软工实践第二次作业-词频统计
作业内容
Github项目地址
由于作业要求C++请用Visual Studio Community 2017进行开发,
而mac版vs无法写c++项目,所以是先用Xcode写完后再移植到VS上的;又因为作业要求使用Github来管理源代码和测试用例,所以一开始的签入记录可看Xcode版项目地址,最终完成项目在VS版项目地址。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 710 | 743 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 420 | 573 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 60 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 12 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 12 | 10 |
| • Design | • 具体设计 | 18 | 10 |
| • Coding | • 具体编码 | 150 | 128 |
| • Code Review | • 代码复审 | 60 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 190 | 300 |
| Reporting | 报告 | 180 | 160 |
| • Test Repor | • 测试报告 | 30 | 60 |
| • Size Measurement | • 计算工作量 | 30 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 120 | 90 |
| 合计 | 710 | 741 |
解题思路
解题思路描述。即刚开始拿到题目后,如何思考,如何找资料的过程
分析具体需求
- 1.基本功能
(1)统计文件的字符数
只需要统计Ascii码,汉字不需考虑空格,水平制表符,换行符,均算字符
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。(2)统计文件的单词总数
单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
(3)统计文件的有效行数:
何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000(4)统计文件中各单词的出现次数
最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
(5)按照字典序输出到文件result.txt
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式(6)输出格式
characters: number
words: number
lines: number
< word1 >: number
< word2 >: number
...思考:
四项功能,需要写四个函数,考虑文件读写和输入输出格式问题。
进一步思考:
- 文件如何读入读出?
fstream
- 如何匹配单词及分隔符?
使用正则语言,参考教程。
- 单词应该怎么存储?
存在map里。
- 2.接口封装
把基本功能里的:
统计字符数
统计单词数
统计最多的10个单词及其词频这三个功能独立出来,成为一个独立的模块
思考
- 除了类还有什么方法将功能独立出来?是怎么实现的?
使用dll封装,参考教程。
- 封装有什么有什么优点?
- 3.单元测试
- 如何使用单元测试项目?
参考教程。
- 使用什么插件查看代码覆盖率?
OpenCppCoverage
实现过程
设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
组织代码
