Talk About AWS Aurora for MySQL max_connections parameter Calculation | 浅谈AWS Aurora for MySQL数据库中 max_connections参数的计算
1. The Problem | 现象
When connect to the product environment database of my company, the Navicat shows "Too many connections", that's because the concurrency reaches the connection upper threshold. I has planned to attach the Keepalive tag to the connection string for resolving, but found that would cause failure (can't connect to the database) since it isn't supported if .net core in Linux environment (Linux manages the TCP long connection by OS, therefore the MySQL.Data.dll can't handle it.)
在我试图用Navicat连接公司的生产库时,爆出了“Too many connections”的提示,原因是并发连接达到了上限,曾经尝试在connection string中增加Keepalive的标签,但也失败了(会导致连接不上数据库),主要原因是.net core在linux环境中使用连接字符串做Keepalive是不受支持的,Linux在操作系统级来管理TCP的长连接,导致MySQL.Data.dll不能从自身去解决这一问题。
2. The Consideration of AWS | AWS的考量
We may see the default value of max_connections in parameter group when using AWS Aurora for MySQL, that might be GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000}) for test environment and GREATEST({log(DBInstanceClassMemory/805306368,2)*45},{log(DBInstanceClassMemory/8187281408,2)*1000}) for product environment typically.
在使用AWS Aurora for MySQL数据库时,我们可以看到在参数组中max_connections参数默认的值为:
GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})(测试环境)与GREATEST({log(DBInstanceClassMemory/805306368,2)*45},{log(DBInstanceClassMemory/8187281408,2)*1000})(生产环境)。
Actually it means as
实际上这表示的是如下的两个式子
And
What's the two constants meaning? and why presents by a logarithmic function? Let's see. >为何定出这么两个常数,又为何使用对数函数来表示这个参数,我们来了解一下。
These two formulas follow a same form, i.e.:
这两个式子都遵循同一种基本形式,即:
As you see, it's a logarithmic function, the coefficient k is used to amplify the result, and in logarithmic function, the antilogarithm is monotonically increasing when the base is given. Consider the C is a constant, it means the Memory Size M increasing would causes the connection capacity increasing, this point is well fit to our cognition.
这是个对数函数,系数k用于放大对数部分计算出的数值,而在对数部分,真数是单调递增的。同时考虑到C是常量,则意味着随着内存大小的增加,所允许的最大连接数也随之增加,这十分符合我们的经验认知。
And then let's check a particular value.
If M equals C, the antilogarithm is 1, and the result is 0 whatever the base and the coefficient is, compare to the value of C, it tells us the memory size must greater then 0.75GiB at least, the formula can make sense.
