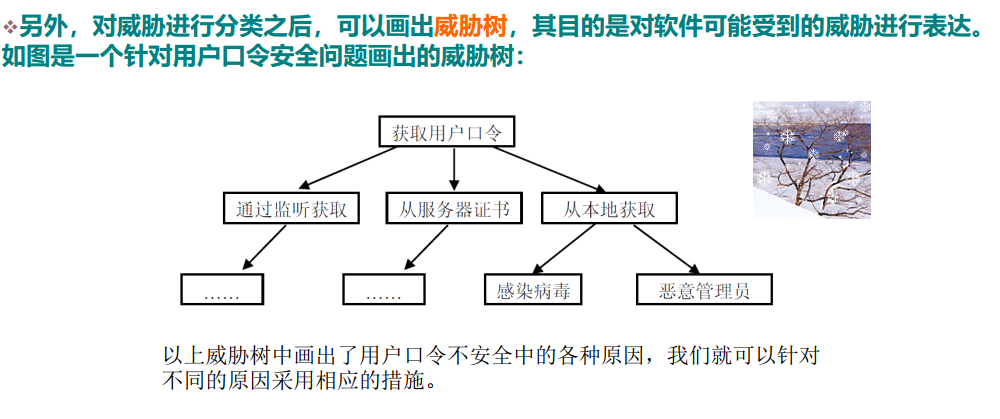
选择应付威胁或者缓和威胁的方法。很显然,针对不同的安全问题,我们可以选择应付威胁或者缓和威胁的方法。
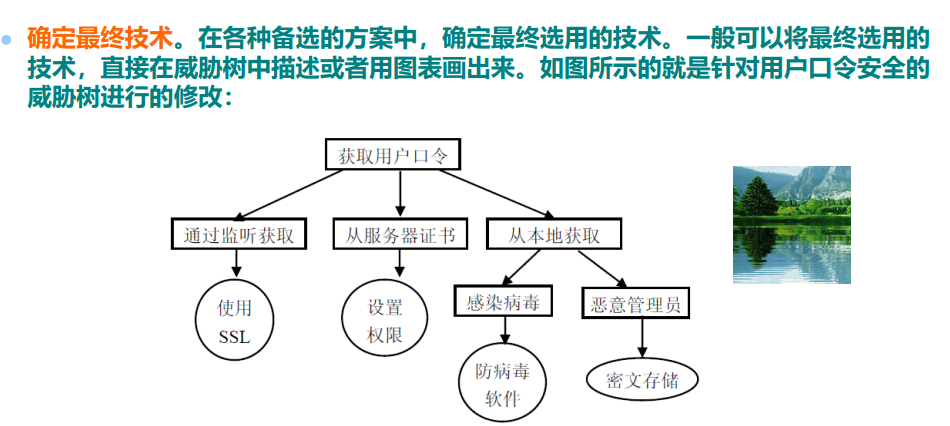
最终笔试卷子上的威胁树如上图所示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号