有四个函数,它们之间相互独立。
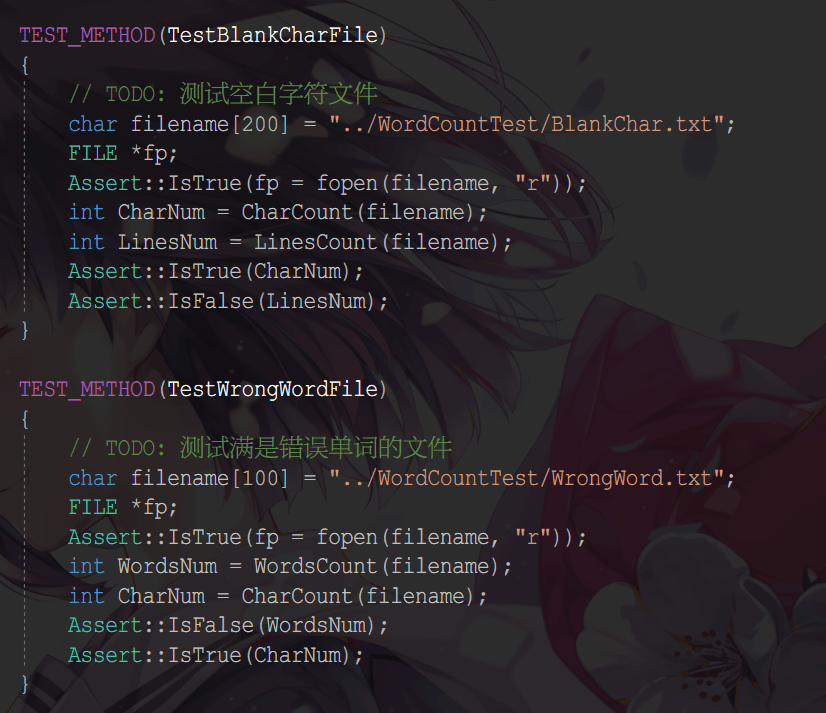
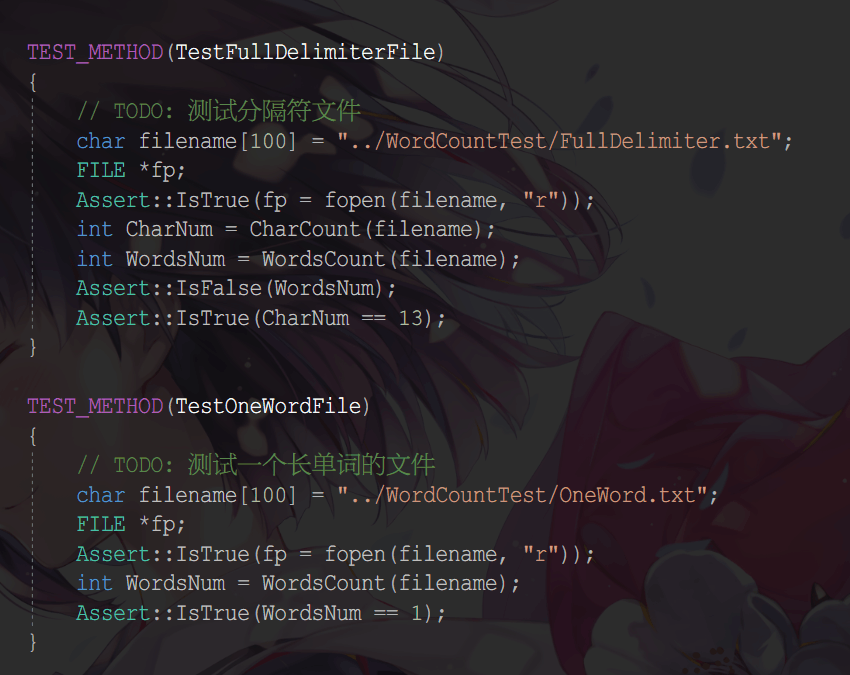
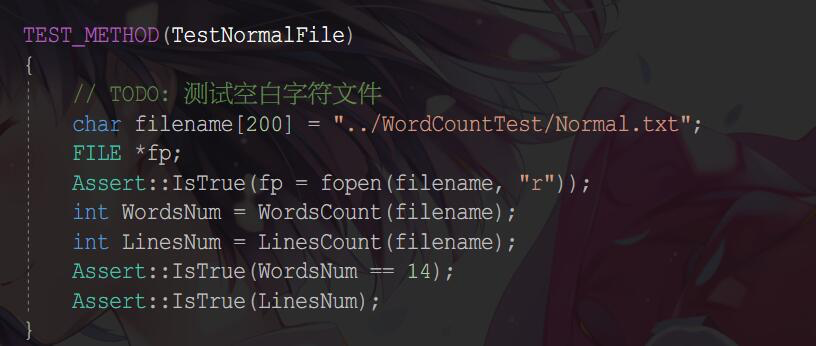
单元测试
- 所有测试函数
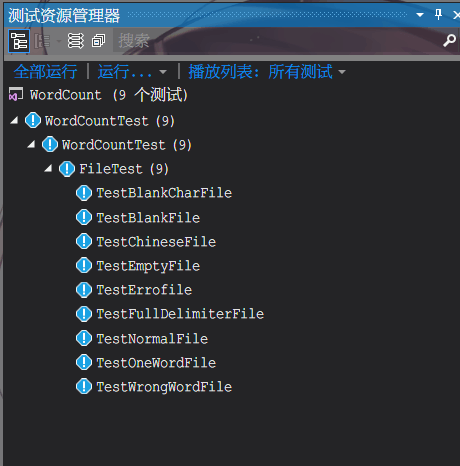
- 测试资源文件
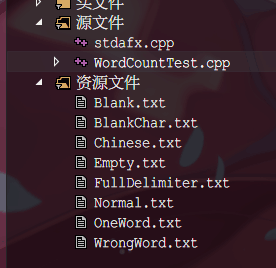
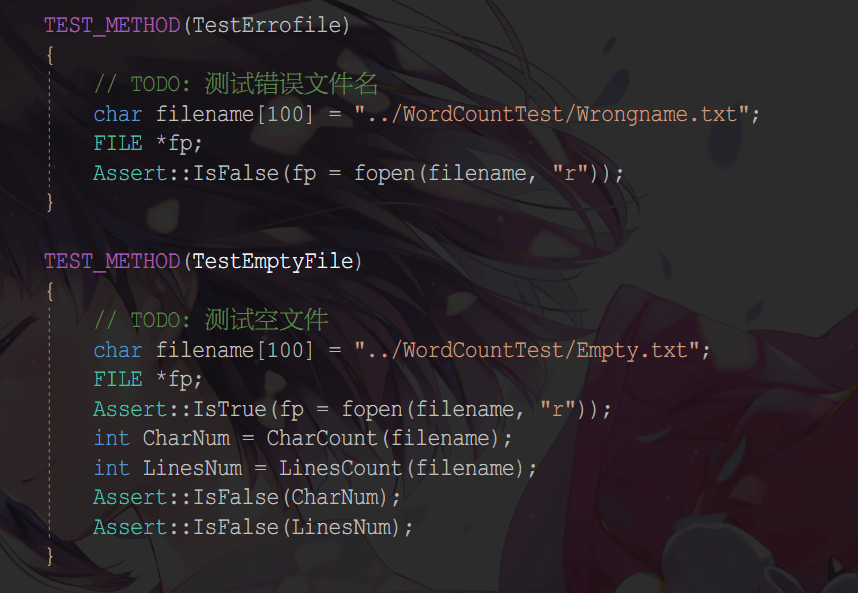
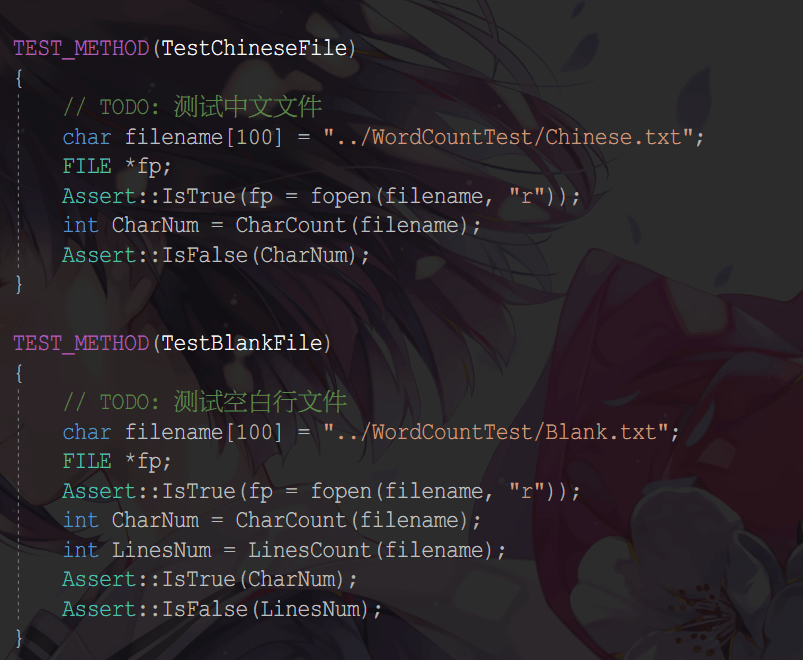
- 具体代码
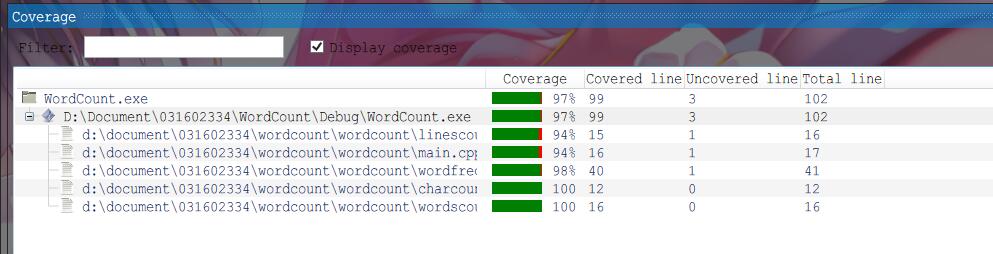
代码覆盖率:
改进思路
记录在改进程序性能上所花费的时间,描述你改进的思路。
用时:
用在改进性能上的时间是62分钟。
第一次改进思路:
- 单词匹配优化
一开始使用的是正则表达式匹配,后来想要改成有限确定自动机(DFA)以减少时间。改后发现正则表达式与自动机相比,虽然时间花费的比较长,但更易于修改,更易于看懂,遂还是选择了正则表达式匹配。
- 存单词优化
