es01
elasticSearch6
用途:全文检索(全部字段)、模糊查询(搜索)、数据分析(提供分析语法,例如聚合)
和elasticSearch5的区别在于,root用户权限、一个库能否建立多个表
安装
mkdir -p /opt/es
tar – zxvf elasticsearch-6.3.1.tar.gz
赋予权限
chmod 777 -R elasticsearch-6.3.1
cd config
1.修改elasticsearch.yml , jvm.options
vi jvm.options
-Xms256m
-Xmx256m
vi elasticsearch,yml
配置es的host地址
network.host: 192.168.239.139
http.port:9200
2.修改linux的默认线程数、最大文件数、最大内存数
vi /etc/security/limits.conf 添加
* hard nofile 655360
* soft nofile 131072
* hard nproc 4096
* soft nproc 2048
nofile - 打开文件的最大数目
noproc - 进程的最大数目
soft 指的是当前系统生效的设置值
hard 表明系统中所能设定的最大值
3. vi /etc/sysctl.conf
vm.max_map_count=655360
fs.file-max=655360
vm.max_map_count=655360,因此缺省配置下,单个jvm能开启的最大线程数为其一半
file-max是设置 系统所有进程一共可以打开的文件数量
sysctl -p 使配置生效
user add es
su es
./elasticsearch
192.168.239.139:9200
kibana安装与启动
版本6.3.1
cd conf
vi kibana.yml
server.host:"0.0.0.0"
elasticsearch.url:"192.168.239.139:9200"
cd bin
./kibana
或
nohup ./kibana &
查看 kibana
ps -ef|grep kibana
192.168.239.139:5601
Elasticsearcch数据的存储方式
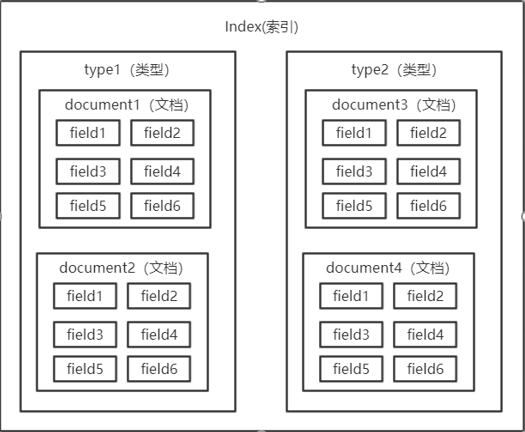
1 节点
一个节点就是一个es的服务器,es集群中,主节点负责集群的管理和任务的分发,一般不负责文档的增删改查
2 片
分片是es的实际物理存储单元(一个lucene的实例)
3 索引
索引是es的逻辑单元,一个索引一般建立在多个不同机器的分片上
4 复制片
每个机器的分片一般在其他机器上会有两到三个复制片(目的是提高数据的容错率)
5 容错
一旦集群中的某些机器发生故障,那么剩余的机器会在主机点的管理下,重新分配资源(分片)
6 分片的路由
写操作(新建、删除)只在主分片上进行,然后将结果同步给复制分片
Sync 主分片同步给复制成功后,才返回结果给客户端
Async 主分片在操作成功后,在同步复制分片的同时返回成功结果给客户端
元数据
PUT test/doc
{
“name”:”zhangsan”,
“age”:10
}
_index:文档所在索引名称
_type:文档所在类型名称
_id:文档唯一id
_uid:组合id,由_type和_id组成(6.x后,_type不再起作用,同_id)
_source:文档的原始Json数据,包括每个字段的内容
_all:将所有字段内容整合起来,默认禁用(用于对所有字段内容检索)
倒排索引(Inverted Index)
ElasticSearch引擎把文档数据写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的
分词
Standard(es默认) 支持多语言,按词切分并做小写处理
IK提供了两个分词算法ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
mapping
定义数据库中的表的结构的定义,通过mapping来控制索引存储数据的设置
定义Index下的字段名(Field Name)
定义字段的类型,比如数值型、字符串型、布尔型等
定义倒排索引相关的配置,比如documentId、记录position、打分等
获取索引mapping
不进行配置时,自动创建的mapping
数据类型
实际上每个type中的字段是什么数据类型,由mapping定义。
但是如果没有设定mapping系统会自动,根据一条数据的格式来推断出应该的数据格式。
默认只有text会进行分词,keyword是不会分词的字符串。
mapping除了自动定义,还可以手动定义,但是只能对新加的、没有数据的字段进行定义。一旦有了数据就无法再做修改了。
虽然每个Field的数据放在不同的type下,但是同一个名字的Field在一个index下只能有一种mapping定义。
核心数据类型
字符串型:text、keyword
数值型:long、integer、short、byte、double、float、half_float、scaled_float
日期类型:date
布尔类型:boolean
二进制类型:binary
范围类型:integer_range、float_range、long_range、double_range、date_range
复杂数据类型
数组类型:array
对象类型:object
嵌套类型:nested object
地理位置数据类型
geo_point(点)、geo_shape(形状)
专用类型
记录IP地址 ip
实现自动补全 completion
记录分词数:token_count
记录字符串 hash值 母乳murmur3
多字段特性multi-fields
文档操作
1.创建文档,文档通过其_index、_type、_id唯一确定
1 PUT {index}/{type}/{id} 2 { 3 “”:”” 4 } 5 6 7 例: 8 PUT /website/blog/123 9 10 { 11 12 "title": "My first blog entry", 13 14 "text": "Just trying this out...", 15 16 "date": "2014/01/01" 17 18 }
Elasticsearch中每个文档都有版本号,每当文档变化(包括删除)都会使_version增加。_version确保你程序的一部分不会覆盖掉另一部分所做的更改
自增ID
1 URL现在只包含_index和_type两个字段: 2 3 POST /website/blog/ 4 { 5 "title": "My second blog entry", 6 "text": "Still trying this out...", 7 "date": "2014/01/01" 8 }
2.获取文档
从Elasticsearch中获取文档,使用同样的_index、_type、_id
1 GET /website/blog/123?pretty
