hdfs文件导入到hive(带资源)
前言
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行,下面来介绍如何将结构化文档数据导入hive。
一、安装Hive
1.1 官网下载或到本章最后地址下载hive 安装包
/opt/software 下新建hive 目录 并将安装包解压至此
tar -xzvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/software/hive
解压后的 hive 目录结构如下
1.2 添加环境变量
vim /etc/profile
文件末尾加上下面两行 分别为hive安装路径和引用
export HIVE_HOME=/usr/local/hive/apache-hive-3.1.2-bin export PATH=$PATH:$HIVE_HOME/bin
使文件立即生效
source /etc/profile
1.3 进入hive 的jar包目录lib文件夹下
cd /usr/local/hive/apache-hive-3.1.2-bin/lib/
1.3.1 解决 log4j jar 包冲突
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
1.3.2 hive de guava-xx.jar 的guava-xx.jar 和hadoop的guava-xx.jar 包冲突,需要同步高版本jar,并删除低版本jar(两个jar包分别在/opt/hive/lib/ 以及 /opt/hadoop/share/hadoop/common/lib/)
1.3.3 添加mysql 驱动到hive 的 lib下(略)
1.4 修改配置文件
进入到hive安装目录conf下执行
mv hive-env.sh.template hive-env.sh
1.4.1 编辑hive-env.sh 配置hive_home
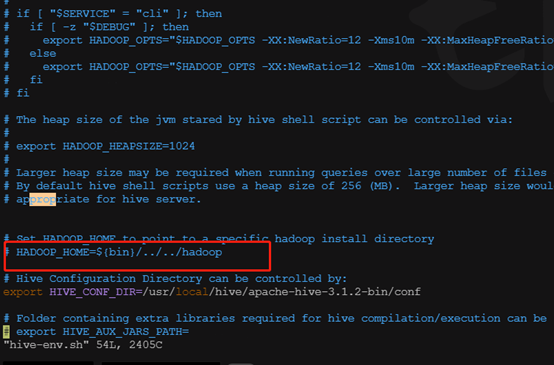
这里注意,如果hadoop和hive 不是安装在同一台机器上,会报错找不到hadoop_home,网上暂时没有找到好方案,暂时只能装在一起,所以这里不用配置
1.4.2 conf文件夹下配置hive-site.xml (如果无该文件,请自行创建 touch hive-site.xml)
<configuration>
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value> </property> <!-- hive的相关HDFS存储路径配置 --> <property> <name>hive.exec.scratchdir</name> <value>/tmp/hive</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.querylog.location</name> <value>/user/hive/log</value> </property> <!-- 以下是mysql相关配置 地址端口自行更改 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://ip:port/testhive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property>
<property> <name>javax.jdo.option.ConnectionUserName</name> <value>userName</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>PASSWORD</value> </property> <!-- hive UI地址,不配置的话,默认只会在本机可以访问 --> <property> <name>hive.server2.thrift.bind.host</name> <value>0.0.0.0</value> </property> </configuration>
1.5 后台启动hiveserver
nohup $HIVE_HOME/bin/hiveserver2 &

1.6 启动hive 自带client
bin/hive
进入hive 客户端

1.7 执行sql测试
hive> create table emp( > id int, > name string); hive> insert into emp values(1,"lisi"); hive> select * from emp; OK 1 lisi Time taken: 0.395 seconds, Fetched: 1 row(s)
正常!
二 、 将hdfs中的文件导入hive
2.1 新建emp表,指定以空格切分字段,以换行切分数据条数
hive> create table student( > id int, > name string) > row format delimited > fields terminated by ' ' > lines terminated by '\n';
2.2 准备要导入的文件
先找到hdfs文件路径
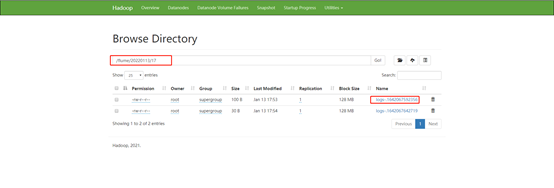
可以在Hadoop(Utilities-Browse the file system)上看到本次要导入的文件路径为 /flume/20220113/13/logs-.1642052912087
2.3 执行导入命令
hive> load data inpath '/flume/20220113/13/logs-.1642052912087' INTO TABLE emp; Loading data to table default.emp OK
执行查询emp语句,可以看到数据以成功导入
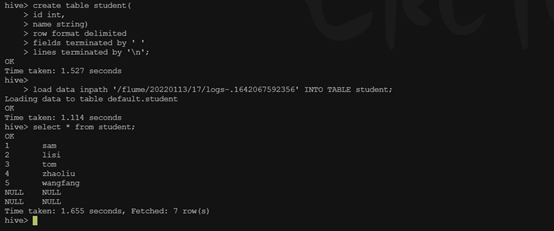
下面为hdfs 源文件(test.log)
1 sam 2 lisi 3 tom 4 zhaoliu 5 wangfang
到hadoop 控制台可以看到hive 的表文件
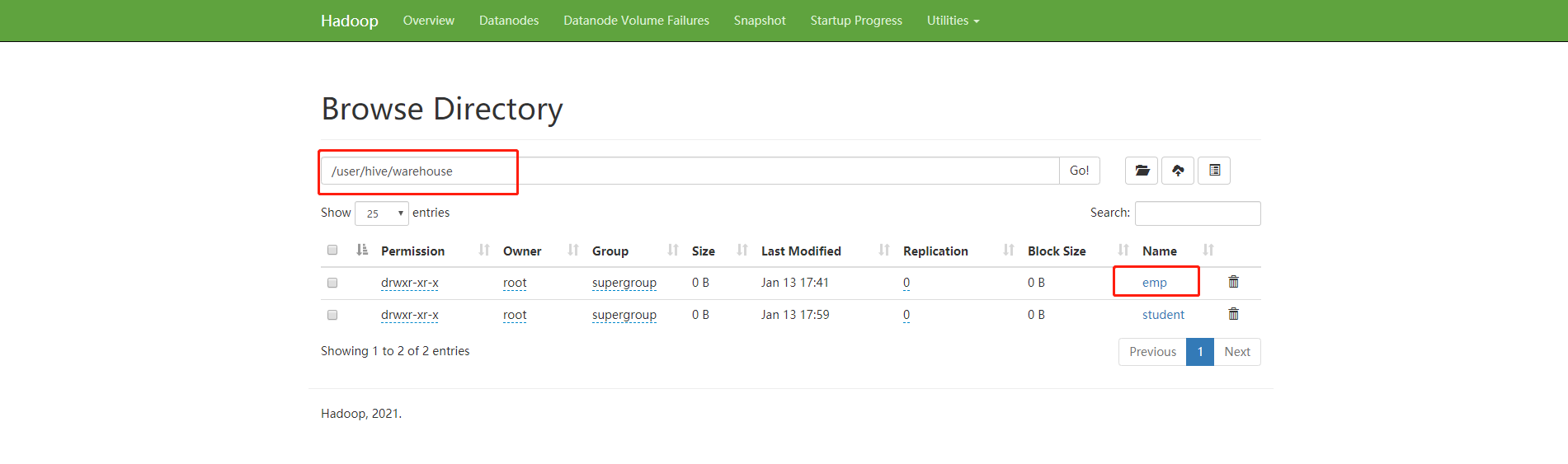
结束!
hive 安装包下载地址
链接:https://pan.baidu.com/s/1CIBq7V6m4yH7TYmI0tacRQ
提取码:6666
!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号