一开始直接将匹配后的单词丢入TreeMap,建树的时间复杂度为O(nlogn),后改为HashMap,复杂度降至O(n),由于统计总词数和词频记录是分开的,所以没有采用Tire字典树。
- 排序优化
简单粗暴地将Map里的数据转存到vector中使用sort排序了。其实因为只需输出词频最高的十个单词,所以只需维护一个数量为10的高频词顶堆就可以了。
第二次改进思路:
由于第一次使用NFA匹配输出的单词数与结果不符,所以改成了DFA,但仍不知道为什么正则匹配出现问题,等找出原因后再补充这一part。
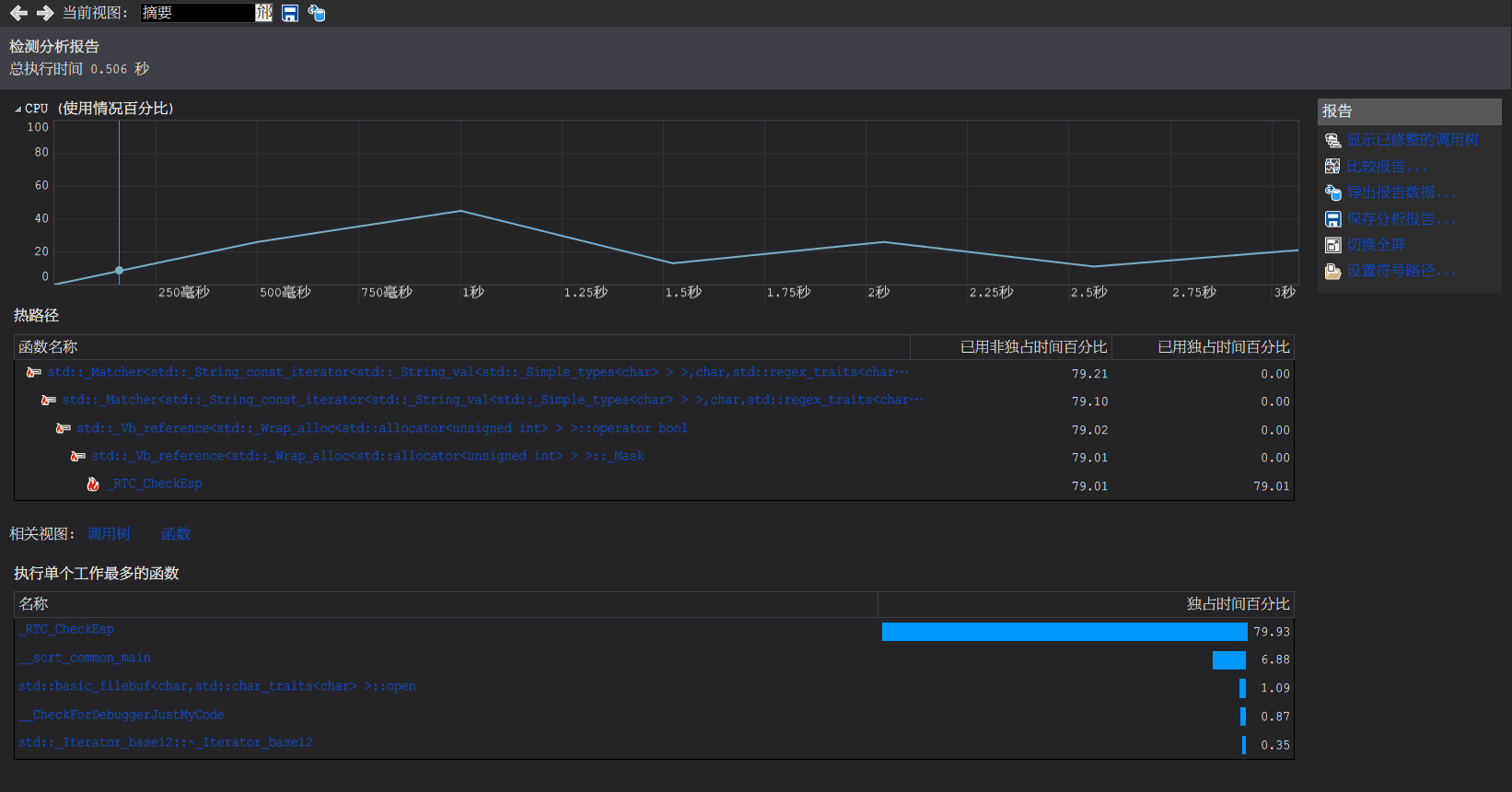
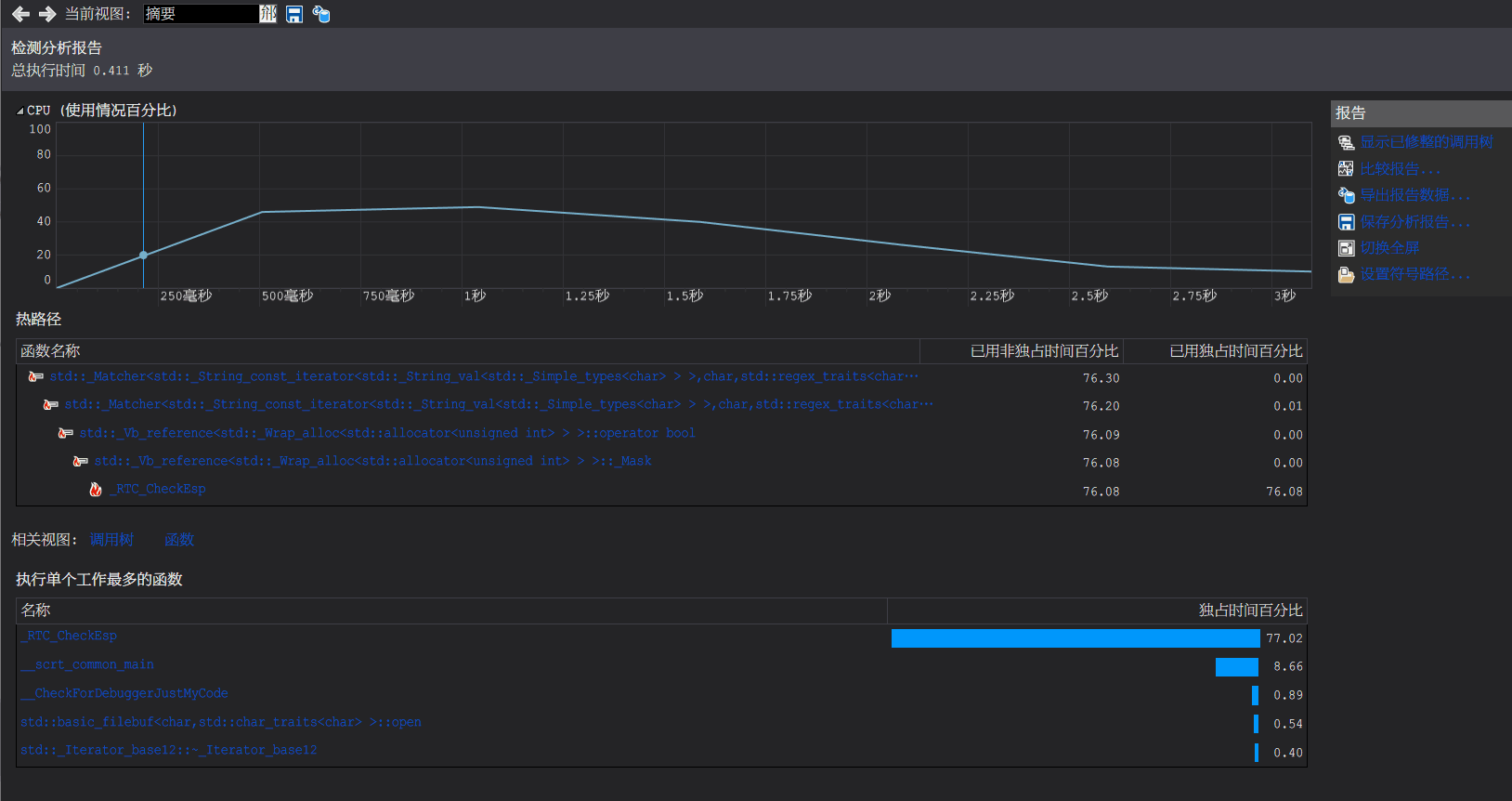
性能分析:
使用Map:
使用unordered_map(即hashmap):
代码说明
代码说明。展示出项目关键代码,并解释思路与注释说明。
异常处理:
使用 try - catch捕捉无输入或输入错误、输入文件名多于一个、输出文件无法打开的异常。
try
{
file.open(argv[1], ios::in);
if(!file) throw string("输入文件为空或错误\n");
if(argc > 2) throw string("输入参数过多\n");
file.close();
......