然后我们看一个特殊值的情况。
当M等于C时,真数为1,此时无论底数和系数是多少,算式结果都为0,也就是说,只有实例的内存量在768MB以上时,这个式子才具有意义。
Well, base on the above information we can figure out the function graph as follow:
据此我们可以得出如下函数图像:
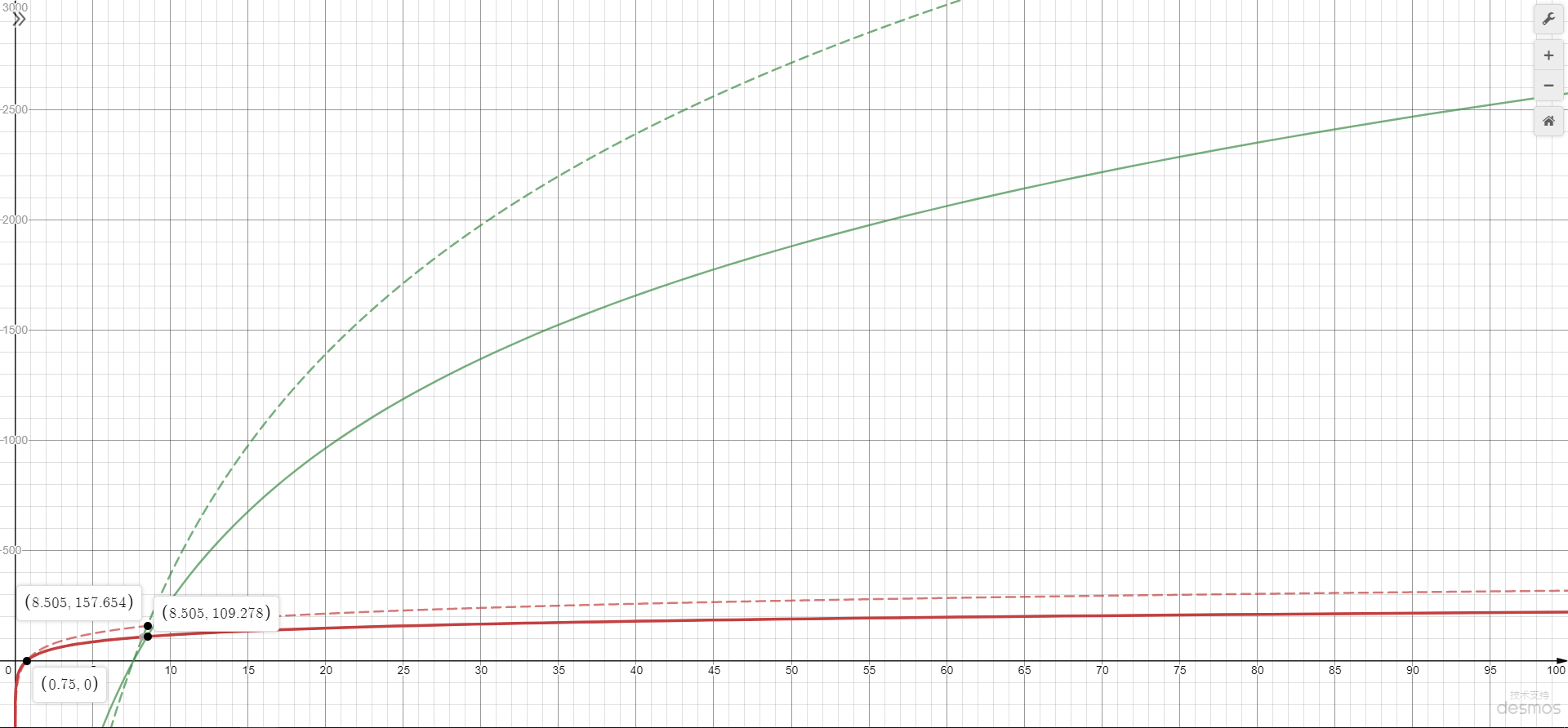
The X-axis is memory size in GiB, and the Y-axis is the calculated max_connections by the formulas, the red line presents the cofficient is 45, and the green line presents the cofficient is 1000, the solid line presents the base is e(2.71828...) and the dash line presents the base is 2. Note that the formula indicates obtaining the relative large number as the result so we can only focus at the higher value in one of the line-type.
X轴是以GiB为单位的内存大小,Y轴是所支持的max_connection计算值;红色线是系数为45的式子,绿色线是系数为1000的式子;实线是底数为自然对数e的式子,虚线是底数为2的式子。留意在原式子中是取较大值作为结果的,所以我们只需要关注一种线性中较靠上(值较高)的部分。
Obviously either solid line or dash line they have an intersection which is on the memory size of 8.5GiB. It means that AWS considers about 8GiB memory is a threshold, when the memory size less than 8GiB and greater than 0.75GiB, the max_connection value just can float between 0 to 109 (e as base) and 0 to 157 (2 as base),
but once over the threshold, the max_connection increasing pretty fast follow the memory size incresing, when the memory size is made double to 16GiB, the max_connection reaches to approximate 750 and 1100 respectively.
Another inherent feature is, the increasing rate is decreased gradually when memory size is increasing linearly, this feature cause by the logarithmic formula.
显然地,无论实现还是虚线都有一个交点,交汇在内存大小大约为8.5GiB处。也就是说,AWS以大约8GiB内存作为运行的临界点,当内存大小小于8GiB但大于0.75GiB时,max_connection的值只介于0到109(以e为底数)和0到157(以2为底数)之间,而一旦内存大小超过8GiB,max_connection的值提升得相当快,当内存大小翻倍达到16GiB时,支持的max_connection就已经分别达到750和1100了。
另一个由对数函数带来的天然特性是,增长的速率会随内存大小的线性增长而逐渐降低。
## 3. The Caculation of Requirements | 需求的计算 How to determine a appropriate max_connection value? Is that AWS default policy suit for my situation? >如何定出适当的max_connection值?AWS给出的默认方案适用于自己的情形吗?
A database typically loaded on a server instance and the server has its native upper limitation of memory size, a portion of memroy is supplied to databse using. And explore the MySQL running principle you may find that the MySQL requires a portion of memory for global running, as well as a portion of memory for query execution thread. Therefrom, each connection needs a certain size of memory. I.e.
