redis08
redis的规范与运维
Key设计
1.可读性和可管理性
- 以业务名(或数据库名)为前缀(防止key冲突),用冒号分割分割,
例如 业务名:表名:id,如 ugc:video:1
数据对象名:数据对象id:对象属性
User:123:passpword
User:123:username
Sku:108:info
2.简洁性
保证语义的情况下,控制key的长度,当key较多时,内存占用也不容忽视
例如 user:{uid}:friends:messages:{mid} 可以简化为 u:{uid}:fri:mes:{mid}
3.不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符
Value设计
1.避免bigkey
string类型控制在10KB以内
hash、list、set、zset元素个数不要超过5000个
反例:一个包含几百万个元素的list、hash等,一个巨大的json字符串
2.bigkey的危害
网络阻塞
Redis阻塞
会形成慢查询阻塞其他命令
集群节点数据不均衡
频繁序列化:应用服务器CPU消耗
Redis客户端本身不负责序列化
应用频繁序列化和反序列化bigkey:本地缓存或Redis缓存
发现bigkey的方法
使用应用的监控异常对其发现
JedisConnectionException:Read timed out
Could not get a resource from the pool
在从节点上执行 redis-cli --bigkeys
scan + debug object key
主动报警:网络流量监控、客户端监控
内核热点key问题优化
bigkey的删除
直接通过del删除bigKey会非常慢,对redis发生阻塞
小心bigkey的隐性删除(不会存在在主节点的慢查询中,但是会发生在从节点中)
过期
rename等
可以使用redis4.0的lazy delete (unlink命令)
redis会将unlink后的数据进行后台删除,不会阻塞前台的命令线程
bigkey的预防
优化数据结构:例如二级拆分,例如按天/按小时存入
存在bigkey的节点进行物理隔离或者万兆网卡:不是治本方案
命令优化:例如hgetall -> hmget 、 hscan
报警和定期优化
选择合理的数据结构
例如存储实体类型时候
反例
set user:1:name tom;
set user:1:age 19;
set user:1:favor football;
正例
hmset user:1 name tom age 19 favor football;
缘由
避免出现数据松散
小hash会采用ziplist,得到节省内存的效果
需求 100万数据的(picId -> userId)
方案1:全string:set picId userId
方案2:一个hash:hset allPics picId userId
方案3:若干个小hash:hset picId/100 picId%100 userId
三个方案的比较
方案1 全string 编码简单 , 浪费内存全量获取比较复杂
方案2 全hash , 浪费内存bigKey |
方案3 分段hash 节省内存 编程复杂,hash无法设置ttl,超时问题,性能问题-ziplist
键值生命周期的管理
周期数据需要设置过期时间,object idletime可以找垃圾的key-value
过期时间不宜集中,容易出现缓存穿透和雪崩等问题
命令优化技巧
1.O(n)以上命令需要关注n的数量
例如:hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确n的值。有遍历的需求可以使用hscan、sscan、zscan。
2.禁用命令
禁止线上使用keys、flushall、flushdb等,通过redis的config rename机制禁调命令,或者使用scan的方式渐进式处理。
3.合理使用select
redis的多数据库较弱,使用数字进行区分。
很多客户端支持较差,不清楚当前使用的是哪个库
同时多业务用多数据库实际还是单线程处理,会有干扰。
4.Redis事务功能较弱,不建议过多使用
Redis的事务功能较弱(不支持回滚)
在集群版本中要求一次事务操作的key必须在一个slot上(可以使用hashtag功能解决)
5.Redis集群版本在使用Lua上有特殊要求
所有的key,必须在一个slot之上,否则直接返回ERROR