ofstream out(OutName);
if (!out) throw string("输出文件无法打开\n");
out.close();
}
catch(string R)
{
cout << R << endl;
}
统计单词数目:
用正则表达式匹配单词,以统计单词总数。
regex WordsRegex("^[A-Za-z]{4}[[:w:]]+");//单词的正则表达式
long wordsnum = 0;
string temp;
fstream TextFile;
TextFile.open(filename);//打开文件
string OneLine;
while (TextFile >> OneLine)//读入一行
{
sregex_token_iterator end;
for (sregex_token_iterator wordIter(OneLine.begin(), OneLine.end(), WordsRegex), end; wordIter != end; wordIter++)
{//使用正则迭代器在一行文本中逐个找出单词
wordsnum++;
}
}
下推自动机
while ((charTemp = ifs.get()) != EOF)
{
CharNum++;
if (charTemp >= 65 && charTemp <= 90)
charTemp += 32;
switch (state)
{
case 0:
if (charTemp >= 97 && charTemp <= 122)
{
wordtemp += charTemp;
state = 1;
}
break;
case 1:
if (charTemp >= 97 && charTemp <= 122)
{
wordtemp += charTemp;
state = 2;
}
else
{
state = 0;
wordtemp = "";
}
break;
case 2:
if (charTemp >= 97 && charTemp <= 122) {
wordtemp += charTemp;
state = 3;
}
else
{
state = 0;
wordtemp = "";
}
break;
case 3:
if (charTemp >= 97 && charTemp <= 122) {
wordtemp += charTemp;
state = 4;
}
else
{
state = 0;
wordtemp = "";
}
break;
case 4:
if (charTemp >= 97 && charTemp <= 122 || (charTemp >= '0'&&charTemp <= '9'))
{
wordtemp = wordtemp + charTemp;
}
else
{
WordsMap[wordtemp] ++;
state = 0;
wordtemp = "";
}
break;
}
}
if (state == 4)
{
WordsMap[wordtemp] ++;
}
统计字符个数:
统计所有非中文字符
int CharNum = 0;
ifstream ifs(filename);
char charTemp;
mci charCountMap;
while ((charTemp = ifs.get()) != EOF)
{
if (charTemp >= NULL && charTemp <= '~')//统计所有字符
CharNum++;
}
ifs.clear();
ifs.seekg(0);
统计行数:
要求去除空行
fstream fs(filename, ios::in);
string s;
while (getline(fs, s))
{
for (i = 0, IsNull = 1; i < s.length(); i++)
{
if (s[i] != ' ' && s[i] != '\t')//排除掉非空行
{
IsNull = 0;
break;
}
}
if (!IsNull) lines++;
}
return lines;
输出高频词:
输出词频最高的十个单词,相同词频的按照字典序排序
int sortWords(psi p1, psi p2)//自定义的vector排序函数
{
if (p1.second == p2.second)
{
return p1.first < p2.first;//词频相等按字典序排
}
else return p1.second > p2.second;
}
for (unordered_map<string, int>::iterator iter = WordsMap.begin(); iter != WordsMap.end(); iter++)//将map中的数队放入vector中
{
WordsVec.push_back(pair<string, int>(iter->first, iter->second));
}
sort(WordsVec.begin(), WordsVec.end(), sortWords);//排序
wordsCount(filename1);
long endp = WordsVec.size();
endp = (endp < num) ? endp : num;//判断总词数是否大于10
ofstream out(filename2, ios::in | ios::out);//读入输出文件
out.seekp(0, ios::end);//定位到文件末尾继续写入
for (vpsi::iterator iter = WordsVec.begin(); iter != (WordsVec.begin() + endp); ++iter)//vpsi为vector(pair<string, int>)
{
out << "<" << iter->first << ">:" << iter->second << endl;
}
心路历程与收获
结合在构建之法中学习到的相关内容,撰写解决项目的心路历程与收获。
这次代码作业陆陆续续地写了好几天,虽然代码很快就写完了,但由于设备问题,只能在虚拟机上跑,下载vs花了很长时间,而后运行又跑崩了好几次_(:⁍」∠)_,git又一直上传不上,历经了千辛万苦,最终还是在别人的电脑上跑了程序。
不过虽说过程艰难,但学到的东西还是蛮多的。在这期间,我不仅了解了单元测试,代码覆盖率和DLL封装,还了解了写代码前准备工作的重要性。而阅读《构建之法》更令我受益匪浅,这本书中所写的,从知识准备到项目规划,都非常清晰有条理,假设的情景也十分生动活泼,阅读感极佳。这些天来感受最深的还是实践的重要性,相信如果能将书中的习题完整地做完,我们的动手实践能力一定会得到极大的提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号