Caffe-windows上训练自己的数据
1.数据获取
在网上选择特定类别,下载相应的若干张图片。可以网页另存或者图片下载器。本例中保存了小狗、菊花、梅花三类各两百多张。

2.重命名
1 import os 2 import os.path 3 rootdir = "jh" 4 i=1 5 for parent,dirnames,filenames in os.walk(rootdir): 6 for filename in filenames: 7 newName=a+str(i)+".jpg" 8 print filename+" -> "+newName 9 os.rename(os.path.join(parent,filename), os.path.join(parent, newName)) 10 i+=1
3.更改分辨率
1 from PIL import Image 2 import glob, os 3 w,h = 256,256 4 def timage(): 5 for files in glob.glob('jh\*.jpg'): 6 filepath,filename = os.path.split(files) 7 filterame,exts = os.path.splitext(filename) 8 opfile = r'jh\jhout\\' 9 if (os.path.isdir(opfile)==False): 10 os.mkdir(opfile) 11 im=Image.open(files) 12 im_ss=im.resize((int(w), int(h))) 13 try: 14 im_ss.save(opfile+filterame+'.jpg') 15 except: 16 print filterame 17 os.remove(opfile+filterame+'.jpg') 18 19 if __name__=='__main__': 20 timage()
4.获取标签
1 import glob, os, shutil 2 def timage(): 3 names=["gg","jh"] 4 t=open("train.txt",'a') 5 v=open("val.txt",'a') 6 for files in glob.glob('jh\jhout\*.jpg'): 7 filepath,filename = os.path.split(files) 8 filterame,exts = os.path.splitext(filename) 9 oldfile = r'jh\jhout\\' 10 opfile = r'val\\' 11 if (os.path.isdir(opfile)==False): 12 os.mkdir(opfile) 13 if 200< int(filterame[2:]): # test data 14 shutil.move(oldfile+filterame+'.jpg',opfile+filterame+'.jpg') 15 v.write(filterame+'.jpg '+str(names.index("jh"))+'\n') 16 else: # train data 17 t.write('jhout/'+filterame+'.jpg '+str(names.index("jh"))+'\n') 18 t.close() 19 v.close() 20 21 22 if __name__=='__main__': 23 timage()