6.必要情况下使用monitor命令时,要注意不要长时间使用
任何客户端中,发起任何命令都会发生送monitor客户端。但是在大QPS环境下对性能造成影响
Java客户端优化
1.避免多个应用使用一个Redis实例
不相干的业务拆分,公共数据做服务化
2.使用连接池,标准使用方式
1 Jedis jedis = null; 2 try { 3 jedis = jedisPool.getResource(); 4 jedis.executeCommand(); 5 }catch(Exception e) { 6 logger.error("op key {} error : {} " , key , e.getMessage() , e); 7 }finally{ 8 if( null != jedis ) { 9 jedis.close(); 10 } 11 }
Java客户端优化
1.避免多个应用使用一个Redis实例
不相干的业务拆分,公共数据做服务化
2.使用连接池,标准使用方式
1 Jedis jedis = null; 2 try { 3 jedis = jedisPool.getResource(); 4 jedis.executeCommand(); 5 }catch(Exception e) { 6 logger.error("op key {} error : {} " , key , e.getMessage() , e); 7 }finally{ 8 if( null != jedis ) { 9 jedis.close(); 10 } 11 }
连接池参数优化
1.maxTotal:8
资源池中的最大连接数
2.maxIdle:8
资源池允许最大空闲的连接数
3.minIdle:0
资源池确保最少空闲的连接数
4.blockWhenExhausted:true
当资源池用尽时,调用者是否要等待,只有当设为true时,下面的maxWaitMillis才会生效
使用建议:建议使用默认值
maxWaitMillis:-1(永不超时)
当资源池连接用尽时,调用者的最大等待时间(单位:毫秒)
使用建议:不建议使用默认值
6.testOnBorrow:false
向资源借用连接时是否是否做连接有效性检测(ping),无效连接会被移除
使用建议:业务量很大的时候建议设置为false(多一次ping的开销)
7.testOnReturn:false
向资源池归还连接时是否做连接有效性检测(ping),无效连接会被移除
使用建议:业务量很大的时候建议设置为false(多一次ping的开销)
8.jmxEnabled:true
是否开启jmx监控,可用于监控
使用建议:建议开启,但应用本身也要开启
9.testWileIdle:false
是否开启空闲资源检测
使用建议:true
10.timeBetweenEvictionRunsMIllis:-1(不检测)
空闲资源的检测周期(单位为毫秒)
使用建议:建议设置,周期自行选择,可以默认也可以使用接下来JedisPoolConfig的配置
11.minEvictableIdleTimeMillis:1000\*60\*30=30分钟
资源池中资源最小空闲时间(单位为毫秒)达到此值后空闲资源将被移除
使用建议:可根据自身业务决定,大部分默认值即可,也可以考虑使用如下JedisPoolConfig中的配置
12.numTestsPerEvictionRun:3
做空闲资源监测时,每次的采样数
使用建议:可根据自身应用连接数进行微调,如果设置为-1,就是对所有连接座空闲检测
13.使用建议
maxTotal的配置方式
maxIdle接近maxTotal即可
考虑因素
业务希望Redis并发量,并发量越大maxTotal越大
客户端执行命令时间,命令时间越小maxTotal越小
Redis资源:例如 应用个数 * maxTotal 不能超过Redis最大连接数
资源开销:虽然希望控制空闲连接,但是不希望因为连接池的频繁释放创建连接造成不必的开销
案例计算
一次命令时间(borrow|return resource + Jedis执行命令(含网络时间))的平均耗时是1ms,一个连接的QPS大约是1000。如果业务期望的QPS是50000。那么理论的maxTotal=50,可适当伸缩。
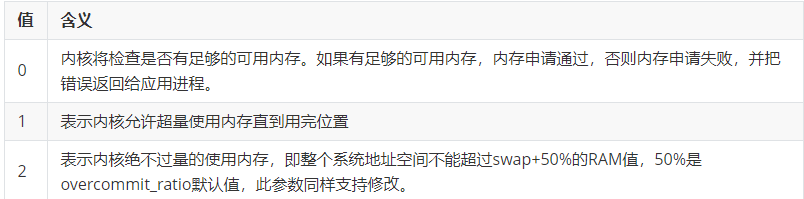