在任意的查询字符串中增加pretty参数,类似于上面的例子。会让Elasticsearch美化输出(pretty-print)JSON响应以便更加容易阅读。
检索文档的一部分
通常,GET请求将返回文档的全部,存储在_source参数中。但是可能你感兴趣的字段只是title。请求个别字段可以使用_source参数。多个字段可以使用逗号分隔
1 GET /website/blog/123?_source=title,text
_source字段现在只包含请求的字段,而且过滤了date字段
3.更新
1 POST /website/blog/123 2 { 3 "title": "My first blog entry", 4 "text": "I am starting to get the hang of this...", 5 "date": "2014/01/02" 6 }
4.删除文档
1 DELETE /website/blog/123
SearchApi
GET /_search #查询所有索引文档
GET /my_index/_search #查询指定索引文档
GET /my_index1,my_index2/_search #多索引查询
GET /my_*/_search
URI查询方式(查询有限制,很多配置不能实现)
GET /my_index/_search?q=user:alfred #指定字段查询
GET /my_index/_search?q=keyword&df=user&sort=age:asc&from=4&size=10&timeout=1s
q : 指定查询的语句,例如q=aa或q=user:aa
df:q中不指定字段默认查询的字段,如果不指定,es会查询所有字段
Sort:排序,asc升序,desc降序
timeout:指定超时时间,默认不超时
from,size:用于分页
term与phrase
term相当于单词查询,phrase相当于词语查询
term:Alfred way等效于alfred or way
phrase:”Alfred way” 词语查询,要求先后顺序
泛查询
Alfred等效于在所有字段去匹配该term(不指定字段查询)
指定字段
name:alfred
Group分组设定(),使用括号指定匹配的规则
(quick OR brown)AND fox:通过括号指定匹配的优先级
status:(active OR pending) title:(full text search):把关键词当成一个整体
布尔操作符
AND(&&),OR(||),NOT(!)
例如:name:(tom NOT lee)
#表示name字段中可以包含tom但一定不包含lee
+、-分别对应must和must_not
例如:name:(tom +lee -alfred)
#表示name字段中,一定包含lee,一定不包含alfred,可以包含tom
注意:+在url中会被解析成空格,要使用encode后的结果才可以,为%2B
GET test_search_index/_search?q=username:(alfred %2Bway)
范围查询,支持数值和日期
1、区间:闭区间:[],开区间:{}
age:[1 TO 10] #1<=age<=10
age:[1 TO 10} #1<=age<10
age:[1 TO ] #1<=age
age:[* TO 10] #age<=10
2、算术符号写法
age:>=1
age:(>=1&&<=10)或者age:(+>=1 +<=10)
通配符查询
?:1个字符
*:0或多个字符
例如:name:t?m
name:tom*
name:t*m
注意:通配符匹配执行效率低,且占用较多内存,不建议使用,如无特殊要求,不要讲?/*放在最前面
正则表达式
name:/[mb]oat/
模糊匹配fuzzy query
name:roam~1 [0,1,2]
匹配与roam差1个character的词,比如foam、roams等
近似度查询proximity search
“fox quick”~5
以term为单位进行差异比较,比如”quick fox” “quick brown fox”
复杂查询的定义
1 Query{ 2 Bool:{// 先过滤,后查询 3 Filter:{term,term} 4 must:{match} 5 } 6 }
先过滤再查询
1 "query":{ 2 "bool":{ 3 "filter":[ {"term": { "actorList.id": "1" }}, 4 {"term": { "actorList.id": "3" }}], 5 "must":[{"match":{"name":"red"}}] 6 } 7 } 8 "query": { 9 "bool": { 10 "filter": [{"terms":{ "actorList.id": [1,3]}}] , 11 "must": [{"match": {"name": "red"}}] 12 } 13 }
创建mapping
1 PUT gmall 2 { 3 "mappings": { 4 "SkuInfo":{ 5 "properties": { 6 "id":{ 7 "type": "keyword" 8 , "index": false 9 }, 10 "price":{ 11 "type": "double" 12 }, 13 "skuName":{ 14 "type": "text", 15 "analyzer": "ik_max_word" 16 }, 17 "skuDesc":{ 18 "type": "text", 19 "analyzer": "ik_smart" 20 }, 21 "catalog3Id":{ 22 "type": "keyword" 23 }, 24 "skuDefaultImg":{ 25 "type": "keyword", 26 "index": false 27 }, 28 "skuAttrValueList":{ 29 "properties": { 30 "valueId":{ 31 "type":"keyword" 32 } 33 } 34 } 35 } 36 } 37 } 38 }
查询
1 GET gmall/SkuInfo/_search 2 { 3 "query": { 4 "bool": { 5 "filter": [{"terms":{ "skuAttrValueList.valueId": ["46","45"]}},{"term":{"catalog3Id":"61"}}], 6 "must": { "match": { "skuName": "小米" } } 7 } 8 }, 9 "highlight": { 10 "fields": {"skuName":{}} 11 }, 12 "sort":{ 13 "hotScore":{"order":"desc"}}, 14 "aggs": { "groupby_attr": {"terms": {"field": "skuAttrValueList.valueId" }} 15 } 16 }
完

 浙公网安备 33010602011771号
浙公网安备 33010602011771号