So,
通常来说,数据库被一台服务器加载来运行,服务器的内存总量是有上限的,其中一部分内存被提供给数据库使用。再探索MySQL的运行原理,可以发现对于MySQL,一部分内存被用于全局运行,另一部分内存被用于查询的执行线程。故此,每一个连接都会造成使用了一定的内存,即:
得:
The Global Buffers include key_buffer_size, innodb_buffer_pool_size, innodb_log_buffer_size, innodb_additional_mem_pool_size, net_buffer_size, and query_cache_size. And the Thread Buffers include sort_buffer_size, myisam_sort_buffer_size, read_buffer_size, join_buffer_size, read_rnd_buffer_size, and thread_stack. All of the value can be checked by command:
全局缓冲区使用内存包括
key_buffer_size、innodb_buffer_pool_size、innodb_log_buffer_size、innodb_additional_mem_pool_size、net_buffer_size、query_cache_size。单线程缓冲区使用内存包括sort_buffer_size、myisam_sort_buffer_size、read_buffer_size、join_buffer_size、read_rnd_buffer_size、thread_stack。这些值可以用下面的命令获得:
SHOW VARIABLES
WHERE Variable_name LIKE '%buffer_size%'
OR Variable_name LIKE '%pool_size%'
OR Variable_name LIKE '%cache_size%'
OR Variable_name LIKE '%thread_stack%'
In my case, I obtain the values:
在我这边的服务器上,用了上述命令后得到:
| Variable | 变量 | Value | in MiB |
| ----- | ----- | ---- |
|key_buffer_size|16777216|16|
|innodb_buffer_pool_size|1586495488|1513|
|innodb_log_buffer_size|16777216|16|
|innodb_additional_mem_pool_size|N/A|N/A|
|net_buffer_size|N/A|N/A|
|query_cache_size|88158208|84|
|Global Buffers Total | 全局缓冲区使用内存总计|1708208128|1629|
||||
|sort_buffer_size|262144|0.25|
|myisam_sort_buffer_size|8388608|8|
|read_buffer_size|262144|0.25|
|join_buffer_size|262144|0.25|
|read_rnd_buffer_size|524288|0.5|
|thread_stack|262144|0.25|
|Thread Buffers Total | 单线程缓冲区使用内存总计|9961472|9.5|
I.e. each connection would use approximate 10MiB memory in default setting.
即,默认每个连接大约要使用10MiB的内存。
Refer to an actual situation, the following is the measuring of my server, the two lines present writer and reader (read-write separation), the Y-axis value presents free memory size, and each server has 4GiB memory in total.
参考实际情况,下图是我对我所使用的服务器的测定值,两根线分别表示了写入器和读取器,Y轴是空闲内存数量,每台服务器总共有4GiB的内存。
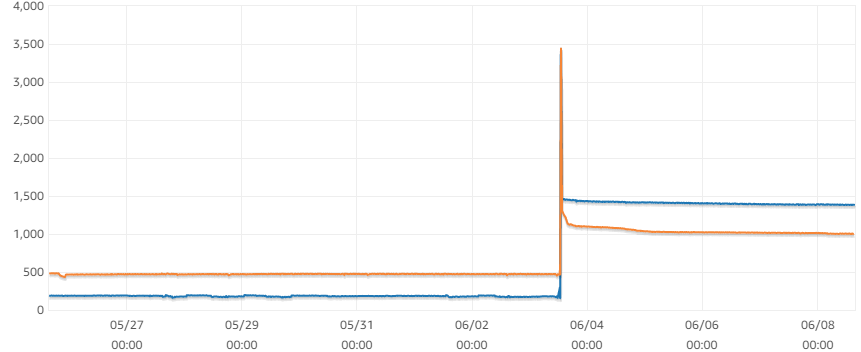
As you see, 1~1.5GiB memory is free, it means approximate 100 connections can be supported, and refer to the Figure 1, the 4GiB or more memory causing result is on 75 or higher max_connections, it is quiet matching between computed result and actual result. This conclution also well explain why AWS design the formula as that.
如图示的,1~1.5GiB的内存是空余内存,也就意味着能支持大约100个连接数,再参考图1,4GiB或更大的内存可以得到大约75或更高的连接数,这个计算值和实际情况是比较符合的,也很好地诠释了为何AWS把max_connection的式子设计成那样。
4. The Adjustment of Parameters | 参数的调节
Return to the logarithmic function basic form:
回到上述对数函数的基本形式:
Note that C is base point to determine how much memory to make the formula making sense. It means if you want to keep more fixed memory size supply for OS or Global Buffers running, you may raise this value, e.g. 1024MiB or upper value then allows the database can accept connection; as well as using the C as a watershed to separate common memory size and very large mempry size.
留意C是作为这个式子是否有意义的基准点而存在的,也就是说如果希望保留更多的固定内存容量来供给OS或全局缓冲区来运行,那么可以上调这个值,比如上调到1024MiB以上数据库才能开始接受连接;同时还可以用作一般内存容量和超大内存容量的分水岭。
Then consider the base n and the coffient k, in logarithmic function, the base presents the approximate rake ratio in a large range when k=1 and y>0, and k amplify this ratio. Therefore, when we hope to adjust the ratio relationship between memory size and max_connections, we may adjust the n and k, the larger n would cause even more memory size the max_connection still keep a relatively tiny increment, then attach the coffient k would make the calculation nearly linear, and vice versa.
然后考虑底数n和系数k,在对数函数中,底数在一个较大范围里当k=0且y>0时近似于表现斜率,而K则放大这个斜率。那么,如果我们希望调整内存与max_connections之间的比例关系,我们可以调节n和k,更大的n值会使得即使内存量增加很多,max_connection也只是增加很少一点,再结合k值,可以使得整个计算值趋于线性,反之亦然。