5.生成对应的leveldb格式数据
SET GLOG_logtostderr=1 Build\x64\Release\convert_imageset.exe examples/t/train/ examples/t/train/train.txt examples/t/trainldb 1 pause
SET GLOG_logtostderr=1 Build\x64\Release\convert_imageset.exe examples/t/val/ examples/t/val/val.txt examples/t/valldb 1 pause
6.计算均值
SET GLOG_logtostderr=1 Build\x64\Release\compute_image_mean.exe examples/t/trainldb examples/t/tmean.binaryproto pause
7.修改网络
models/bvlc_alexnet/train_val.prototxt
修改其中的num_output, batch_size和相应的路径
solver.prototxt如下,其中gamma指的是在学习率为step模式化下,每400次迭代变为原来的0.9倍。
net: "examples/t/train_val.prototxt" test_iter: 100 test_interval: 200 base_lr: 0.0001 lr_policy: "step" gamma: 0.9 stepsize: 400 display: 100 max_iter: 5000 momentum: 0.9 weight_decay: 0.001 snapshot: 10000 snapshot_prefix: "caffe_train" solver_mode: GPU
8.训练网络
cd ../../ "Build/x64/Release/caffe.exe" train --solver=examples/t/solver.prototxt pause
9.运行结果
在仅使用小狗和菊花两类,训练200张测试50张,可以达到98%的正确率。
使用小狗、菊花、梅花三类,可以达到89%的正确率。
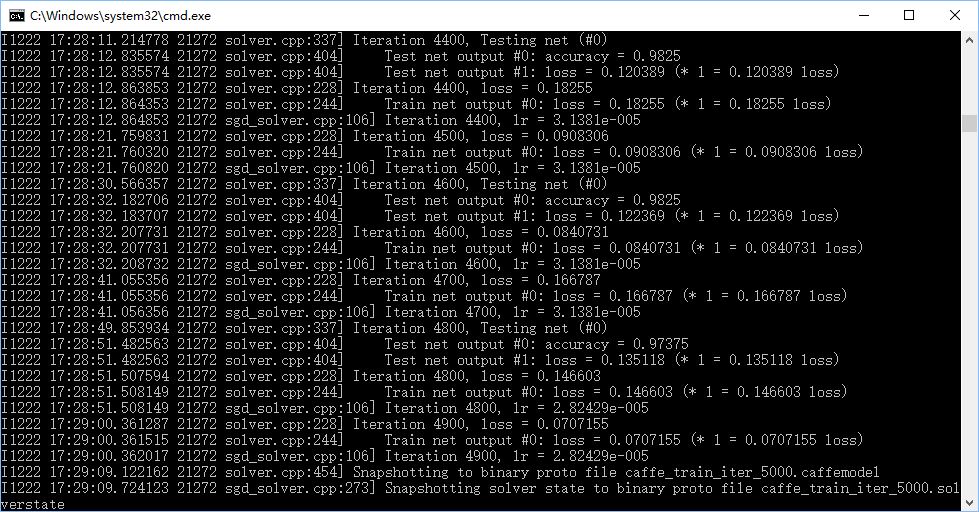
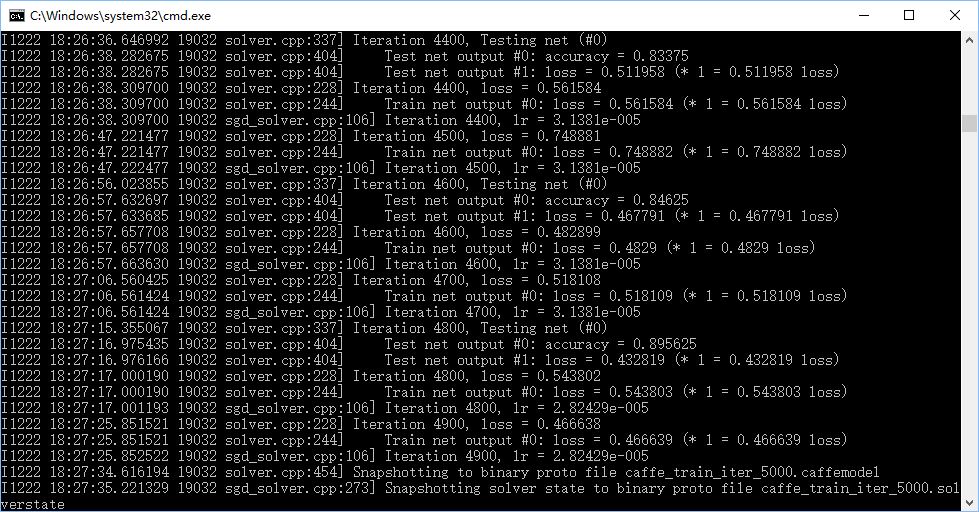
10.优化
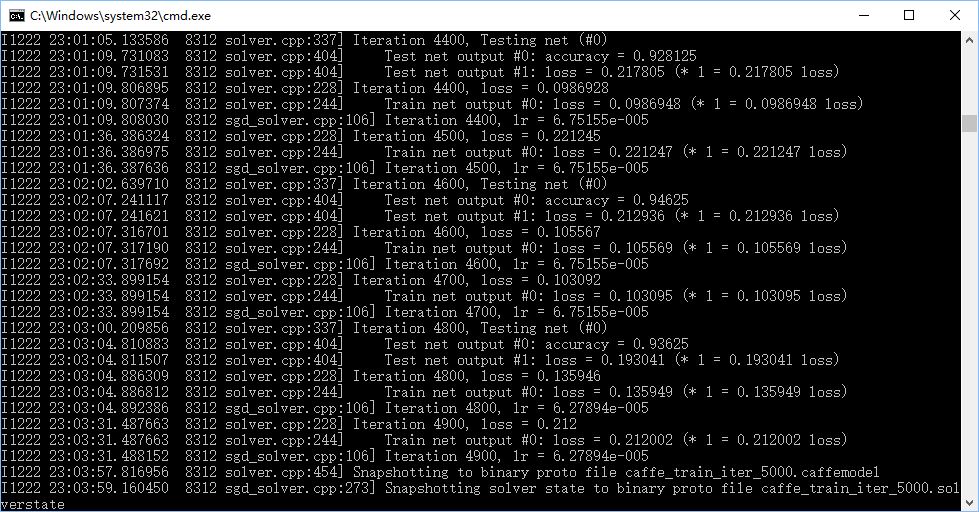
之前将train_val.prototxt中的crop_size: 227改成了128,速度相对快很多。
在三类分类中改回227,正确率在92%左右波动,进一步修改base_lr: 0.00015,gamma: 0.93,正确率可以达到94.6%。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号