1 ##配置位置 2 vi /etc/sysctl 3 ##Redis推荐将该值设置为1,避免fork的时候,因为内存不够而失败 4 echo "vm.overcommit_memory=1" >> /etc/sysctl.conf 5 sysctl vm.overcommit_memory=1
最佳实践
Redis设置合理的maxmemory,保证机器有20%~30%的闲置内存
集中化管理AOF重写和RDB的bgsave。
避免一台机器上有多个master
设置vm.overcommit_memory=1.防止极端情况下fork失败
2.swappiness
###立即生效 echo ${bestValue} > /proc/sys/vm/swappiness ###永久生效 echo vm.swappiness=${bestValue} >> /etc/sysctl.conf

最佳实践
如果Linux >= 3.5 , vm.swappiness = 1 , 否则vm.swappiness = 0
物理内存充足时,使Redis足够快
物理内存不足时,避免Redis死掉(如果当前Redis为高可用,死掉比阻塞更好)
3.THP(Transparent huge page)
作用:加速fork
建议:将其禁用,因为可能会产生更大(512倍)的内存开销
echo never > /sys/kernel/mm/transparent_huagepage/enabled
4.OOM killer
作用:内存使用超出,操作系统将按照规则kill掉某些进程
配置方法:/proc/${process_id}/oom_adj越小,被杀掉的概率越小
运维经验:
不要过度依赖此特性,应该合理管理内存
通常在高可用的情况下,被杀掉比僵死更好,因此不要过多依赖oom_adj配置。
5.NTP(Net Time Protocol)
避免有多台机器,每台机器的时间都不一致,那么查日志找问题的时候会产生很多困扰。
建议实现本地的NTP服务或配置统一的NTP服务
Redis Cluster或Redis Sentinel依赖选举的时间为本地时间,如果有不一致不会出错
6.ulimit
redis默认的maxclient=10000,则redis至少需要10032个文件句柄。
但是Linux默认只有4096个文件句柄,即Redis默认实际的maxclient=4064
可以通过ulimit -n 提升Linux文件句柄数
7.TCP backlog
Redis默认的tcp-backlog值为511,可以修改配置tcp-backlog进行调整,如果Linux的tcp-backlog小于Redis设置的tcp-backlog,那么在Redis启动时会提示Redis的tcp-backlog被迫降至Linux的tcp-backlog
安全的Redis
一、全球crackit攻击
被攻击的机器特征
Redis所在的机器有外网IP
Redis以默认端口6379为启动端口,并且对外网开放
Redis是以root用户启动的
Redis没有设置密码
Redis的网卡bind为0.0.0.0或者没有绑定
攻击步骤
访问Redis
flushall
set crackit id_rsa.pub
config set dir
config set dbfilename
save
ssh root
二、安全七则
1.设置密码
服务器配置:requirepass和masterauth
客户端连接:auth命令和-a参数
注意事项
密码要足够复杂,防止暴力破解
masterauth不要忘记
auth还是通过明文传输,可以通过抓包破解
2.伪装安全命令
服务端配置:rename-command为空或随机字符
客户端连接:不可用或指定随机字符
注意事项
不支持config set动态设置
RDB和AOF如果包含rename-command之前的命令,将无法使用
config命令本身是在Redis内核会使用到,不建议设置
3.网卡绑定bind
服务端配置:bind限制的是网卡,并不是客户端IP
注意事项:
bind不支持config set动态配置
bind 127.0.0.1需要谨慎
如果存在外网网卡
4.开启Linux防火墙
5.定期备份数据
6.不使用默认端口,防止被弱攻击杀掉
7.使用非root用户启动
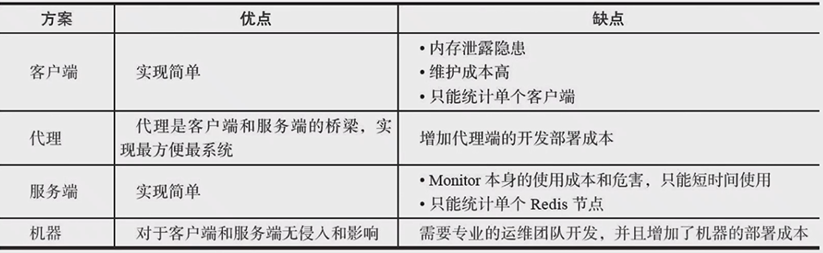
热点Key的发现
1.客户端
2.代理端
3.服务端
4.机器收集
方案对比
完

 浙公网安备 33010602011771号
浙公网安备 33010602011771号